ch 07 - 데이터 검토
개요
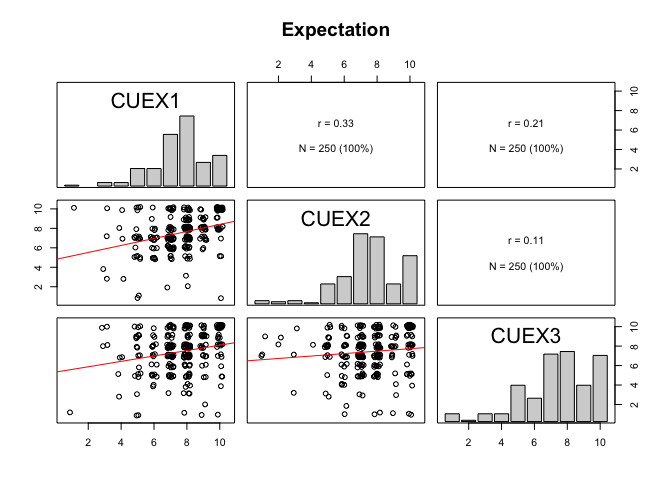
- 수집된 데이터에 대해 정규성 검증을 하는 것은 중요하다.
- 그런데,
CB-SEM과PLS-SEM의 기준 조건은 조금 상이하다.
정규성 분포 확인
Kolmogorov-Smirnov Test또는Shapiro-Wilk Test를 통해서 검증한다.- 귀무가설: 데이터분포를 정규분포를 이룬다,
p-value> 0.05
- 귀무가설: 데이터분포를 정규분포를 이룬다,
- 데이터가 치우쳐 있는 정도를 나타내는 왜도(
skewness: S)와 첨도(Kurtosis: K)를 검토한다.- 첨도와 왜도가 -1보다 작거나 또는 +1 보다 크지 않으면 변수는 정규분포를 하고 있다고 판단한다.
- 그러나, 이 부분은 분석 방법에 대해 조금 상이하다.
- 회귀 분석: 엄밀하게는 2, 관용적으로 3을 사용함. (이일현, 2014)
- SEM: 왜도가 2 이상이고, 첨도가 7 이상이면 비졍규분포로 봄 (West, Finch & Curran, 1995)
결측치
- 설문문항에 의도적으로 혹은 부주의로 하나 이상의 문항에 대한 답을 하지 않았을 때 발생함.
- PLS-SEM에서는 (1) 평균값대체(mean value replacement)와 (2) 사례별 제거 등이 있다.
- 측정변수(지표변수)별로
5% 미만인 경우에는 평균값 대체를,5% 초과시에는 사례별 제거방법을 사용한다. - 사례별 제거 방법은 권장하지 않는다. 설문지가 많으면 상관이 없지만, 대개의 경우 그렇지 못하기 때문에, 가급적이면 삭제는 권장하지 않는다.
- 단, 결측치가 사례별로 15%를 초과하는 경우에는 데이터 파일에서 삭제하는 것이 좋다.
- 측정변수(지표변수)별로
이상치
- 이상치는 특정 설문 혹은 모든 설문에 대한 극단적인 응답값을 말한다.
- 일반적인 기준으로는 표준화 변량값인
Z값과 표준편차가$\pm$ 3 이상인 경우는 극단치에 해당한다. - 마할라노비스 거리 통계량$D^2$을 이용하여 판단할 수 있음. 만약, $D^2$값이 유의수준 0.01보다 작으면 해당 관측변수는 다변량 이상치로 판단할 수 있다.
- 이상치는
PLS-SEM을 시행하기 전에 반드시 확인하고 문제가 되는 응답치가 포함되어 있는 경우네느 데이터 파일에서 삭제해야 한다. - 가장 일반적인 경우는 이상치가 소수인 경우로 이 때는 해당 이상치를 데이터 파일에서 제거한다.
- 영향력이 큰 이상치가 있는 경우에는
PLS-SEM에서OLS회귀에 영향을 미치기 때문에 면밀한 검토와 평가가 필요하며 조치해야 한다.
- 일반적인 기준으로는 표준화 변량값인
다중공선성
- 측정변수(지표)들 간에
다중공선성(Multicollinearity)가 있는지를 확인한다. - 완벽한 공선성(
Collinearity)가 나타나는 경우는 거의 없으며 일반적으로 높은 공선성이 나타난다. SmartPLS에서는 분산팽창인자(Variance Inflation Factor: VIF)를 이용하여 평가한다.- 모든 측정변수에 대해
VIF값이 임계치인 5보다 작으면 공선성은 존재하지 않는다. VIF값이 5 이상인 경우 잠재적인 공선성 문제(Collinearity Problem)를 지니게 된다.
- 모든 측정변수에 대해
PLS-SEM vs. CB-SEM
PLS-SEM과CB-SEM의 차이점은 아래와 같이 서술 할 수 있다.
| 구분 | PLS-SEM | CB-SEM |
|---|---|---|
| 사용목적 | 예측 | 이론 검증 |
| 표본 수 | 30-100개 가능 | 200-800개 |
| 데이터 파일 | CSV 파일 | 모든 파일 가능 |
| 분포 가정 | 분포 가정이 없음, 비모수적 기법 | 엄격한 분포 가정(다변량 정규성이 있어야 함) |
| 모델 복잡성 | 수백 개의 측정 변수 있어도 가능 | 측정변수의 수가 100개 미만 |
| 잠재변수당 측정변수 의 수 | 1개 이상 | 3~4개 이상 |
| 반영적 지표 + 형성적 지표 | 매우 용이(모두 사용) | 주로 반영적 지표 사용 |
| 반영적 지표 + 형성적 지표 | 매우 용이(모두 사용) | 주로 반영적 지표 사용 |
| 모델 적합도 | 모델 적합도 보고 없음 | 상세한 모델 적합도 보고 필요 |
| 오차항의 고려 | 모델 구축 시 오차항(측정오차와 구조 오차)를 표시하지 않음 | 오차항(측정오차와 구조오차)을 모델 구축 시 표시함 |
| 재귀모델과 비재귀모델 | 재귀모델(일방향 인과관계)만 가능 | 재귀모델과 비재귀모델 가능 |
| 잠재변수 산출 | 잠재변수 점수의 산출 가능, 이 점수를 후속연구에 사용 | 잠재변수 점수의 직접적인 추정이 불가능 |
| 모델 평가 | 측정모델과 구조모델 동시에 설정하고 평가(동시분석법) | 측정모델을 이용해 개별 측정변수와 잠재변수의 신뢰도와 타당도를 분석한 후 구조모델을 통해 가설검증을 시행 (2단계 분석법) |
Reference
신건권. (2018). 석박사학위 및 학술논문 작성 중심의 SmartPLS 3.0 구조방정식모델링. 서울: 청람.