엘라스틱 클라우드에 데이터 추가하기 - 예제 (2025, 06)
Page content
CH03 - 데이터 추가
개요
- Cloud에 데이터 추가
이전 예제 확인
파이썬 코드
# 필요한 라이브러리들을 가져옵니다
import time # 시간 지연을 위한 라이브러리
import requests # HTTP 요청을 위한 라이브러리
from bs4 import BeautifulSoup # HTML 파싱을 위한 라이브러리
from elasticsearch import Elasticsearch # Elasticsearch 클라이언트
# ✅ Elastic Cloud 연결 (API 키 인증 방식)
# Elastic Cloud의 클러스터에 API 키를 사용하여 연결합니다
# API 키는 사용자명/비밀번호 대신 더 안전한 인증 방식입니다
es = Elasticsearch(
"your_cloud_url", # Elastic Cloud 클러스터 URL
api_key="your_api_key" # API 키
)
# 저장할 인덱스 이름을 상수로 정의합니다
INDEX_NAME = "evan-elk-search"
# ✅ 인덱스 생성 (존재하지 않으면 새로 생성)
# Elasticsearch에서 데이터를 저장할 인덱스가 있는지 확인하고, 없으면 새로 생성합니다
if not es.indices.exists(index=INDEX_NAME):
es.indices.create(index=INDEX_NAME) # 새 인덱스 생성
print(f"✅ Index '{INDEX_NAME}' created.")
else:
print(f"✅ Index '{INDEX_NAME}' already exists.")
# ✅ 명언 수집 함수 정의
def get_quotes():
"""
quotes.toscrape.com 웹사이트에서 명언들을 수집하는 함수
Returns:
list: 수집된 명언 요소들의 리스트 (BeautifulSoup 객체들)
"""
res = requests.get("http://quotes.toscrape.com") # 웹사이트에 GET 요청
soup = BeautifulSoup(res.text, "html.parser") # HTML을 파싱
return soup.select(".quote") # .quote 클래스를 가진 요소들을 선택하여 반환
# ✅ 30초 간격으로 명언들을 하나씩 저장
# 수집된 명언들을 가져옵니다
quotes = get_quotes()
# 각 명언을 순회하면서 Elastic Cloud에 저장합니다
for i, q in enumerate(quotes):
# 명언 데이터를 딕셔너리 형태로 구성합니다
doc = {
"text": q.select_one(".text").text.strip(), # 명언 텍스트 추출 (공백 제거)
"author": q.select_one(".author").text.strip(), # 저자 이름 추출 (공백 제거)
"tags": [tag.text for tag in q.select(".tag")] # 태그들을 리스트로 추출
}
# Elastic Cloud에 문서를 저장합니다
res = es.index(index=INDEX_NAME, document=doc)
print(f"[{i+1}] ✅ Saved to Elastic Cloud: {res['_id']}") # 저장된 문서의 ID 출력
# 30초 대기 (다음 명언 저장 전)
time.sleep(30)
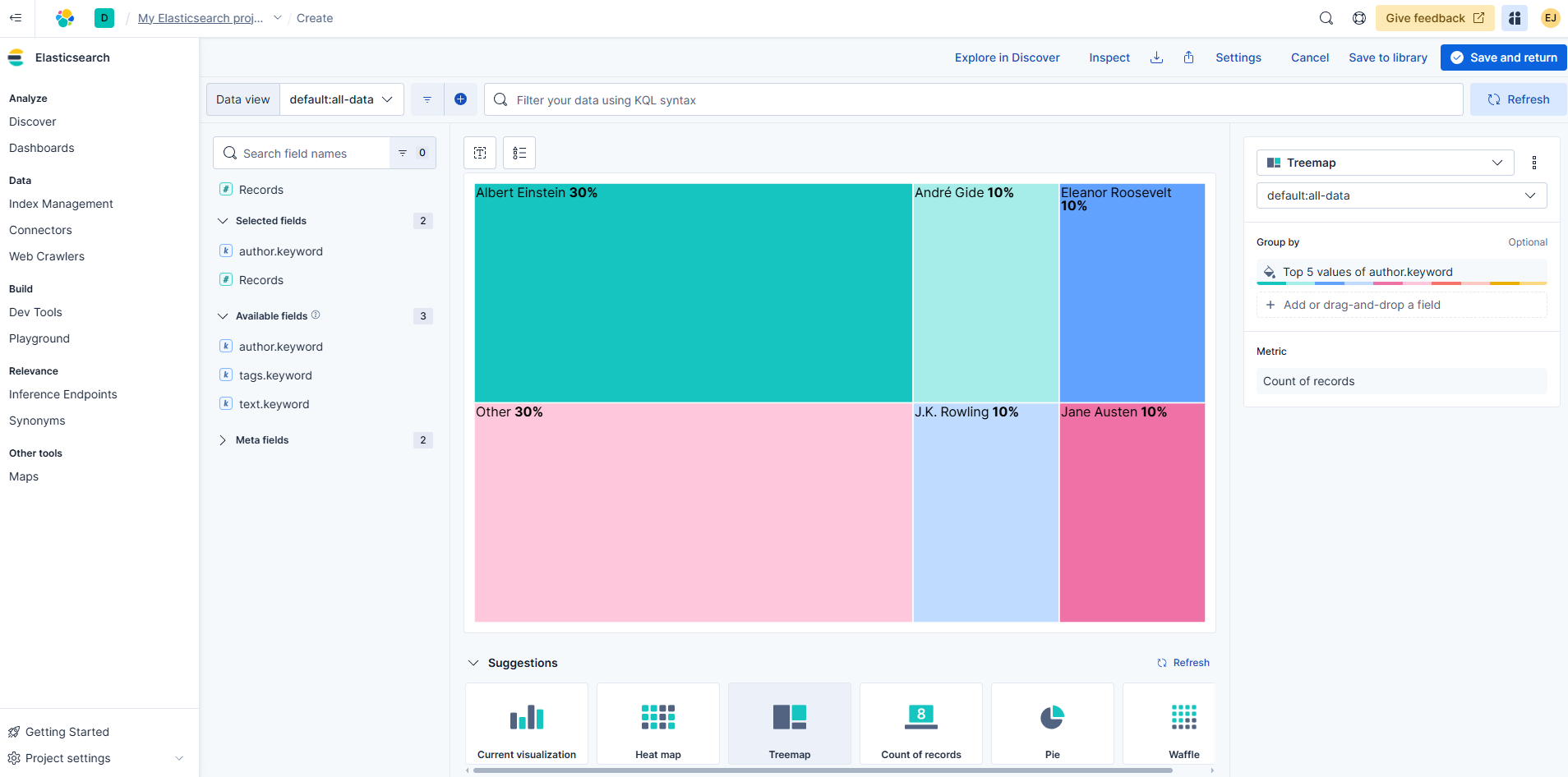
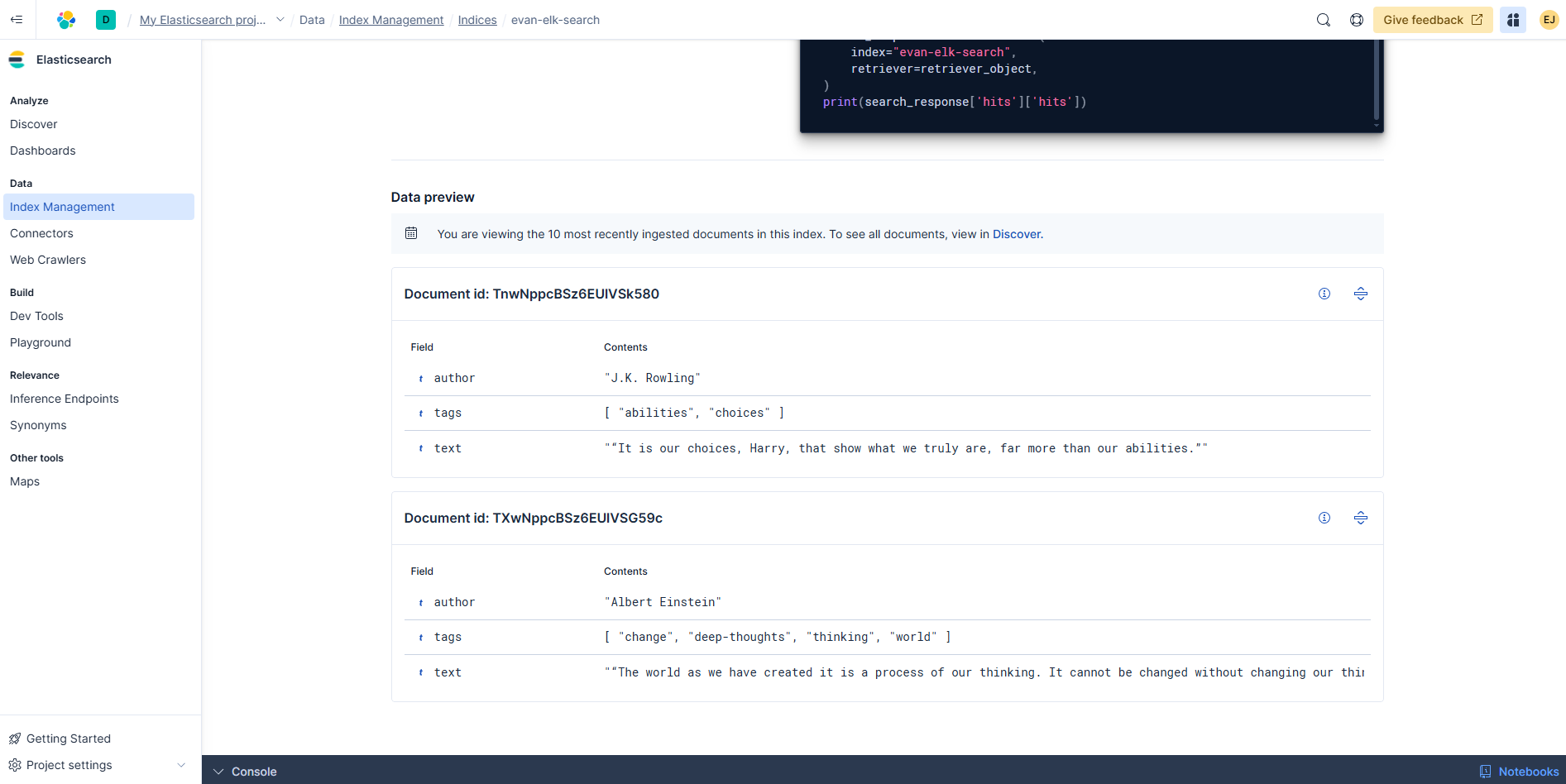
- 클라우드에서 확인
대시보드 확인
- 대시보드 확인하면 다음과 같다.