AWS EC2 Connect to S3, Streamlit Web (2025 june)
Page content
개요
- EC2 접속을 할 수 있다.
- EC2에서 개발환경 설정을 할 수 있다.
회원가입
- 링크 : https://aws.amazon.com/console/
- 아래 화면, 우측 상단을 보면 English를 Korean으로 변경

- 아래 화면에서 AWS 계정 생성 버튼 클릭
- 회원가입 진행
- 재 로그인
IAM user sign in
- Account ID : 12자리 숫자로 AWS 계정을 식별하는 고유 값이다. 같은 회사라도 계정마다 ID가 다르다.
- IAM User : 각 IAM User는 별도 패스워드·액세스키를 갖고, 정책으로 권한을 제한
- Sign In 가입

EC2 생성
- EC2 검색 및 클릭
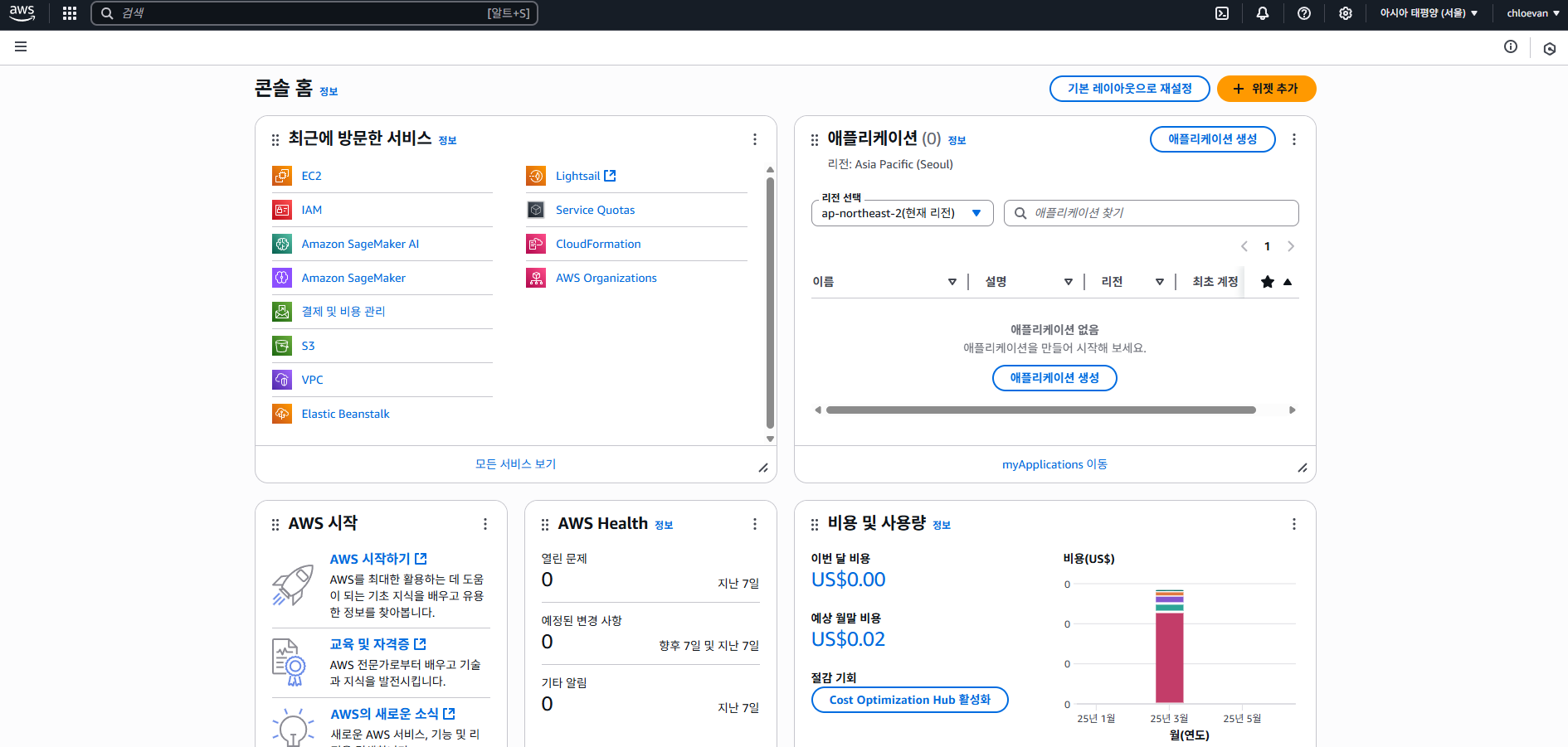
인스턴스 시작
- 화면 가운데 인스턴스 시작 버튼 클
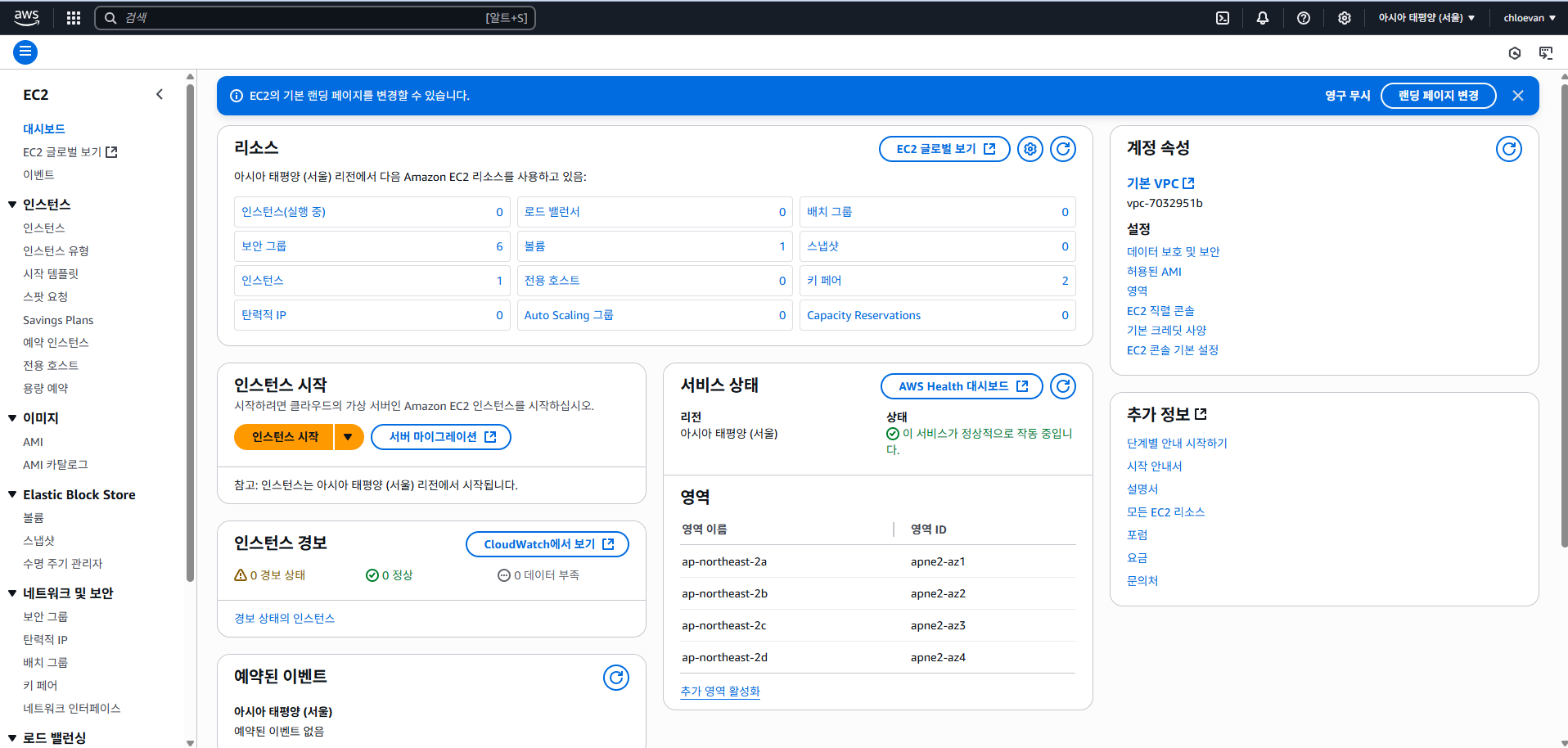
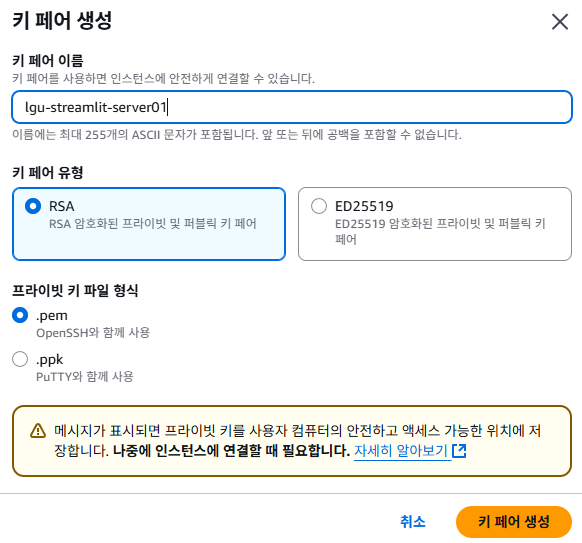
- 이름 : lgu-streamlit-server01
- Ubuntu 설정

- OS 이미지는 기본값 적용
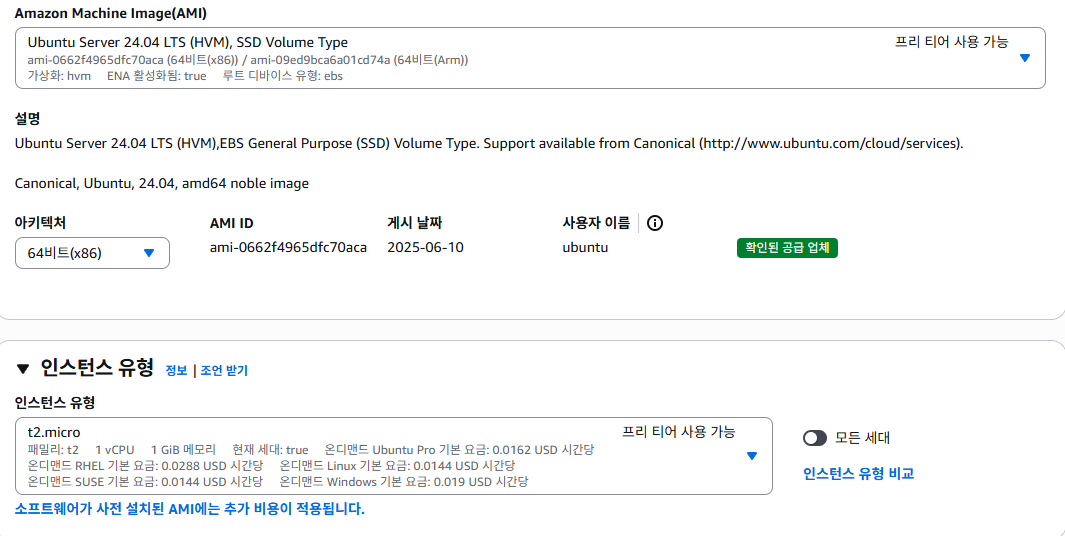
- 새 키 페어 생성
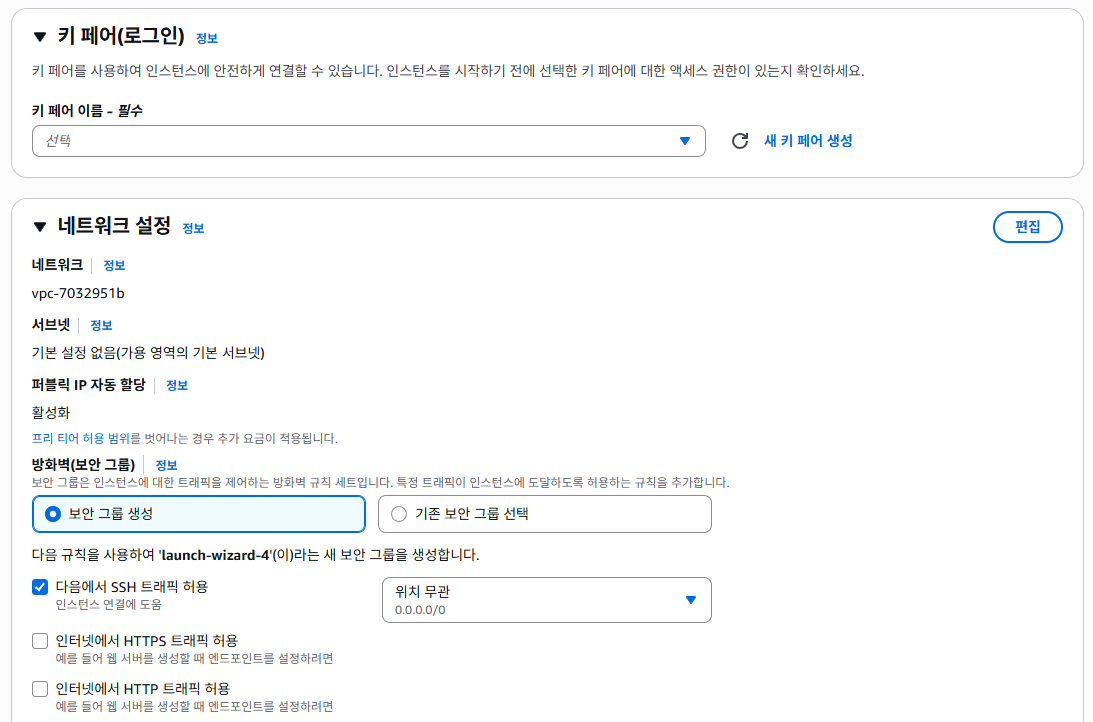
- 키 페어 이름 : lgu-streamlit-server01
- 키 페어 생성 버튼 클릭 시, 프로젝트 경로에 위치 시킬 것
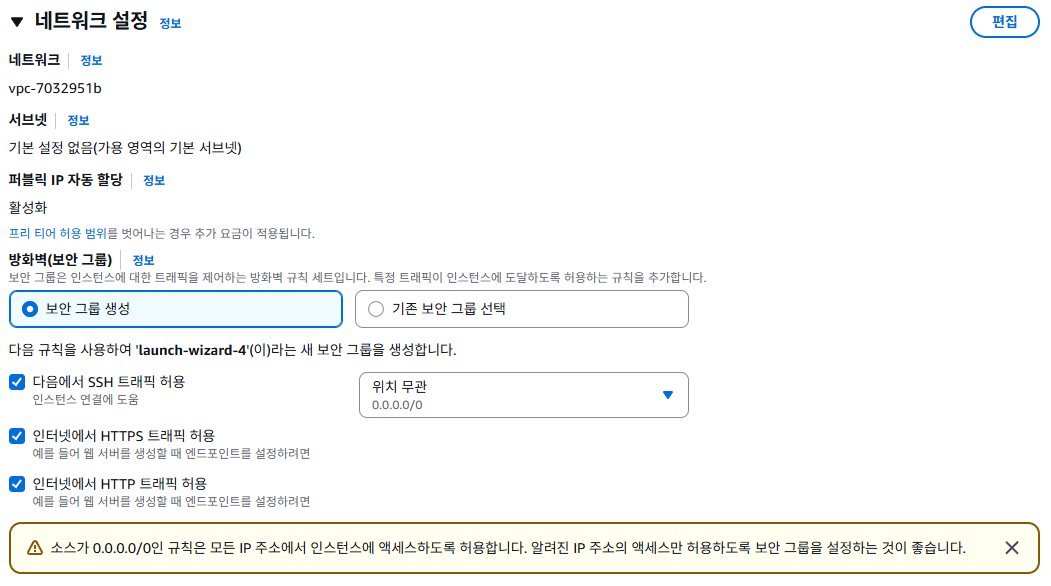
- 네트워크 설정
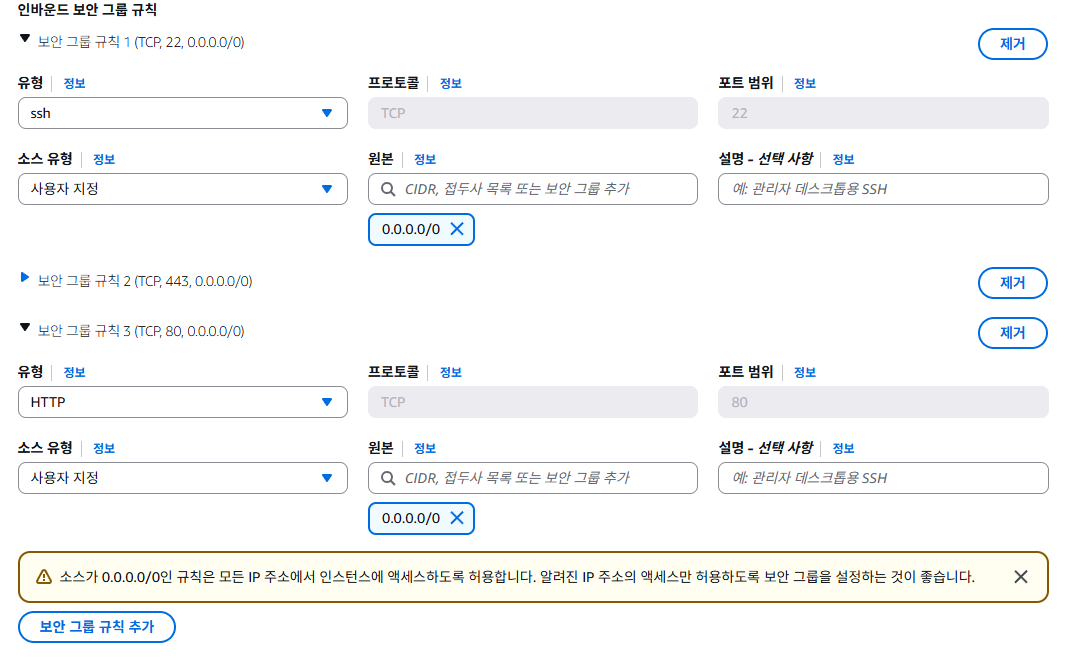
- 위 그림에서 편집 선택 및 다음과 같이 설정 (인바운드 보안 그룹 규칙)
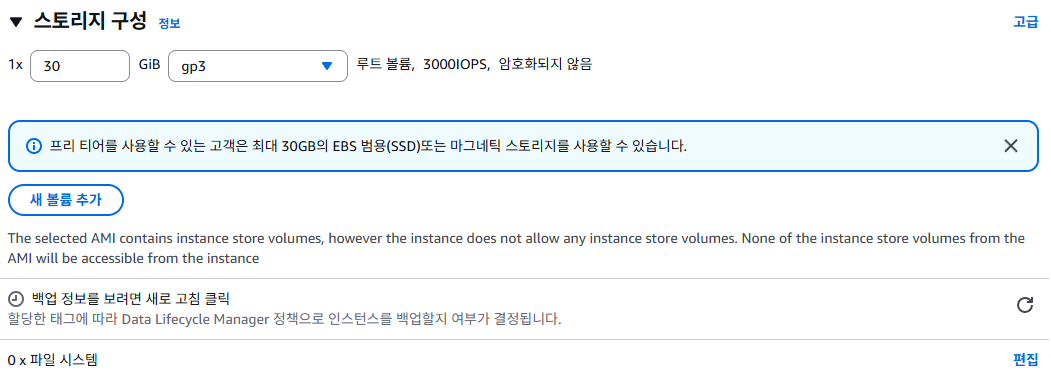
- 스토리지 구성은 30GiB 정도로 진행
- 최종적으로 인스턴스 시작 버튼 클릭
- 다음과 같은 화면에서 인스턴스에 연결버튼 클릭
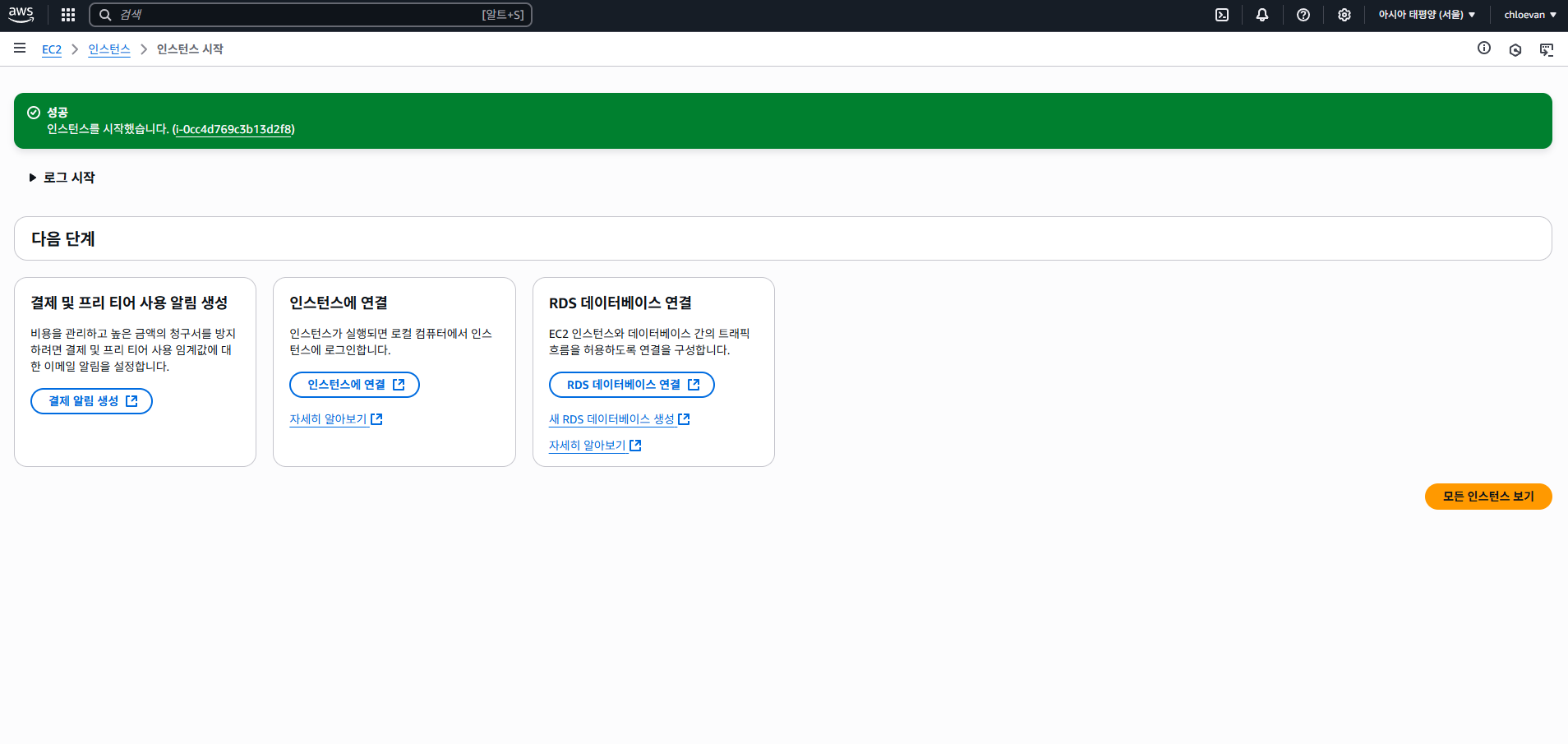
- EC2 인스턴스에 연결 탭에서 연결 버튼 클릭
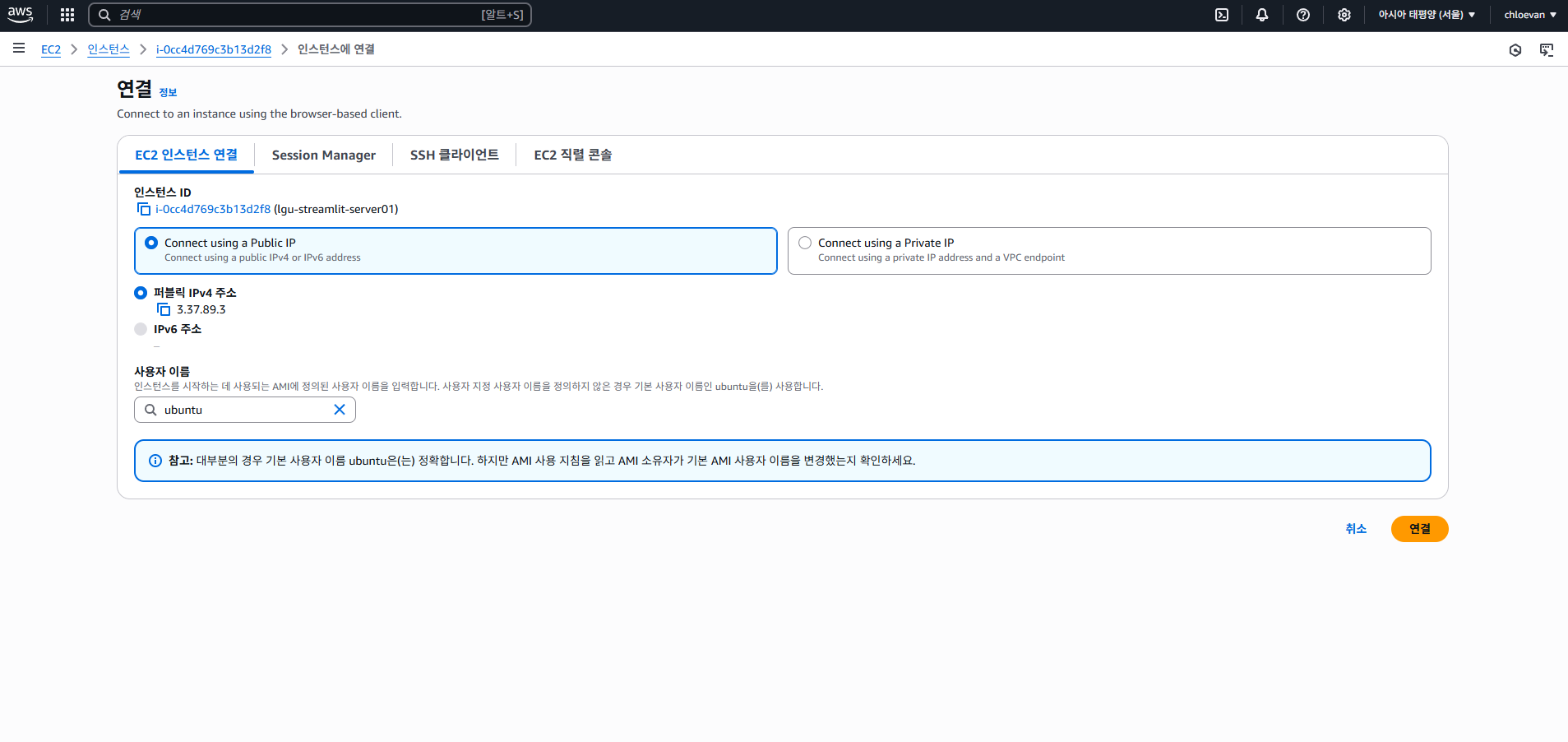
- SSH 클라이언트 탭 클릭
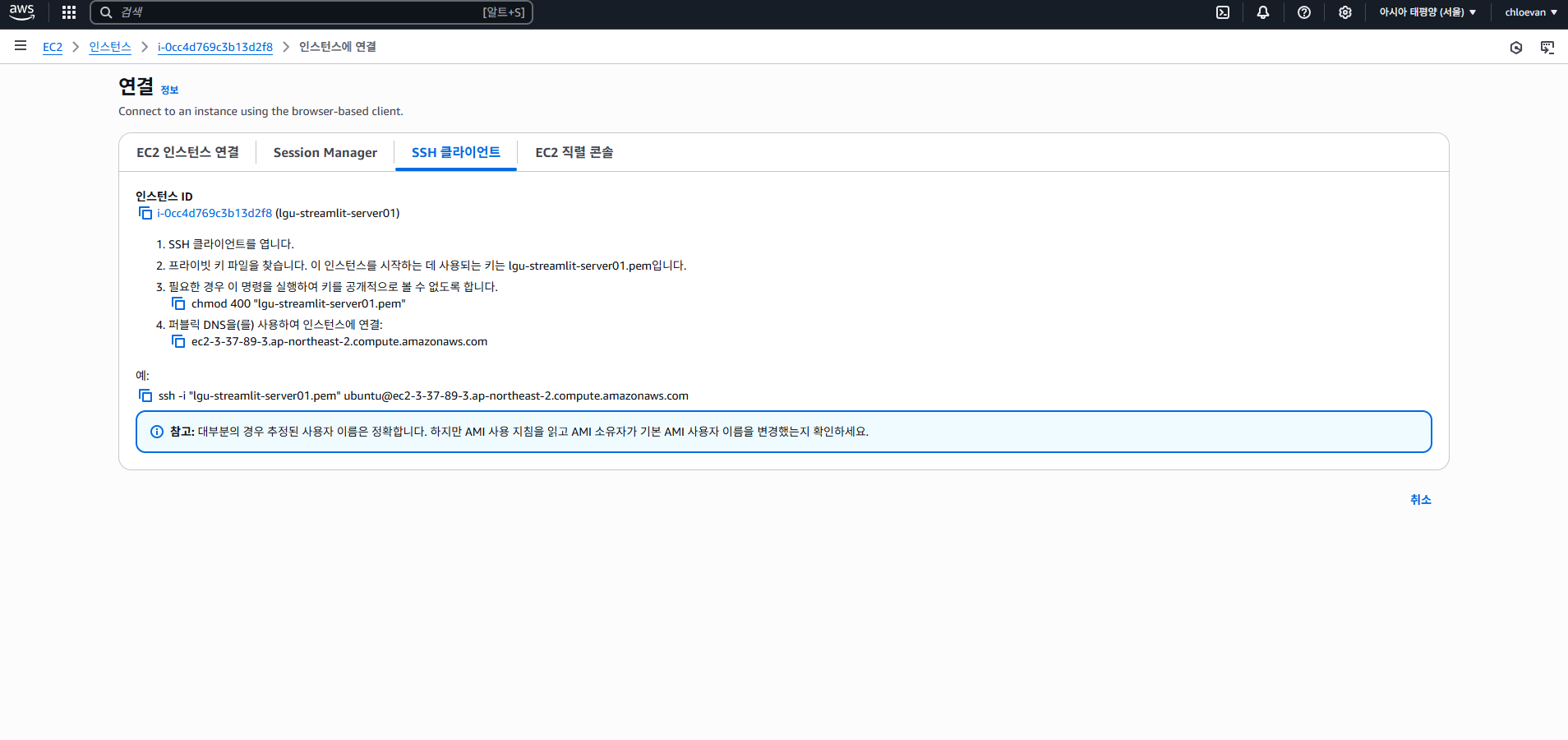
- VS Code에서 Extension 패키지인 Remote SSH 활용 할 것임
VS Code에서 Remote 접속
- 단축키 Shift+Ctrl+P, “>REMOTE SSH CONNECT TO HOST”
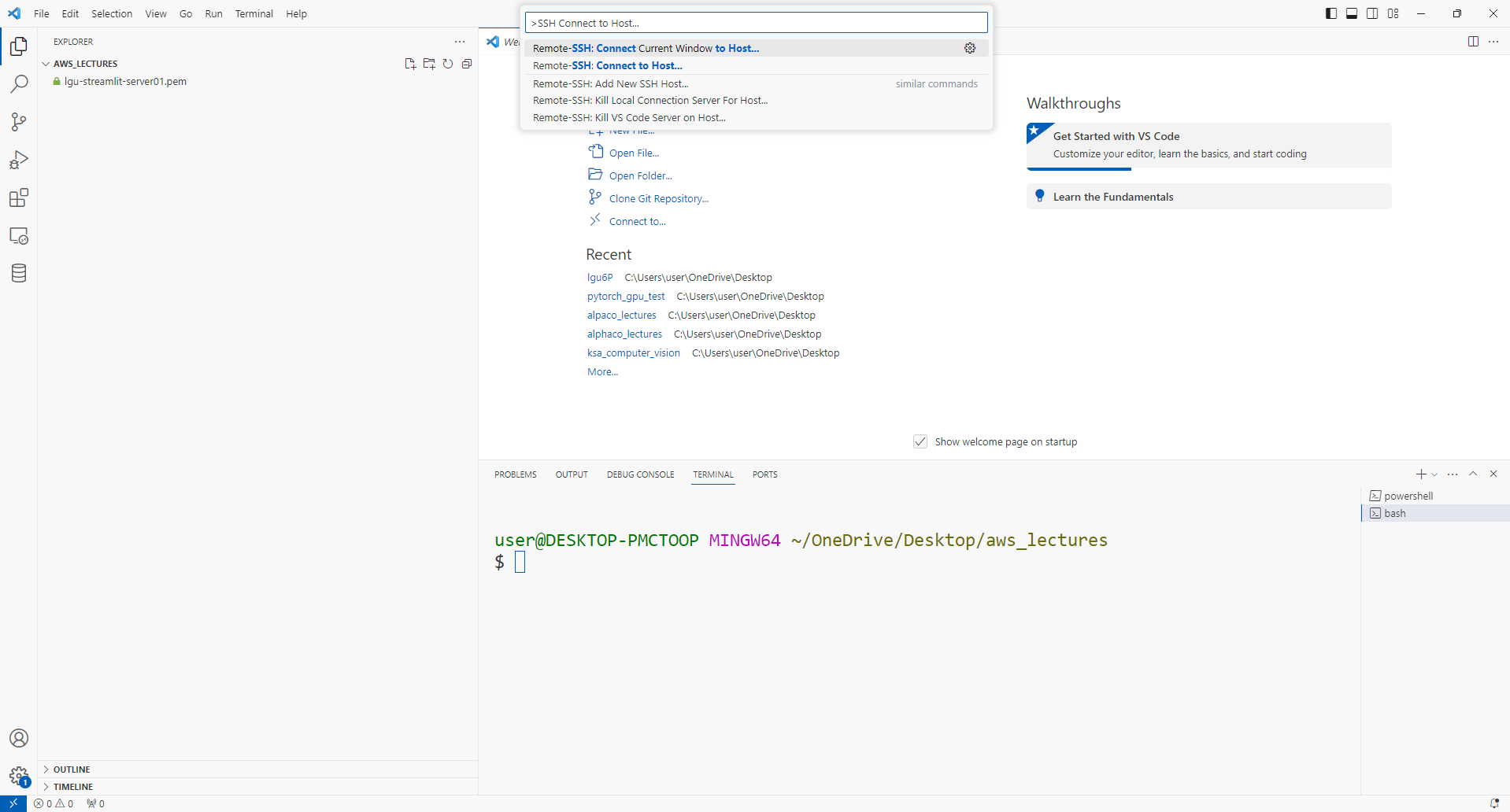
- Configure SSH Hosts 선택

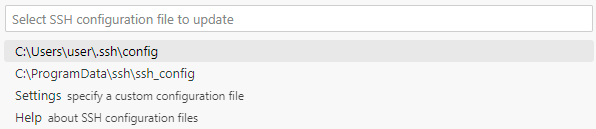
- C:\User\user.ssh\config 선택
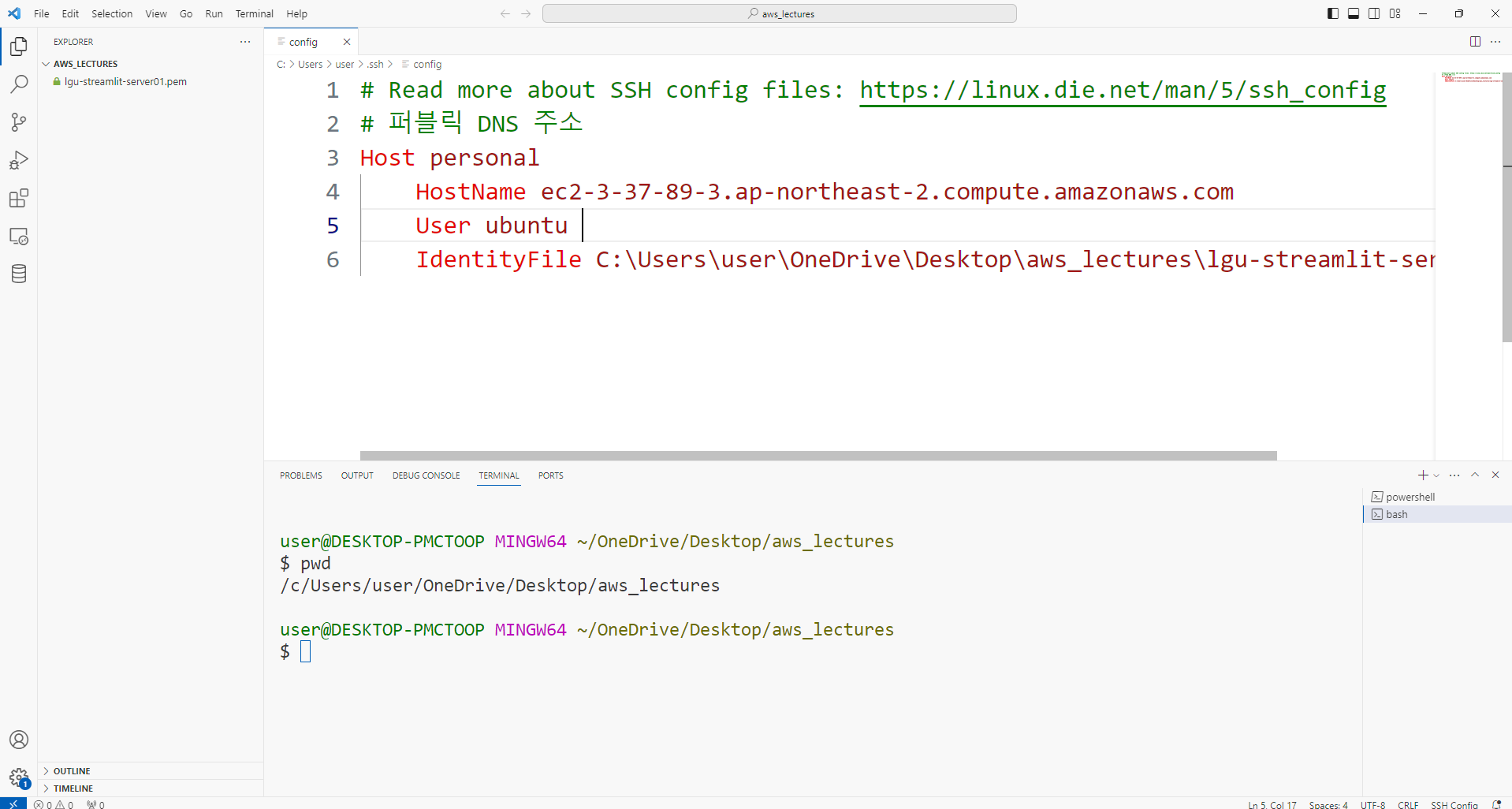
- 다음과 같이 입력
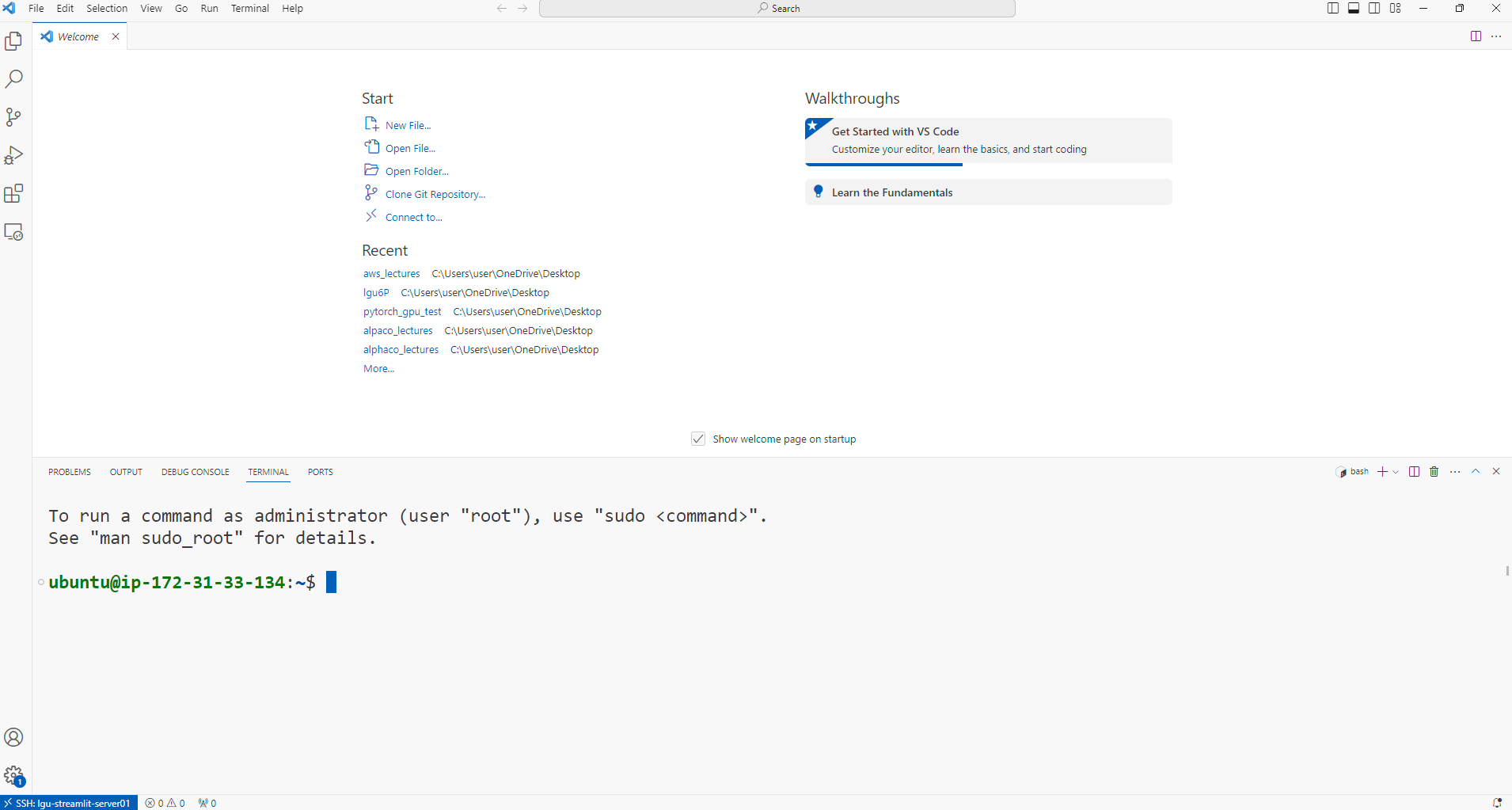
- 연결버튼 클릭
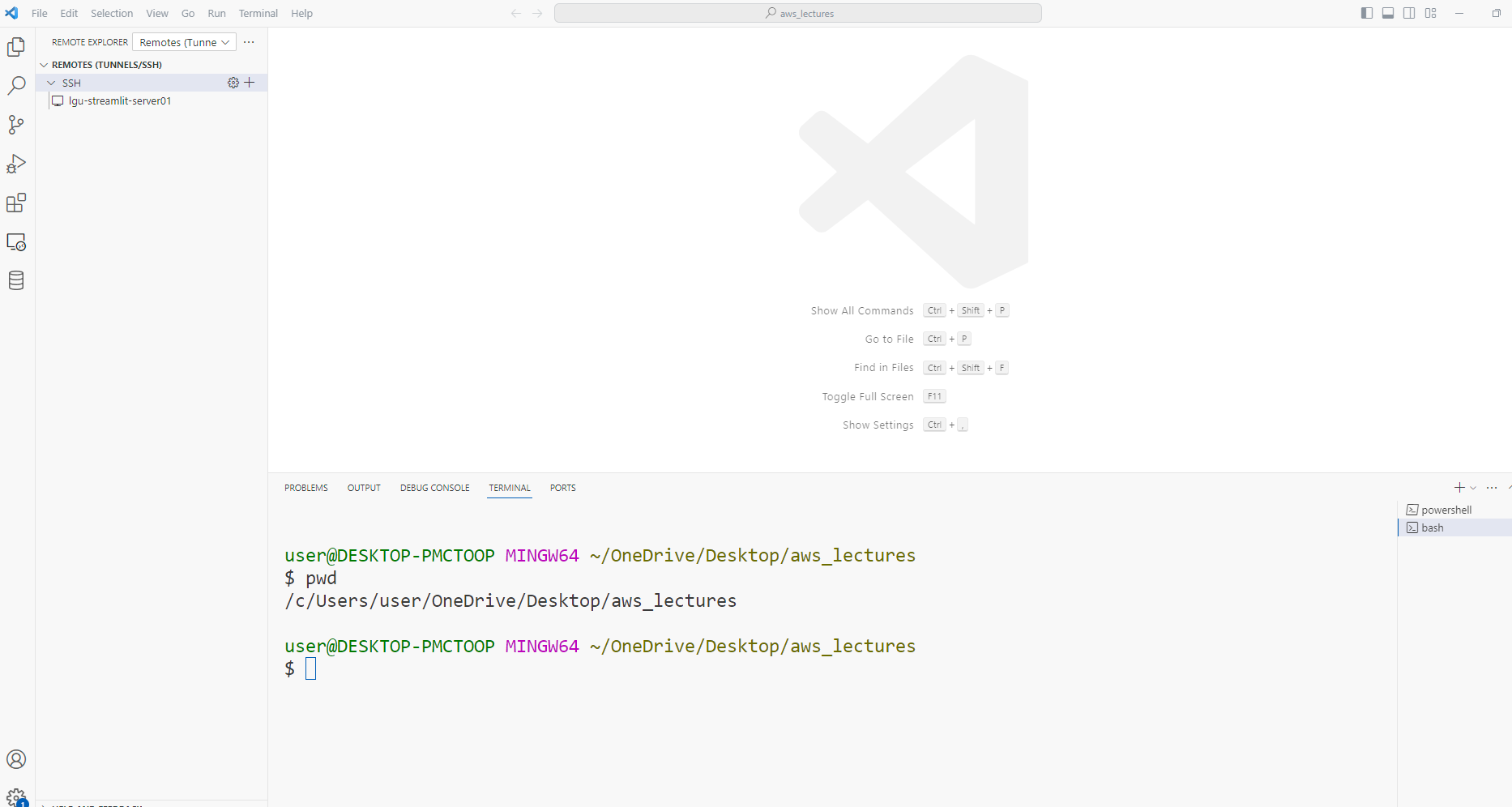
- 연결 확인
리눅스 설정
- 주요 패키지 업데이트
sudo apt update && sudo apt upgrade -y
sudo su
sudo apt install -y build-essential curl wget git vim unzip zip htop tree net-tools
웹 확인
- nginx 설치
sudo apt update && sudo apt install -y nginx
- 서비스 설정
sudo systemctl start nginx
sudo systemctl enable nginx
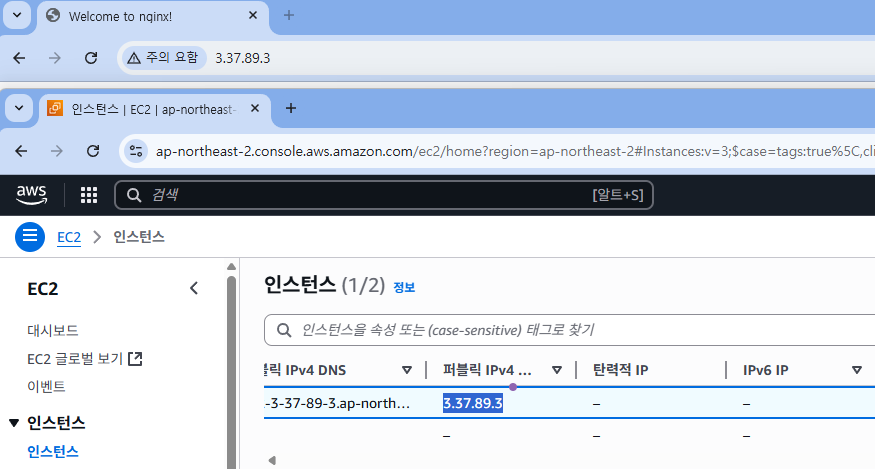
- 인스턴스에서 Public IP 확인
파이썬 개발환경 설정
- uv 설치 및 환경변수 설정, 기존 bash 터미널 삭제, 새로 시작하기
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
- 임시 프로젝트 폴더 설치 (향후 Git 연동해서 Github에서 직접 가져오기)
- temp 폴더에 쓰기 권한 부여
mkdir temp
cd temp
sudo chown -R ubuntu:ubuntu /home/ubuntu/temp
- 파이썬 3.11 개발 명령어
uv venv --python 3.11
Streamlit 대시보드 & Jupyter Lab 설치
- 먼저 requirements.txt 파일 만들기
streamlit
jupyterlab
- 가상환경 접속
source .venv/bin/activate
- 라이브러리 설치
uv pip install -r requirements.txt
테스트
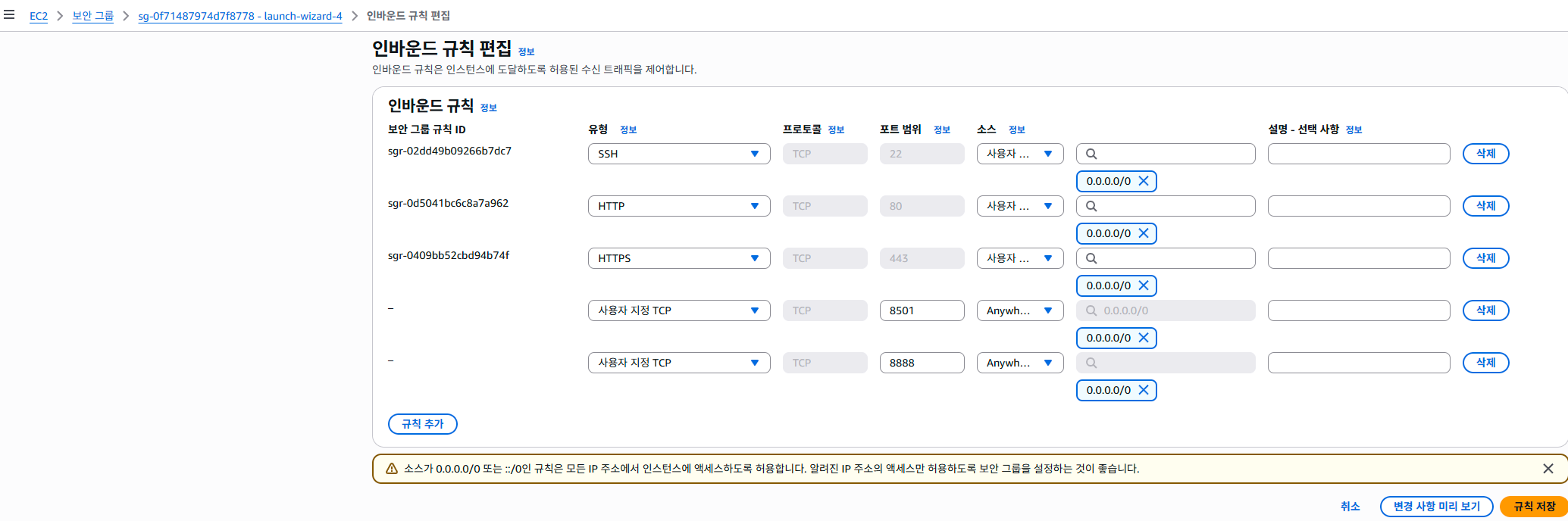
인바운드 규칙편집 변경
- 각 유일값 포트 번호 지정해야 함
Streamlit
- app.py 파일 하나 만들고 실행
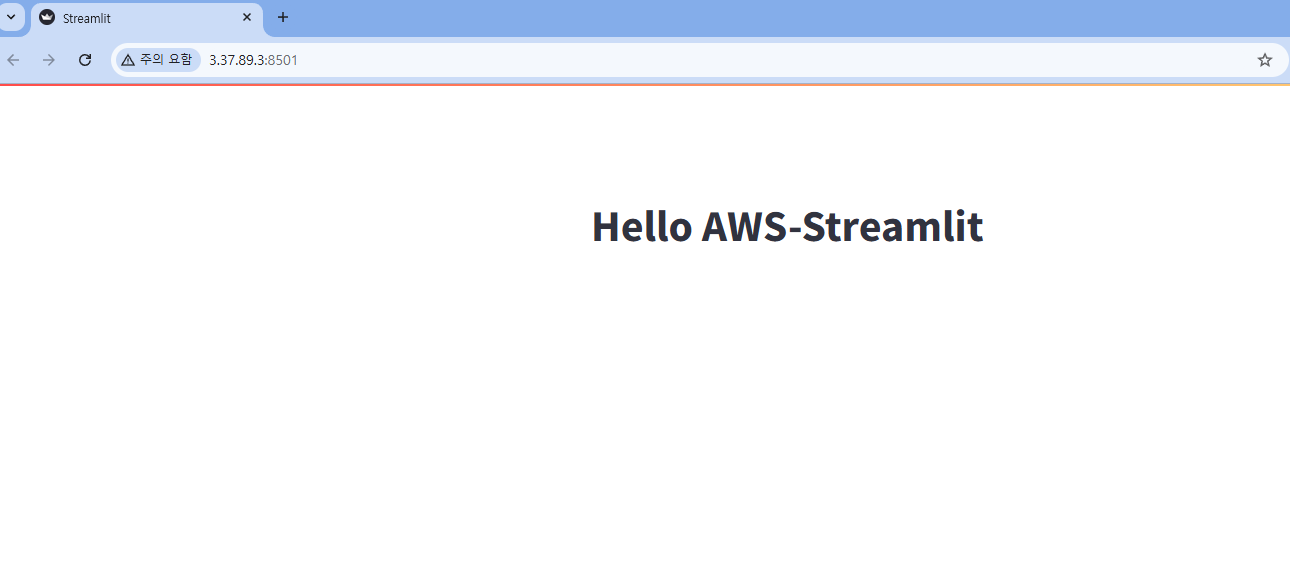
import streamlit as st
st.title("Hello AWS-Streamlit")
- 실행
(temp) ubuntu@ip-172-31-33-134:~/temp$ streamlit run app.py
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.31.33.134:8501
External URL: http://3.37.89.3:8501
Jupyterlab 확인
- 다음 명령어 실행해서 확인
- http://3.37.89.3:8888/lab
jupyter lab --ip=0.0.0.0 --port=8888 --allow-root
- 토큰 값 복사해서 붙여 넣기
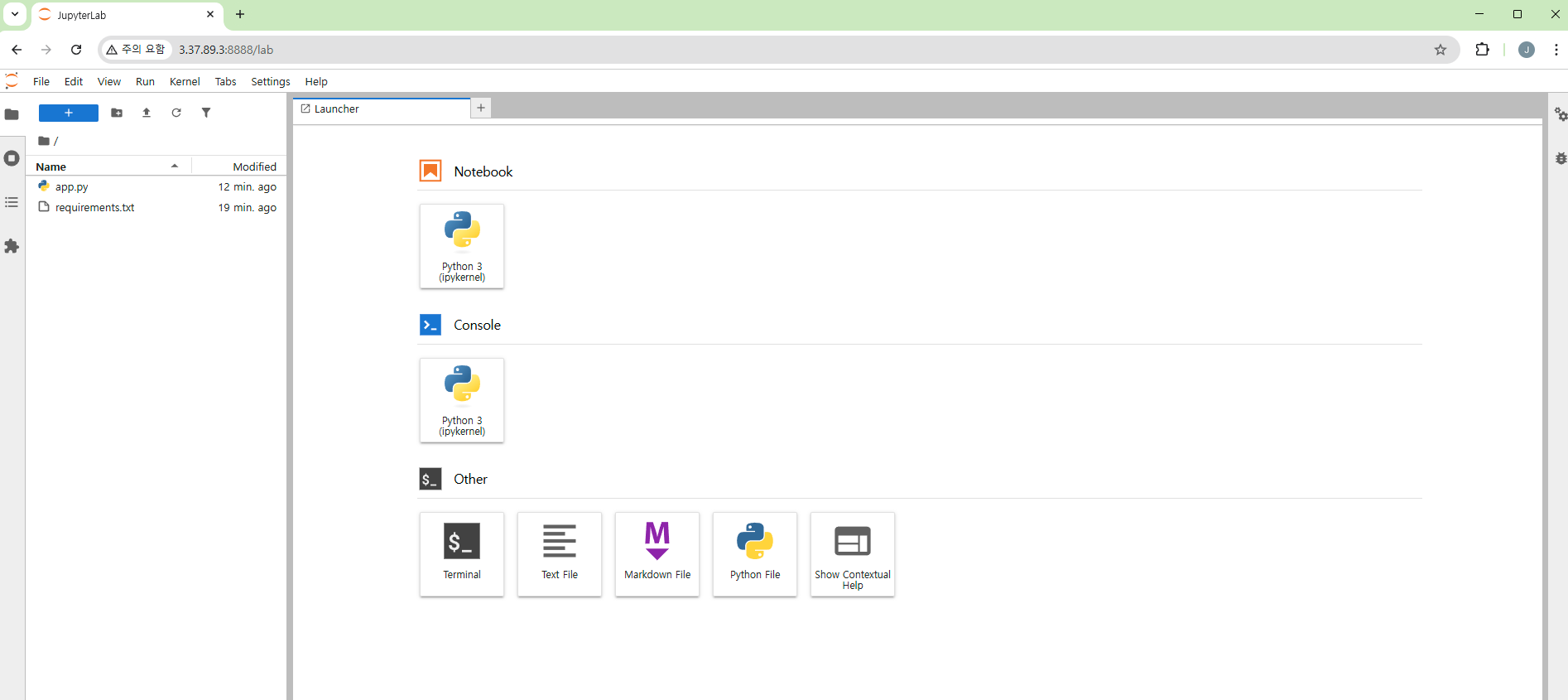
탄력적 IP 할당
- 지금까지 한 것은 중지 시킨 후, 재시작하면 IP가 변경된다.
- 네트워크 및 보안 > 탄력적 IP 클릭 > 탄력적 IP 주소 할당 선택
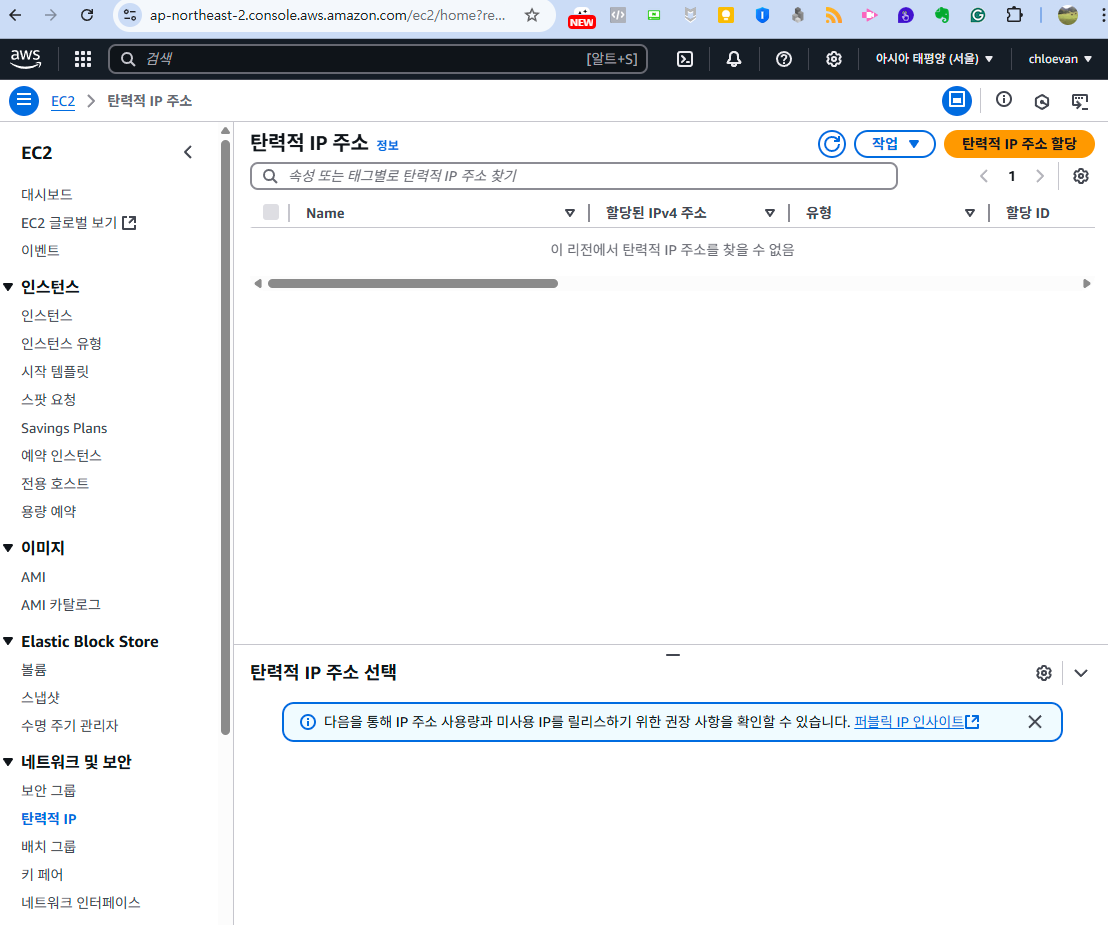
- 아래 그림에서 할당 버튼 클릭
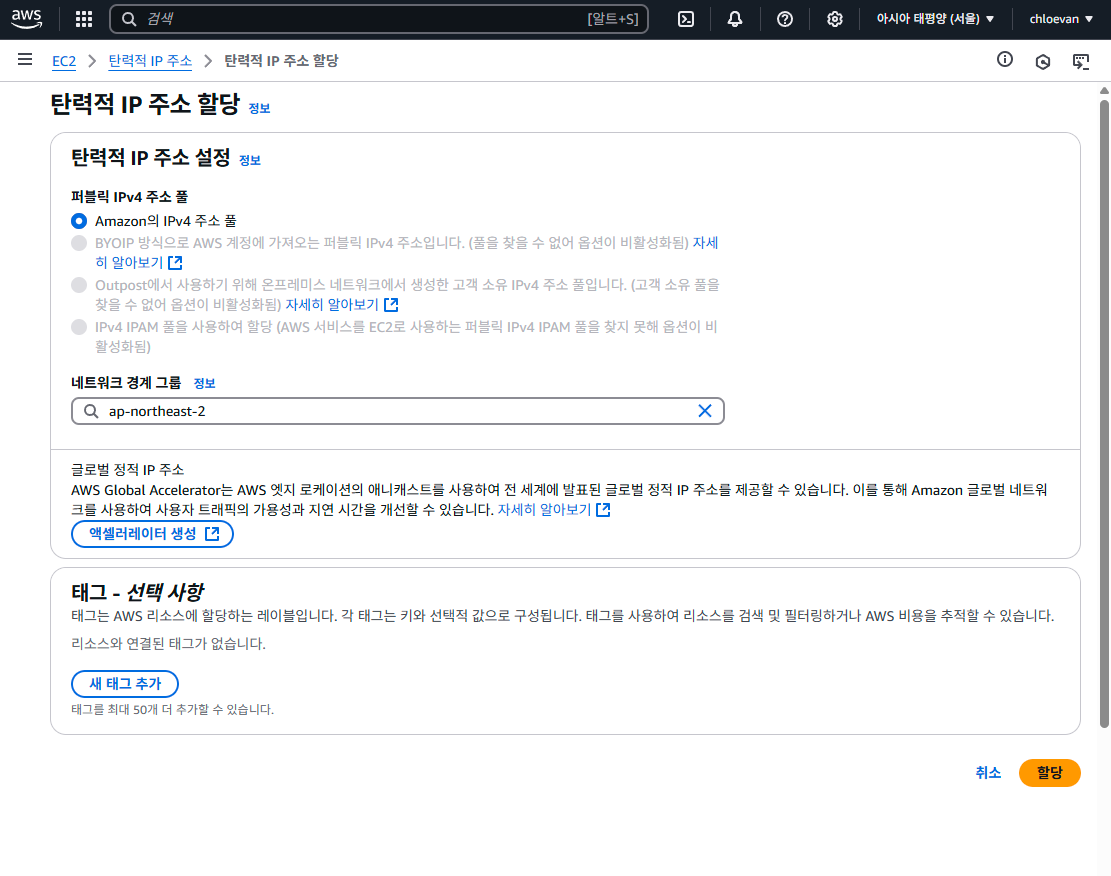
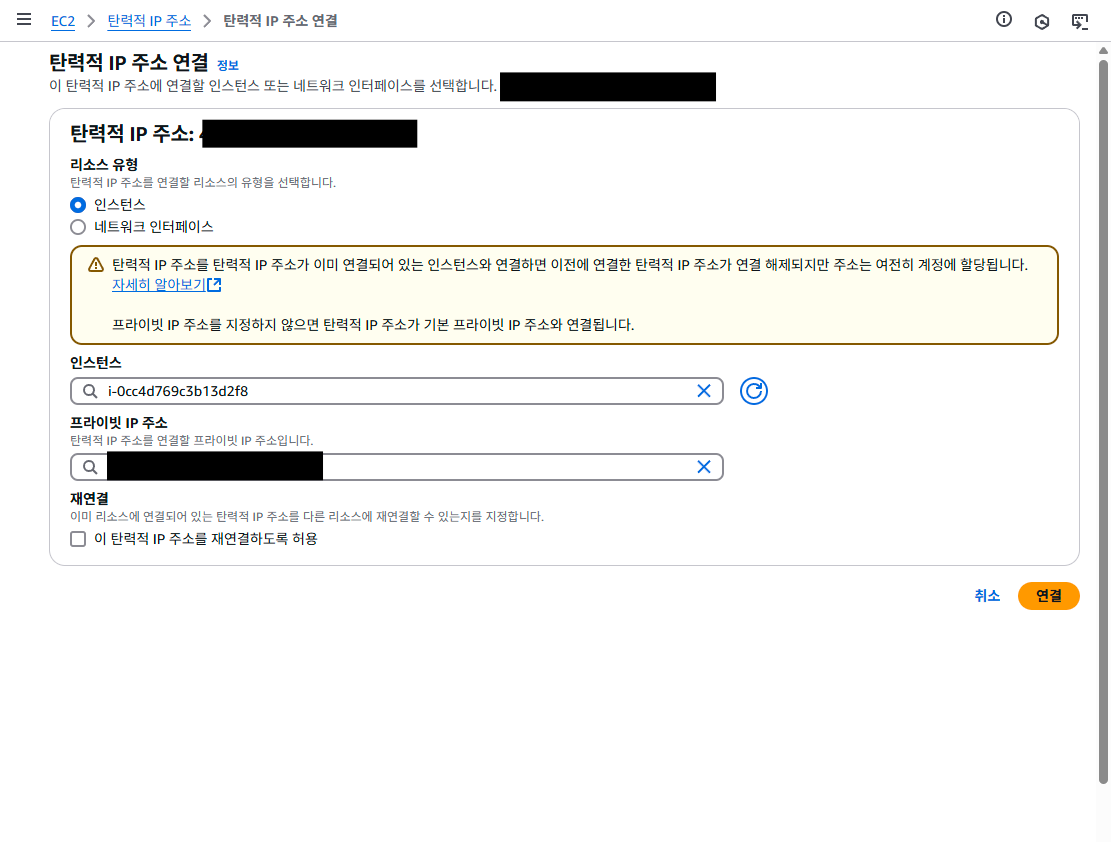
- 할당된 탄력적 IP 주소 선택, “작업” 버튼 클릭 > 탄력적 IP 주소 연결 선택
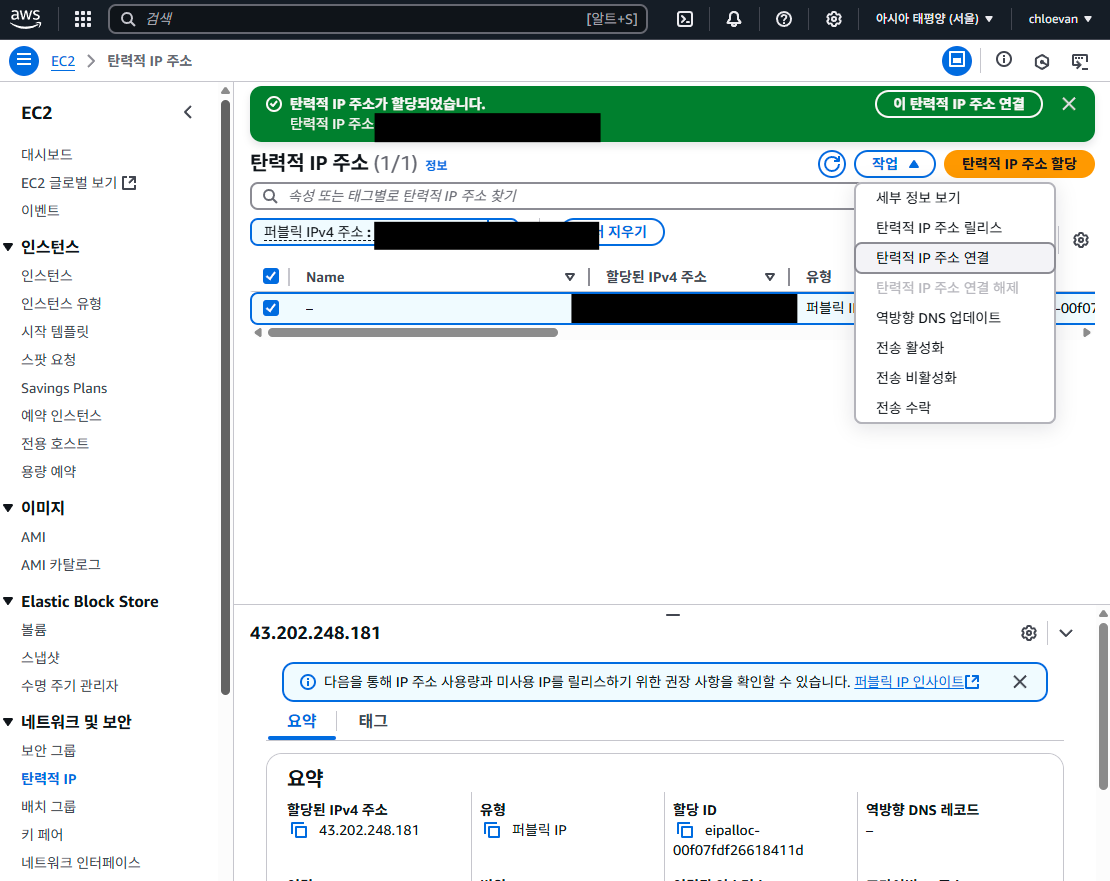
- 다음 그림과 같이 연결 후 연결 버튼 클릭
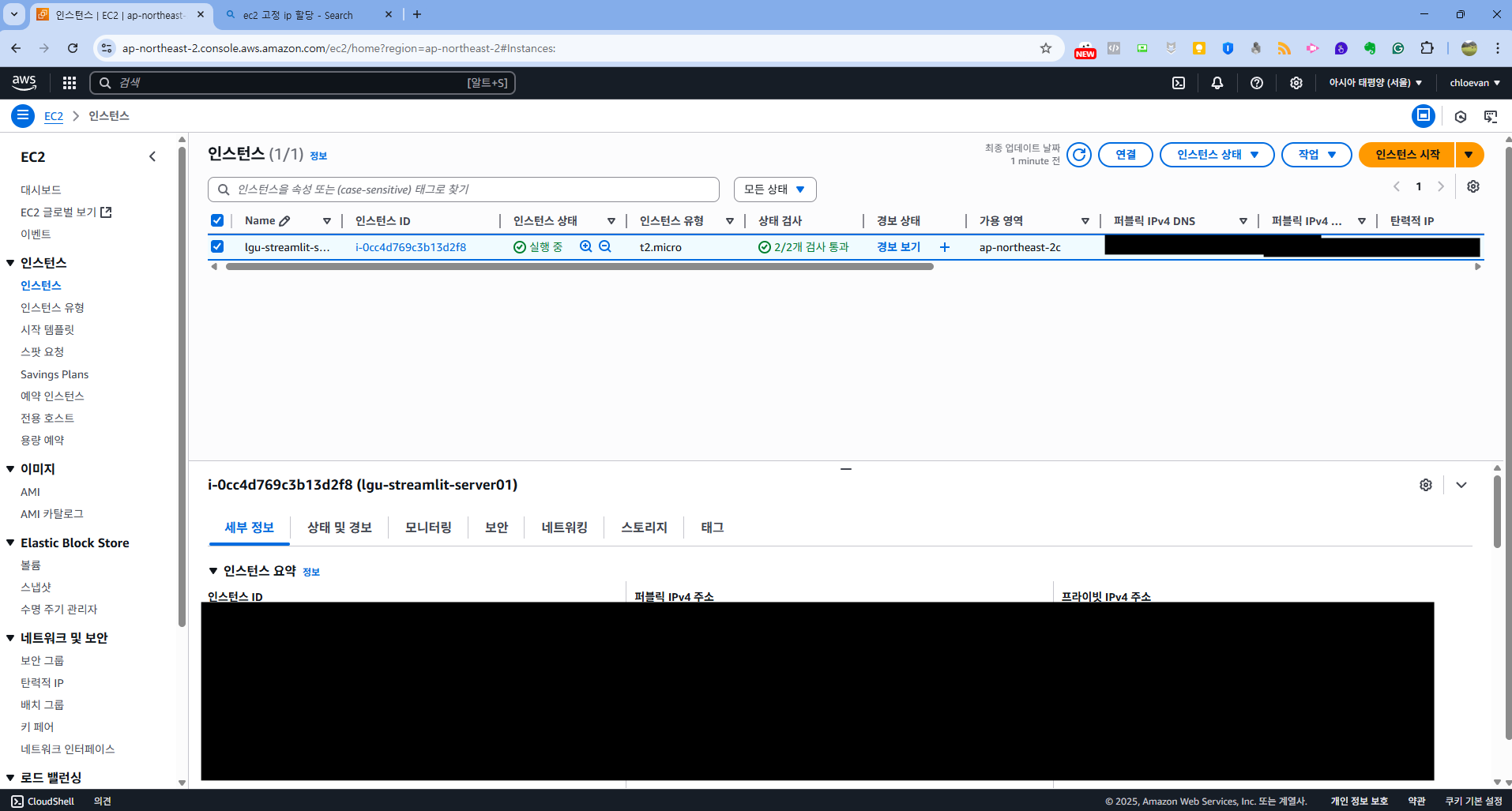
- 인스턴스 확인 해서 탄력적 IP가 제대로 할당되었는지 확인
VS Code 변경
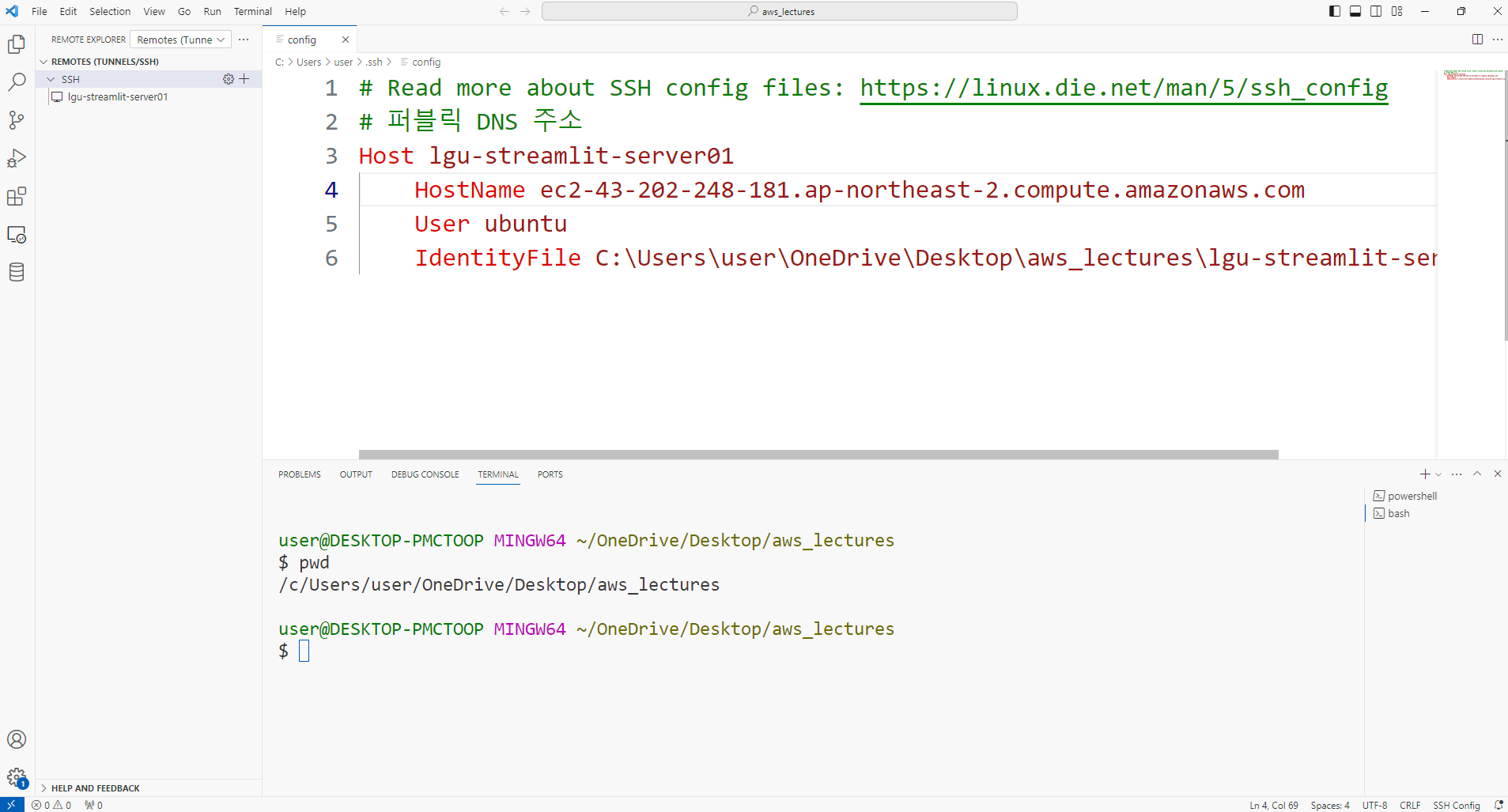
- VS Code에서 주소를 변경한다. 변경된 퍼블릭 DNS를 선택한다.
S3 버킷 연결
- S3 서비스 선택 및 버킷 만들기 선택
- 버킷 이름 지정 : lgu6-streamlit-s3

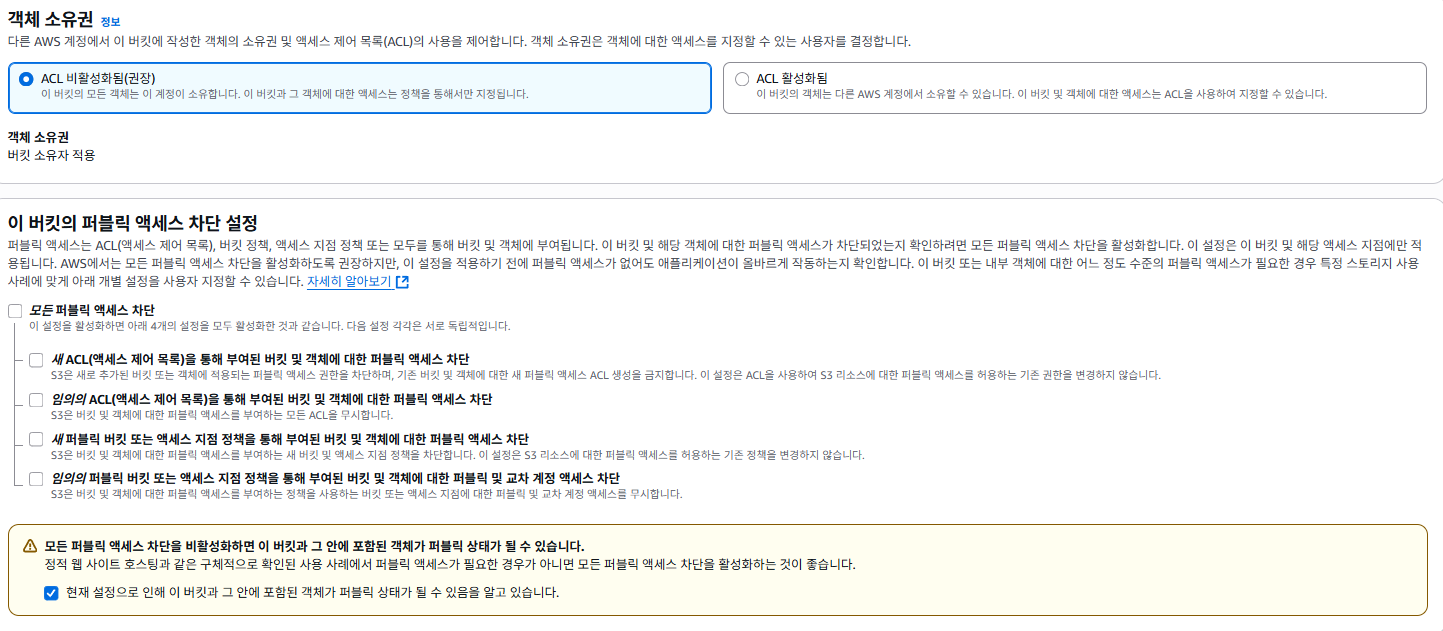
- 객체 소유권과 퍼블릭 액세스 차단 비활성화
- 하단으로 내려와서 버킷 만들기 버튼 클릭
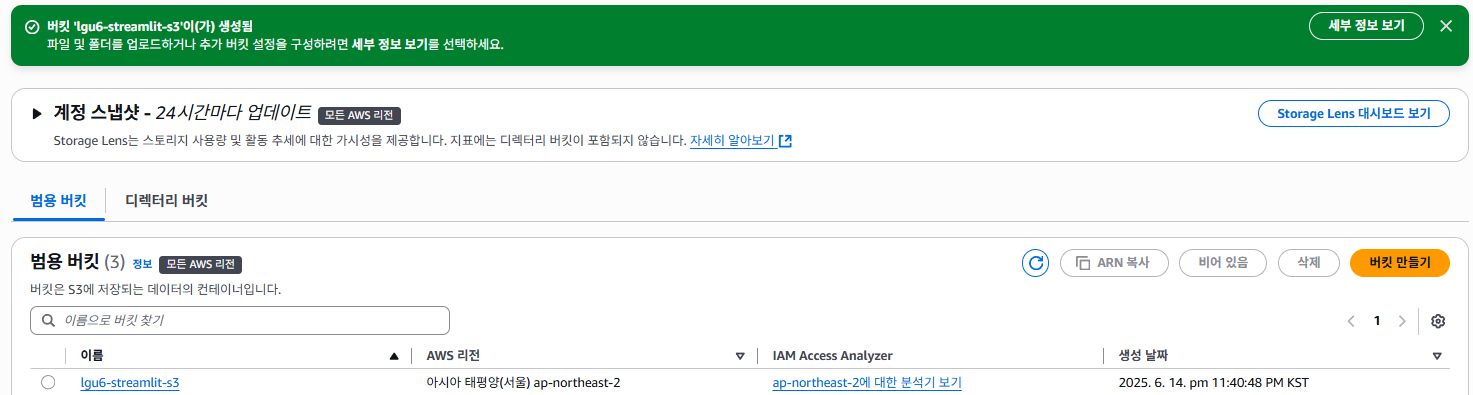
- 범용 버킷 생성확인
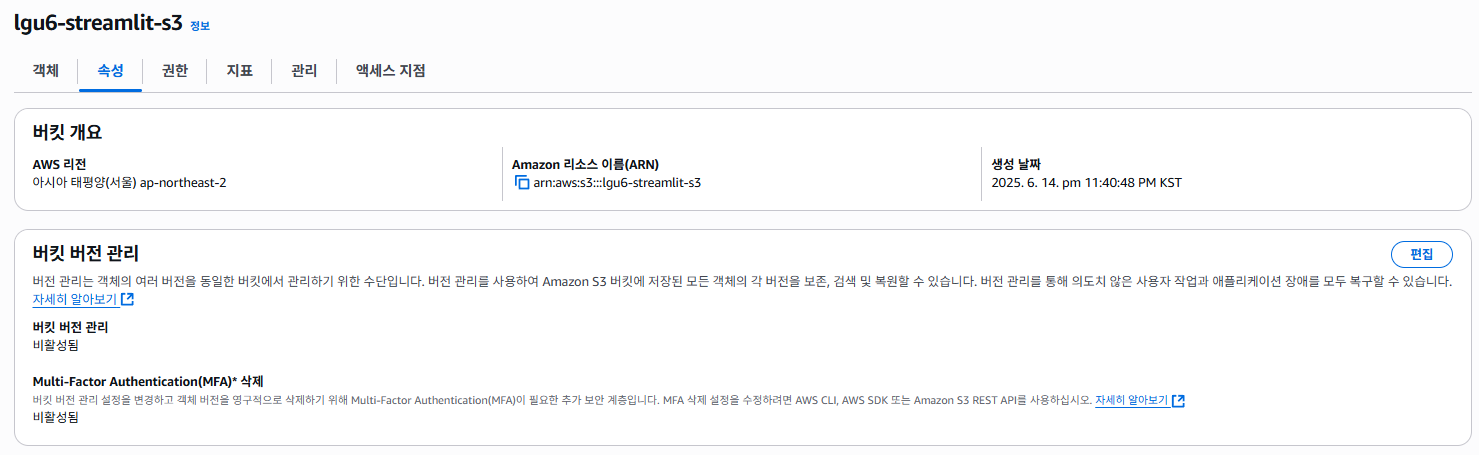
- 해당 버킷 클릭 > 속성 탭에서 Amazon 리소스 이름 (ARN 주소 확인)
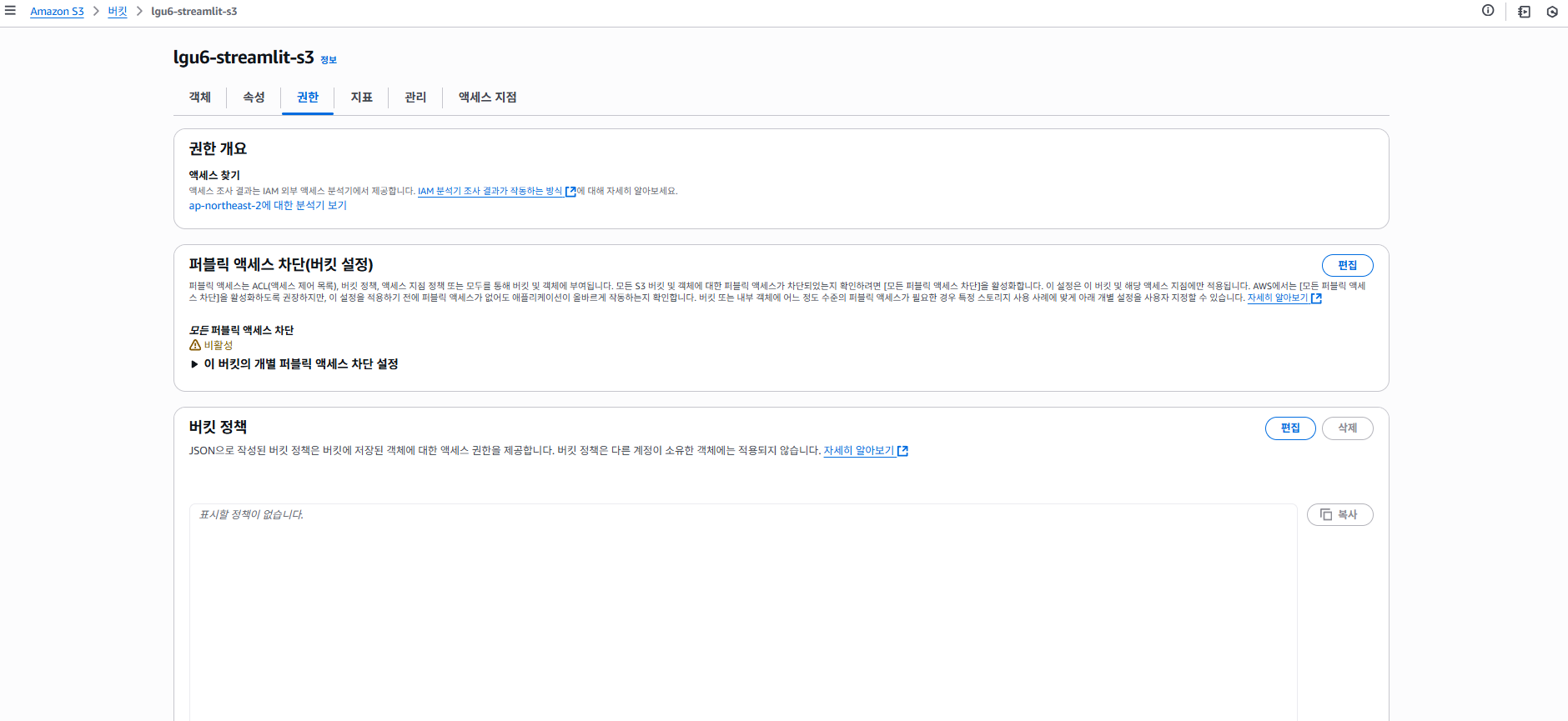
- 권한 > 버킷 정책 편집 클릭

- 다음 그림과 같이 작업
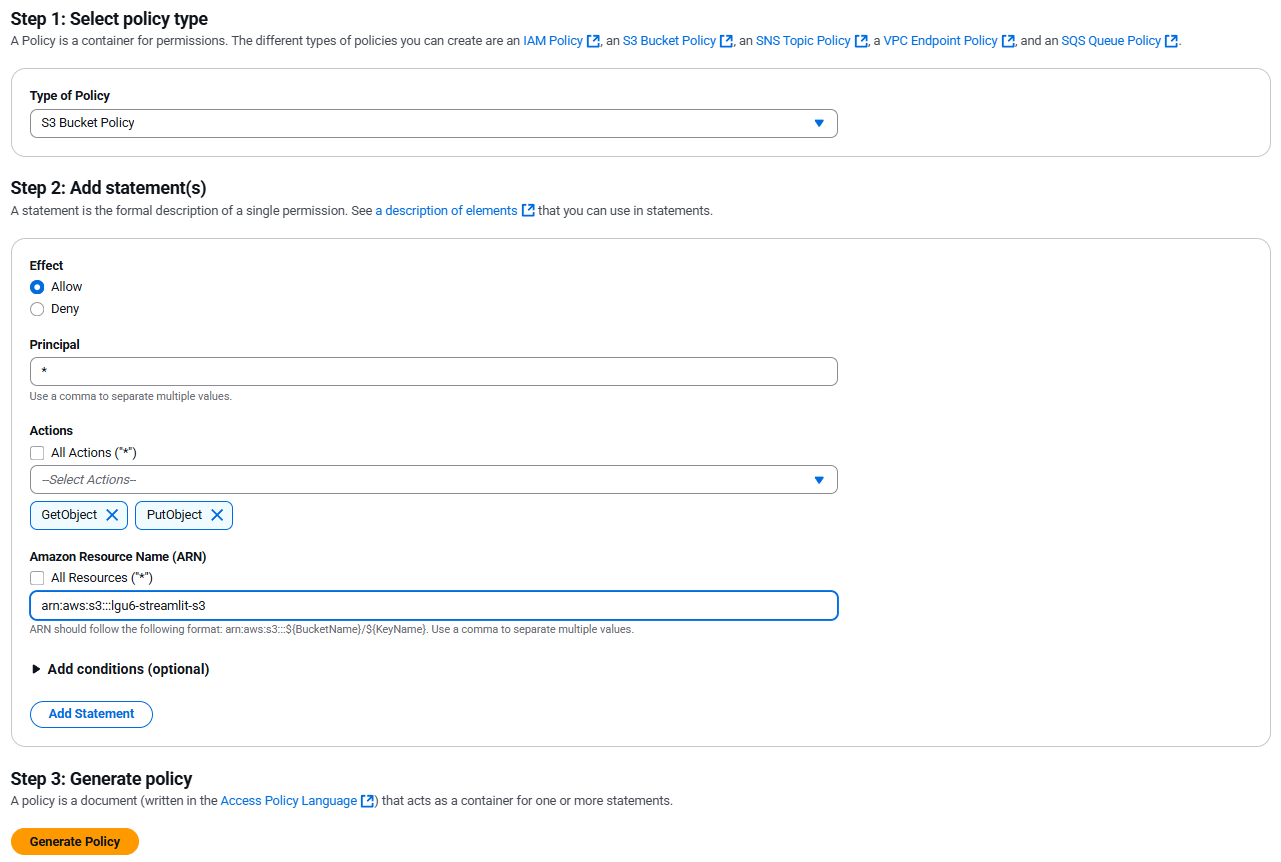
- 위 상태에서 Add Statement 선택 후 Step 3. Generate Policy 선택 또는 아래와 같이 지정
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::lgu6-streamlit-s3/*"
}
]
}
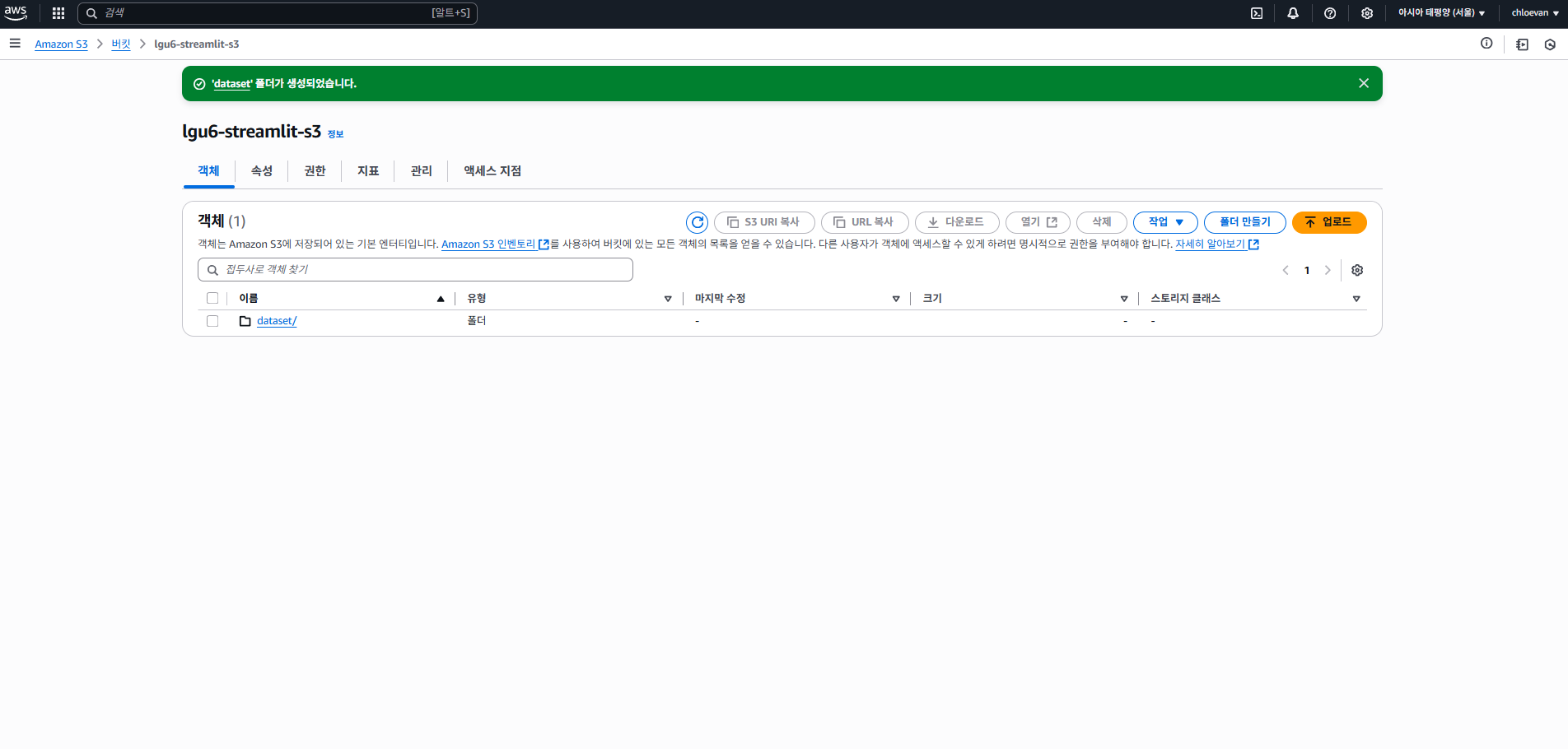
- 객체 Tab에서 폴더 만들기 : dataset
I AM 역할 설정
- I AM > 역할 선택 > 역할 생성 버튼 클릭
- 다음과 같이 지정하고 다음 선택
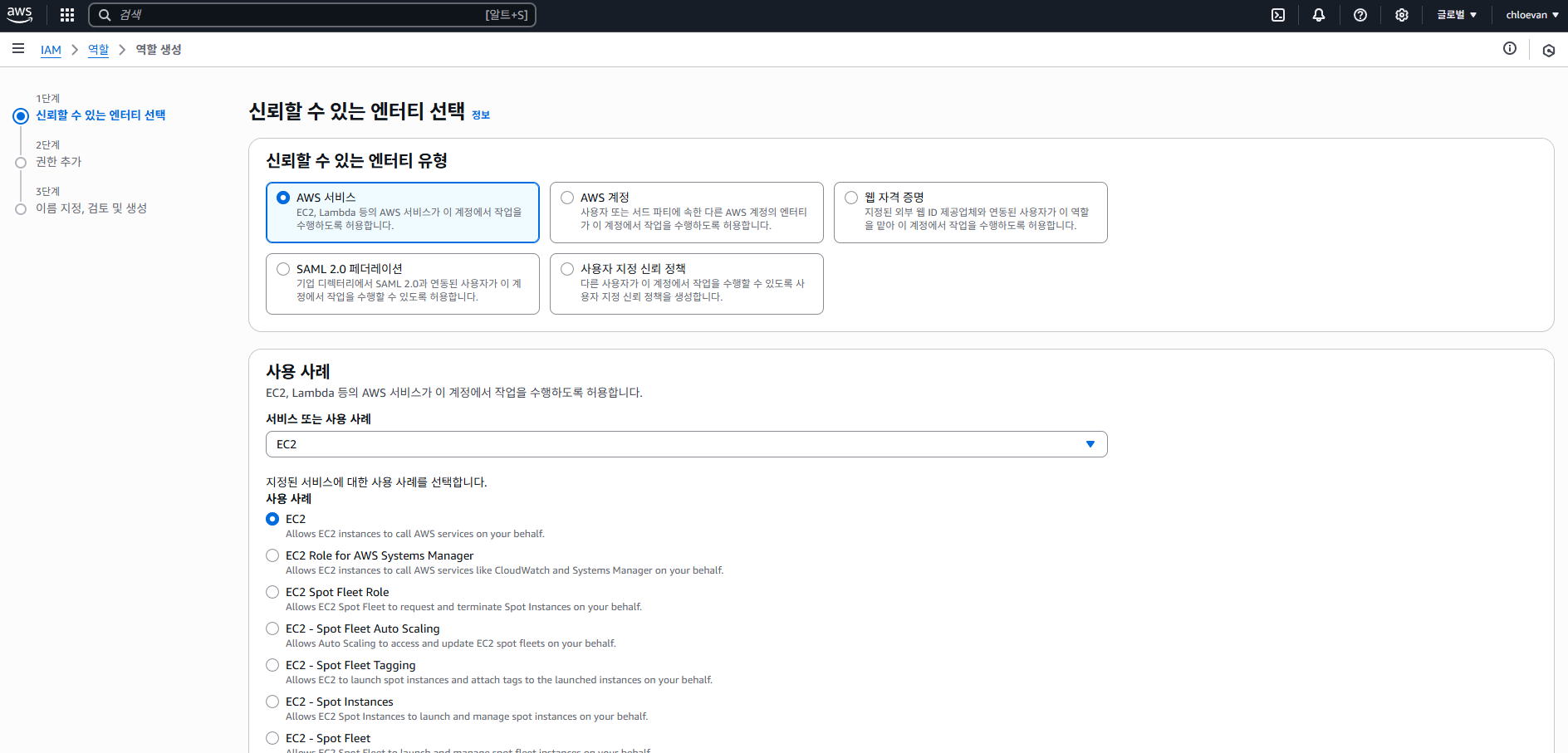
- 권한 추가는 넘어가고, 이름 지정, 검토 및 생성에서 역할 이름 지정 후 역할 생성 버튼 클릭
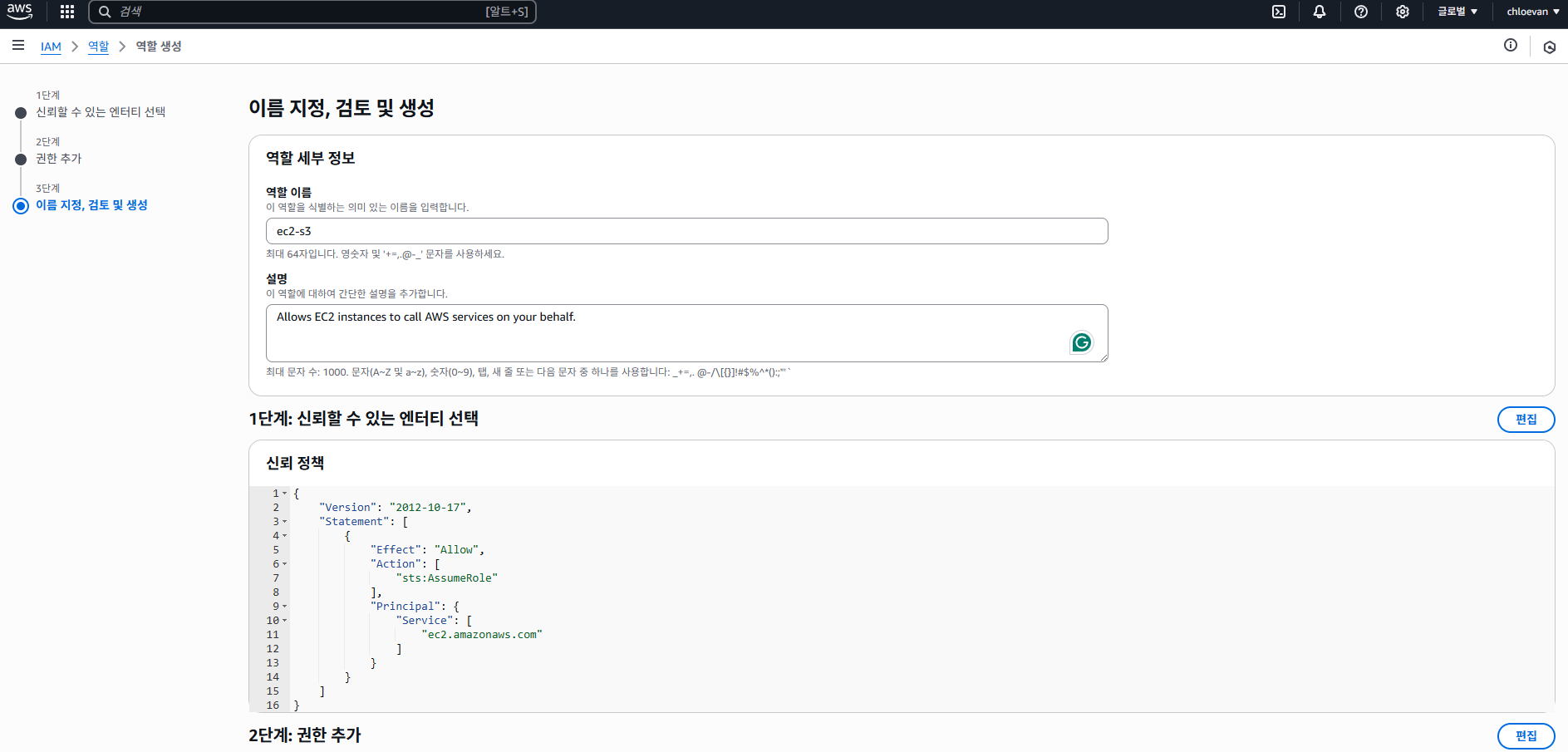
EC2 인스턴스와 I AM 역할 연결
- EC2 > 인스턴스 에서 인스턴스 클릭
- 작업 > 보안 > IAM 역할 수정 클릭
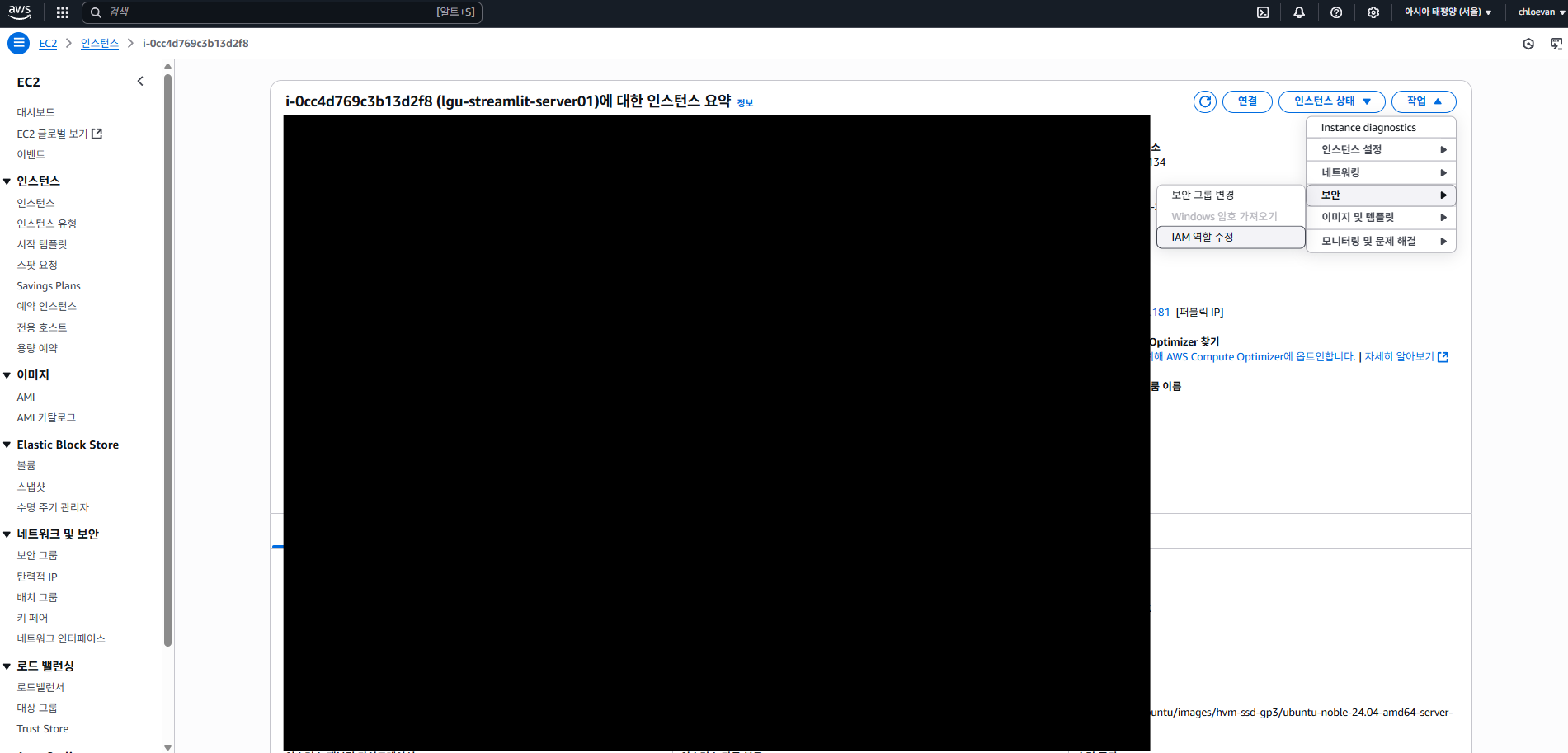
- 방금 전 생성한 IAM 역할 지정
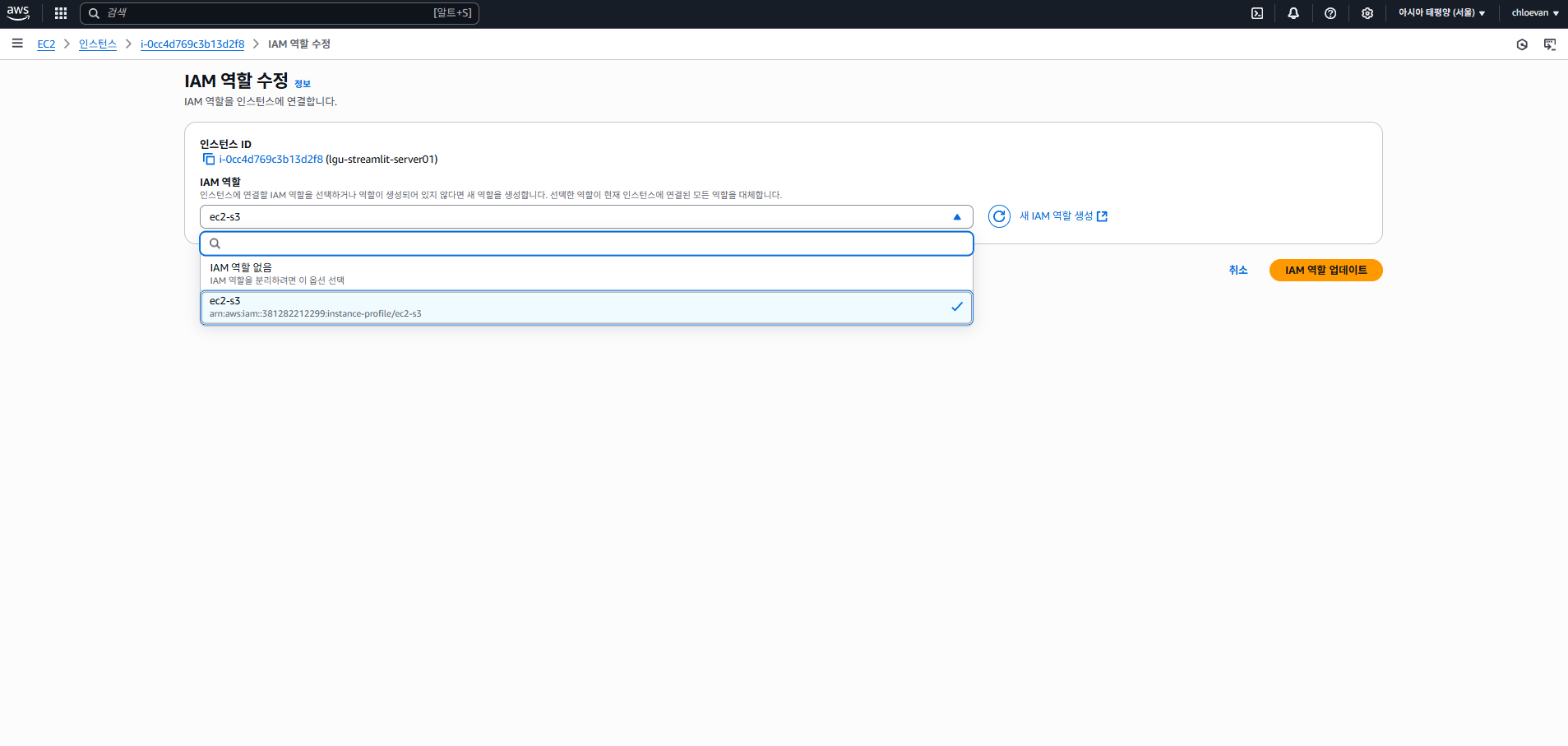
정책 추가
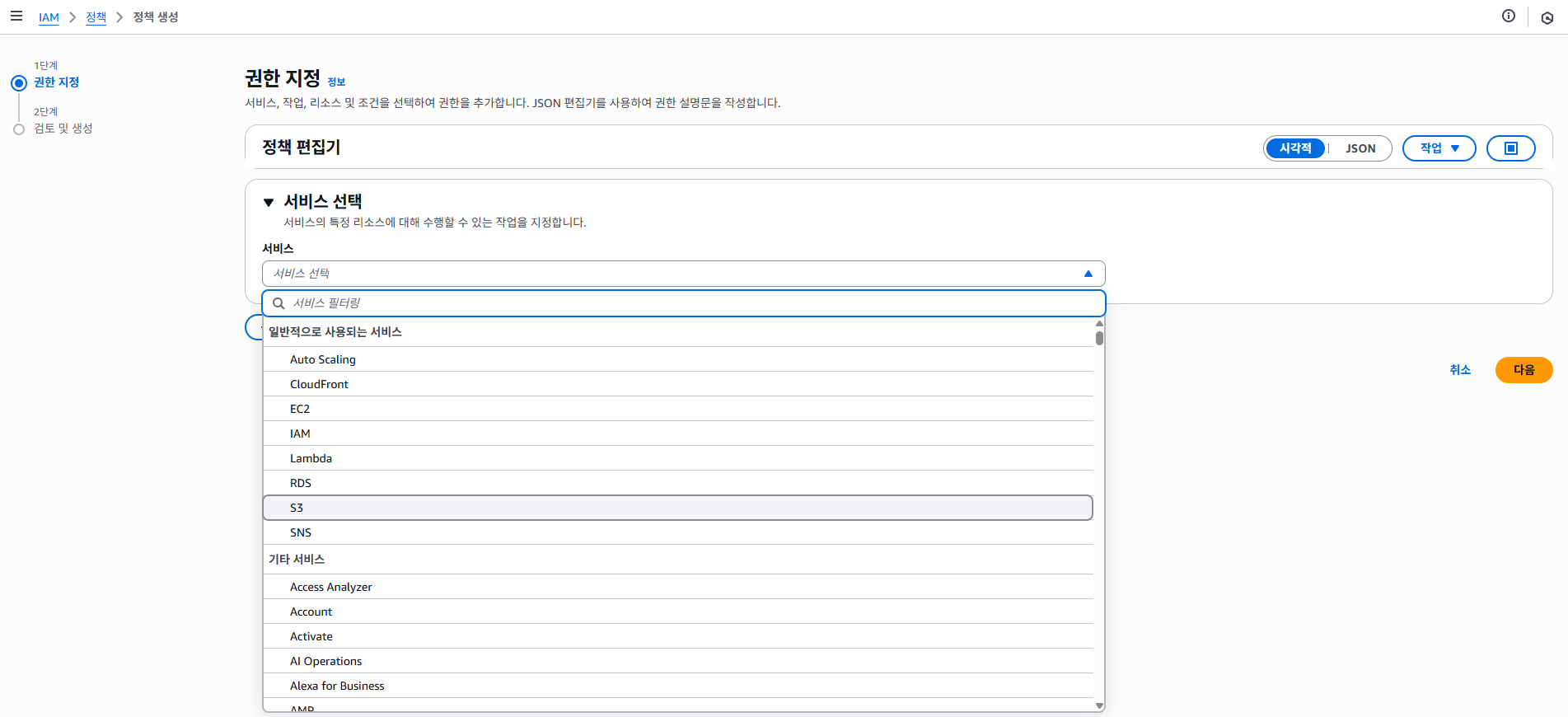
- IAM > 정책에서 정책 생성 버튼 클릭
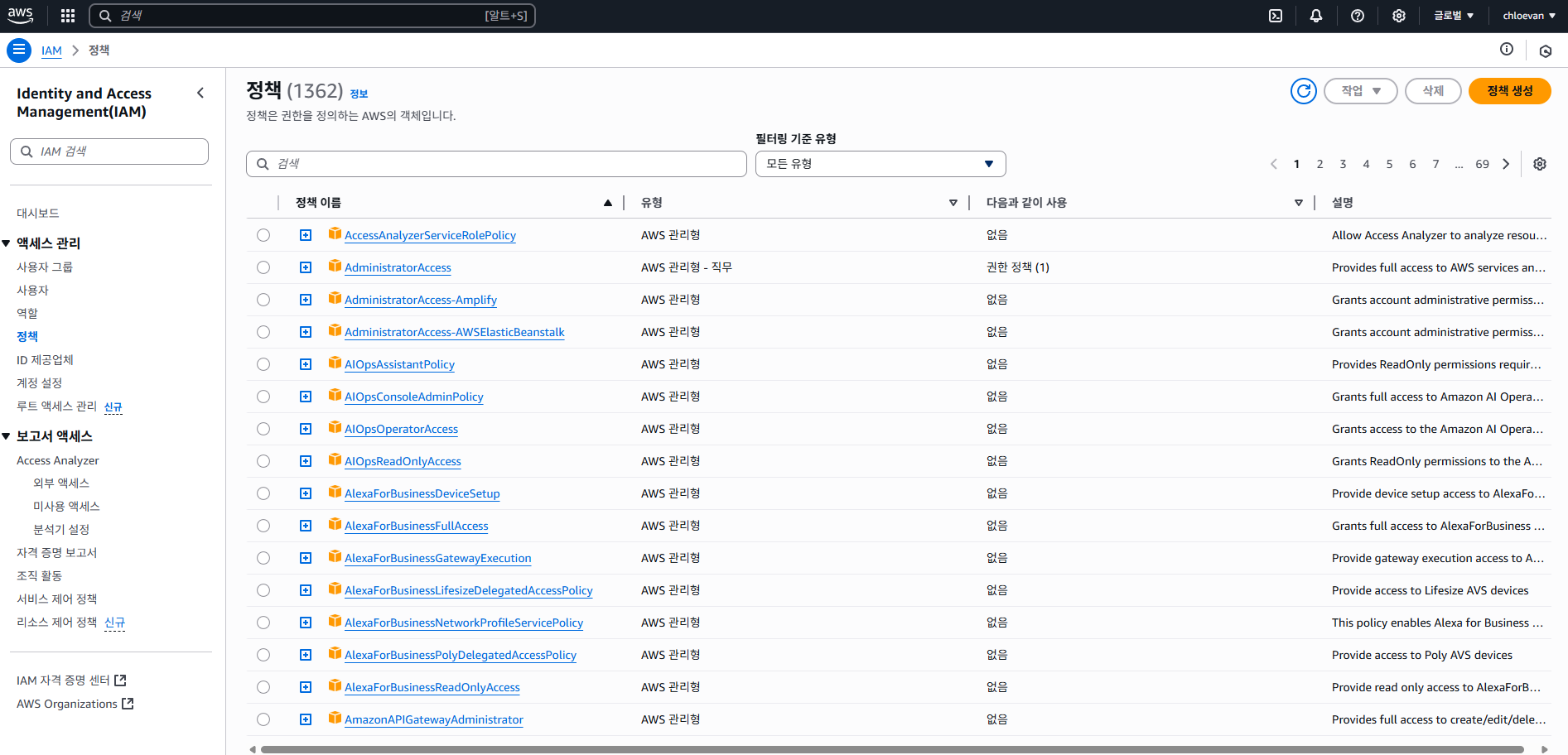
- 정책 편집기에서 다음과 같이 순차적으로 지정
- 서비스 - S3
- 작업 - ListBucket, GetObject, PutObject를 검색하여 선택한다.
- 리소스 - 특정 을 선택한 후, bucket과 object에 각각 ARN 추가를 합니다.
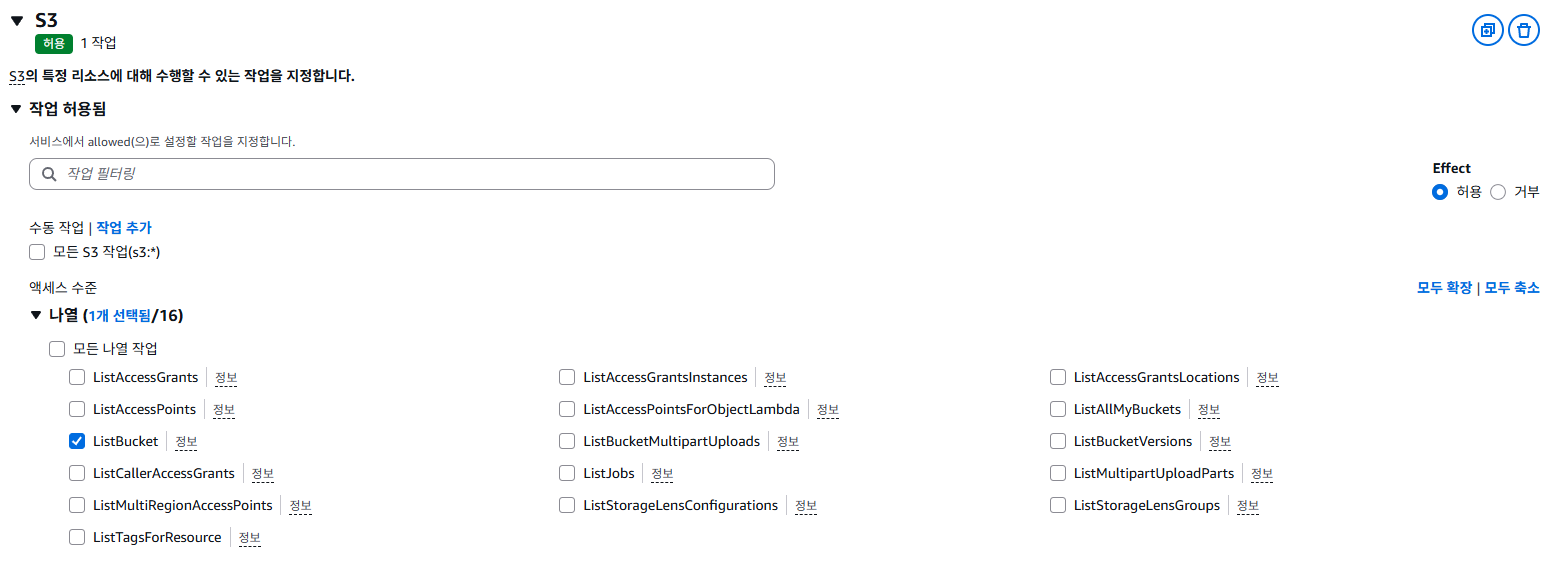
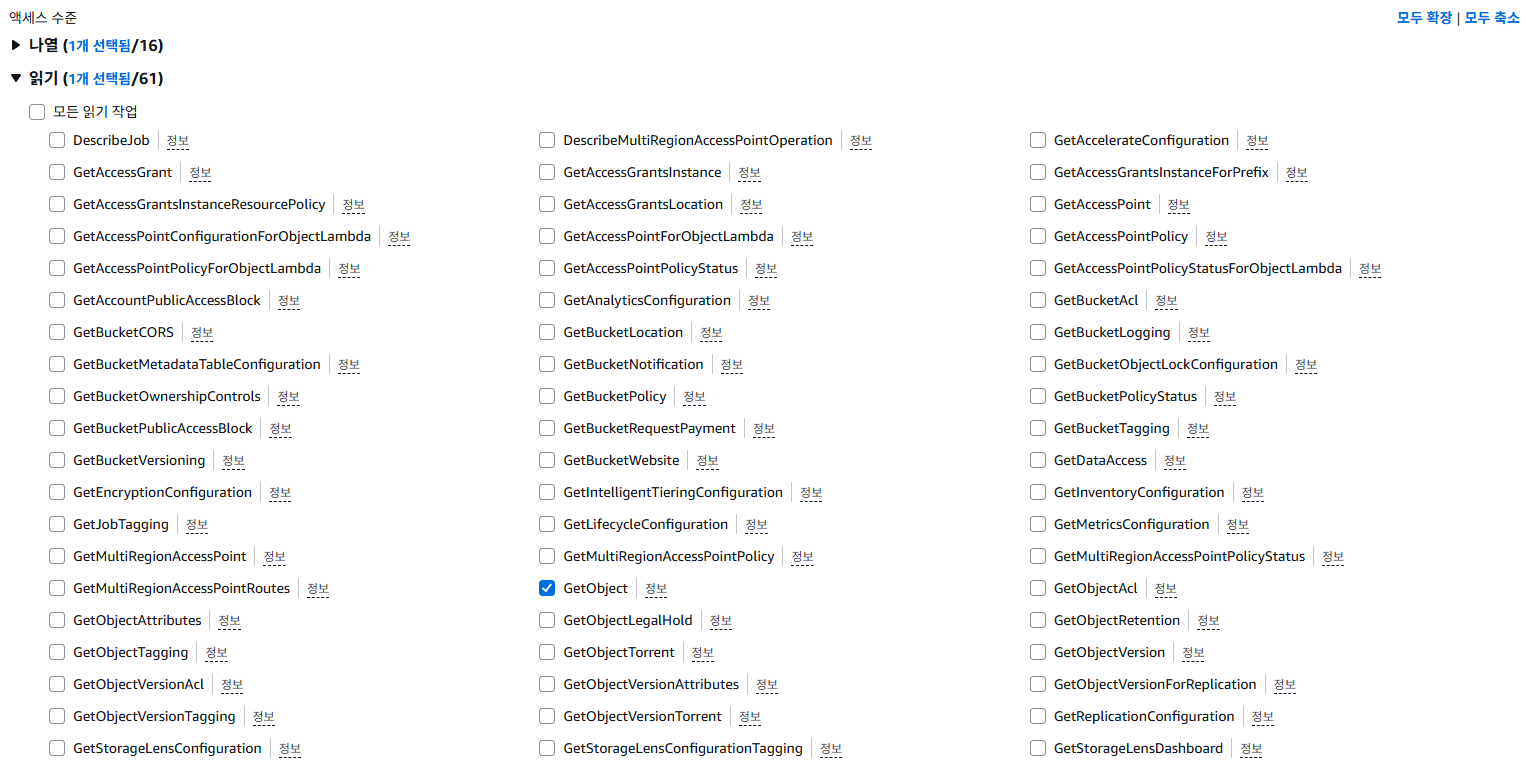
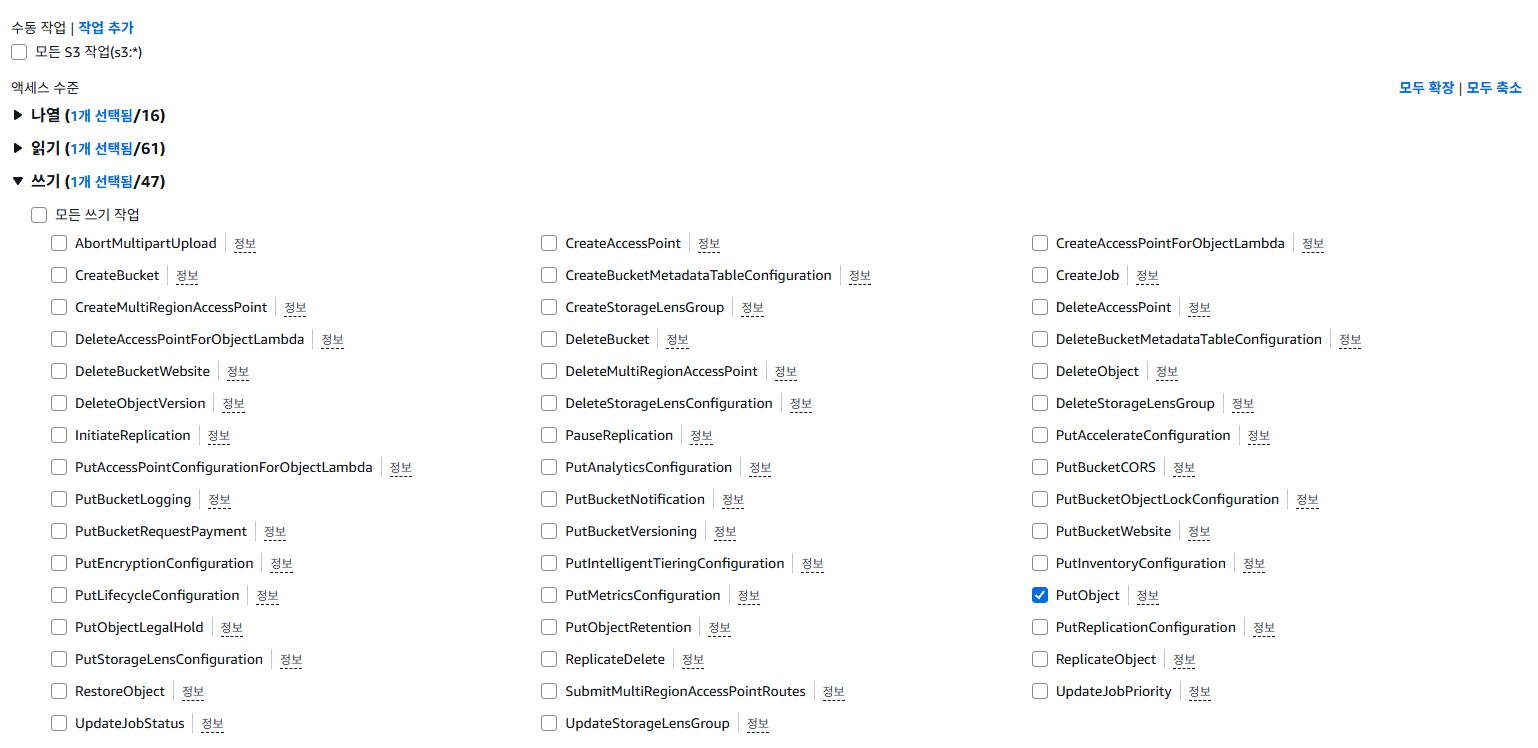
- 리소스 탭에서 특정 > ARN 추가 하기

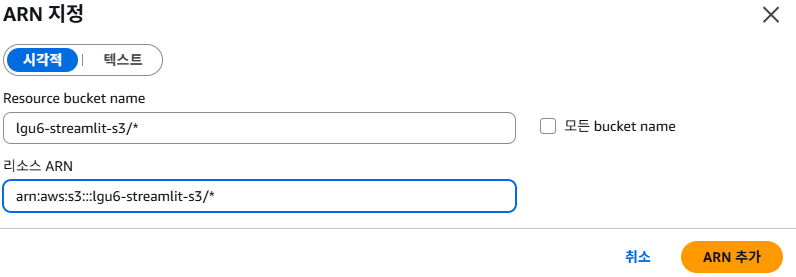
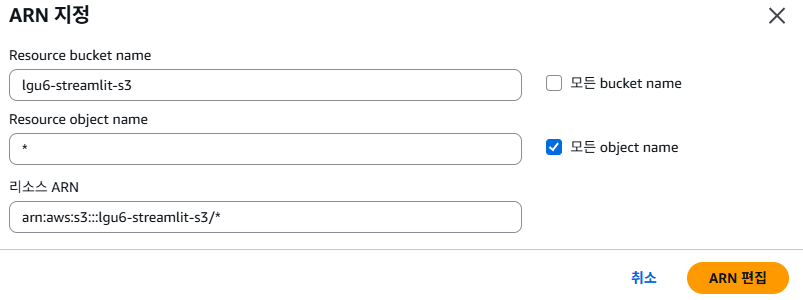
- 정책 세부 정보 확인
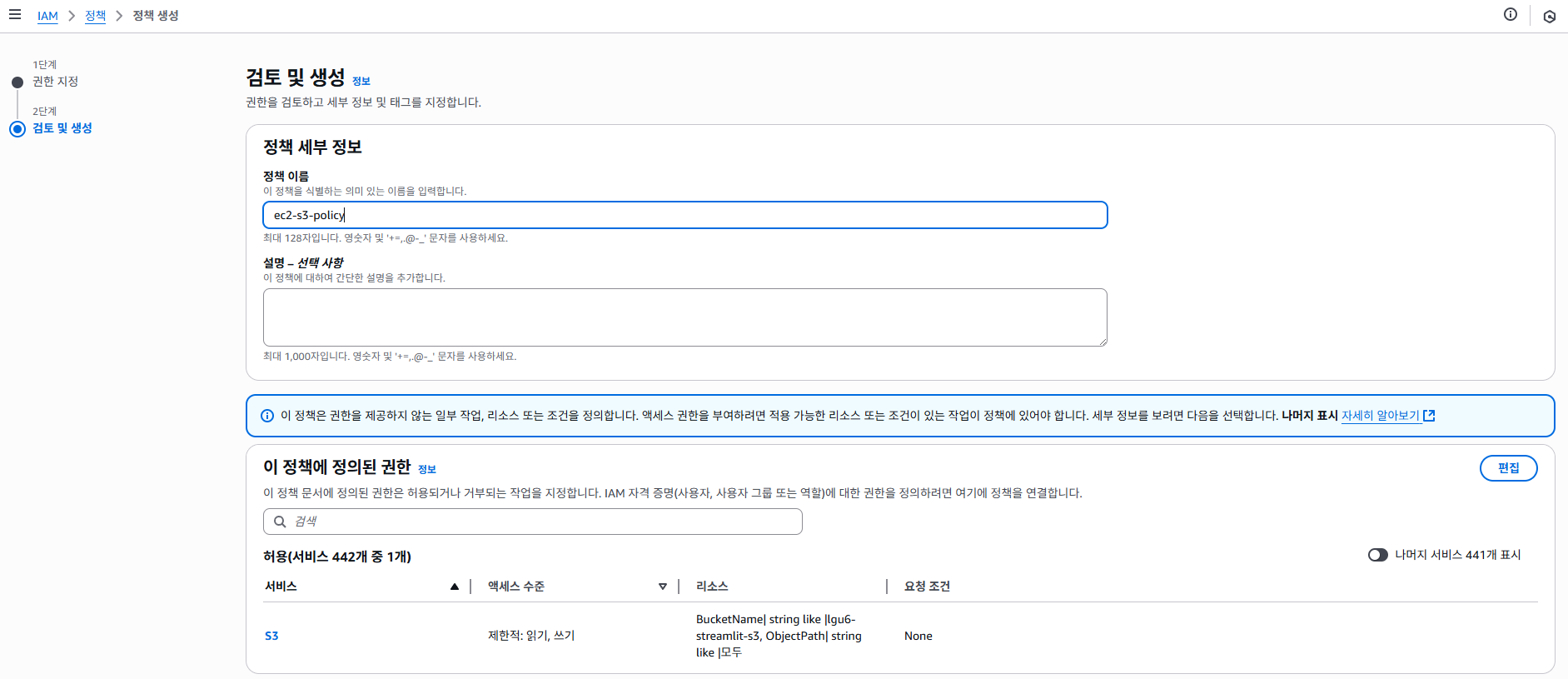
- 정책에서 ec2-s3-policy 선택
- 화면 가운데 연결된 엔터티 탭에서 연결 클릭
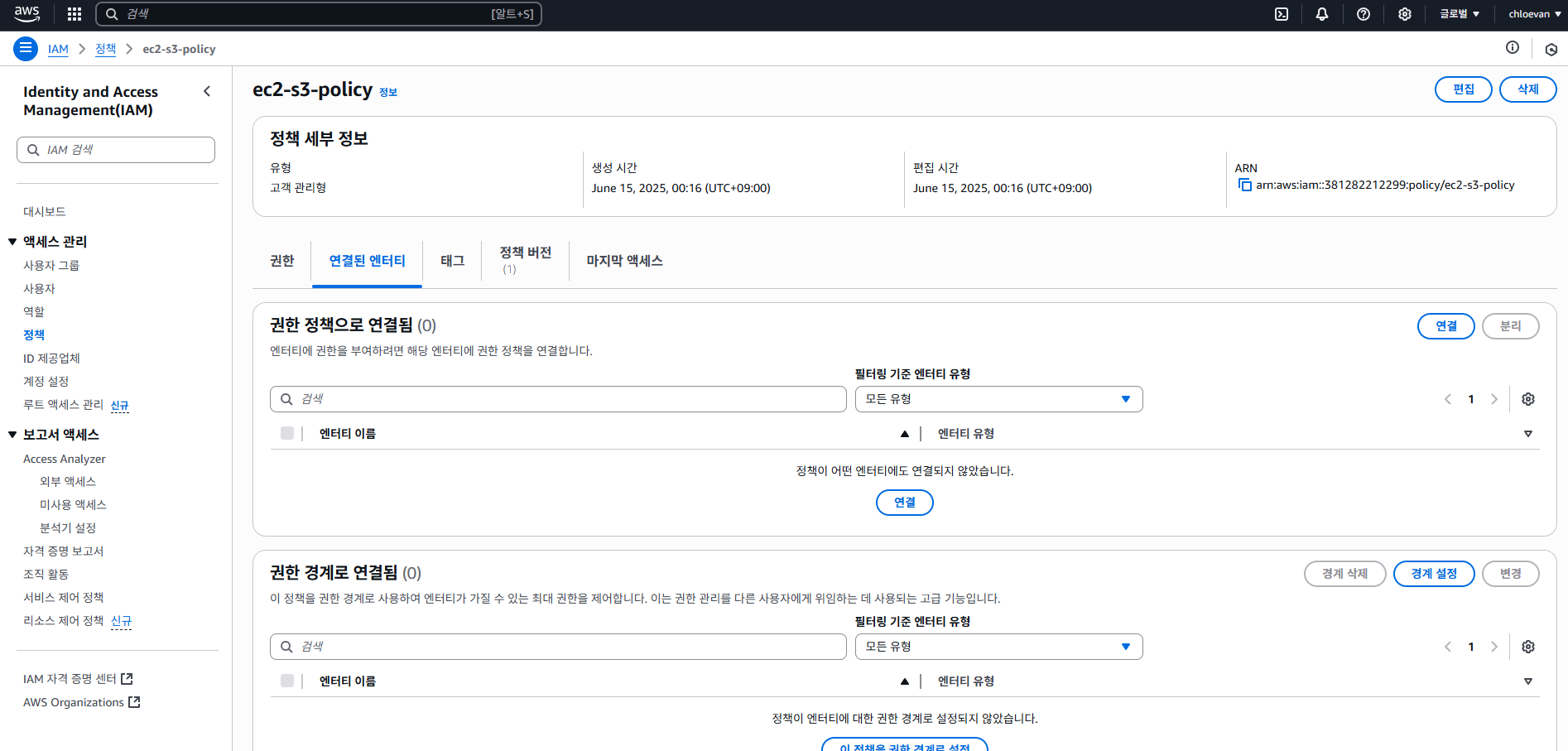
- 엔터티 이름 ec2-s3 선택 및 정책 연결
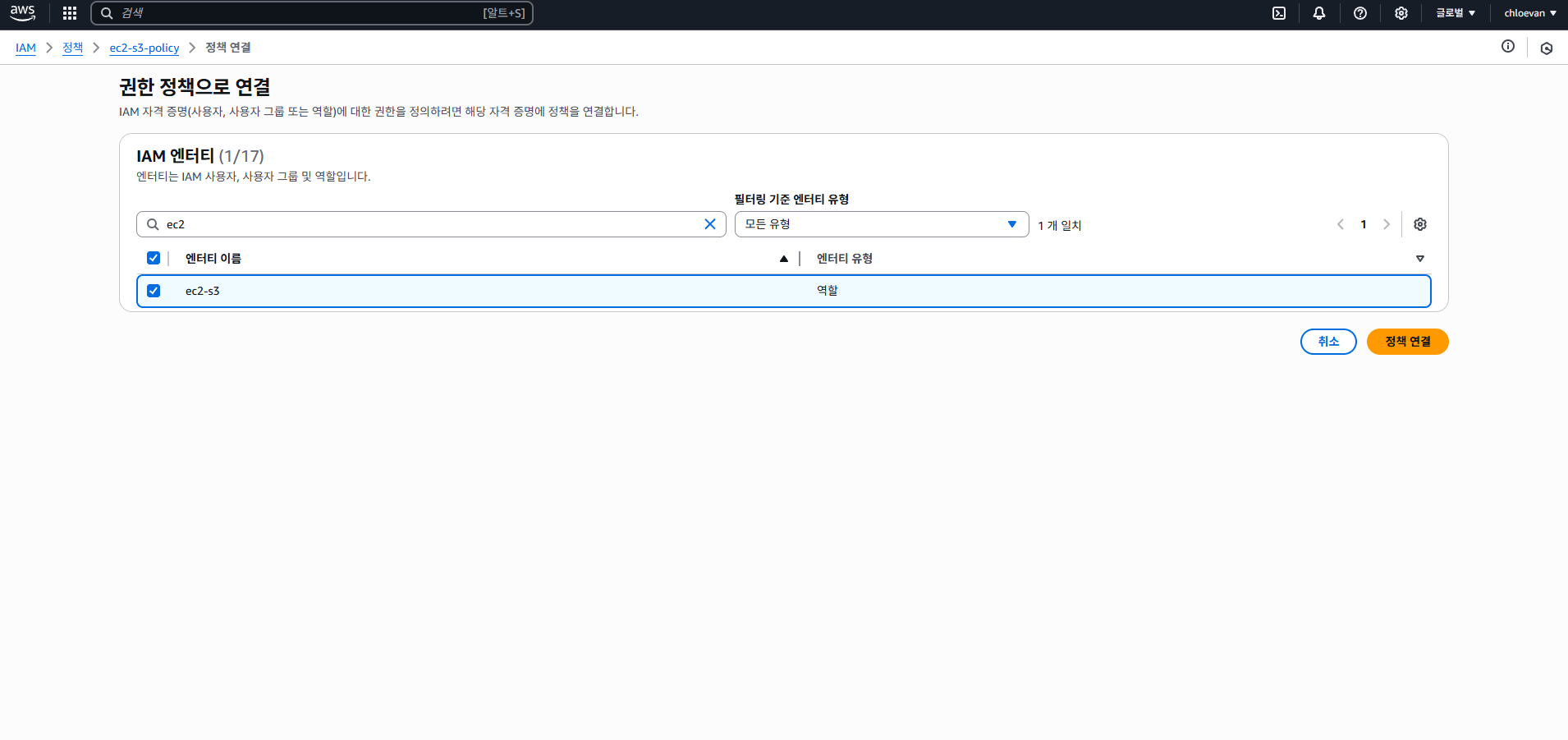
- 이번에는 IAM > 역할 에서 ec2-s3 선택 후 아래 화면과 같이 정책 이름 선택 후 정책 연결하기
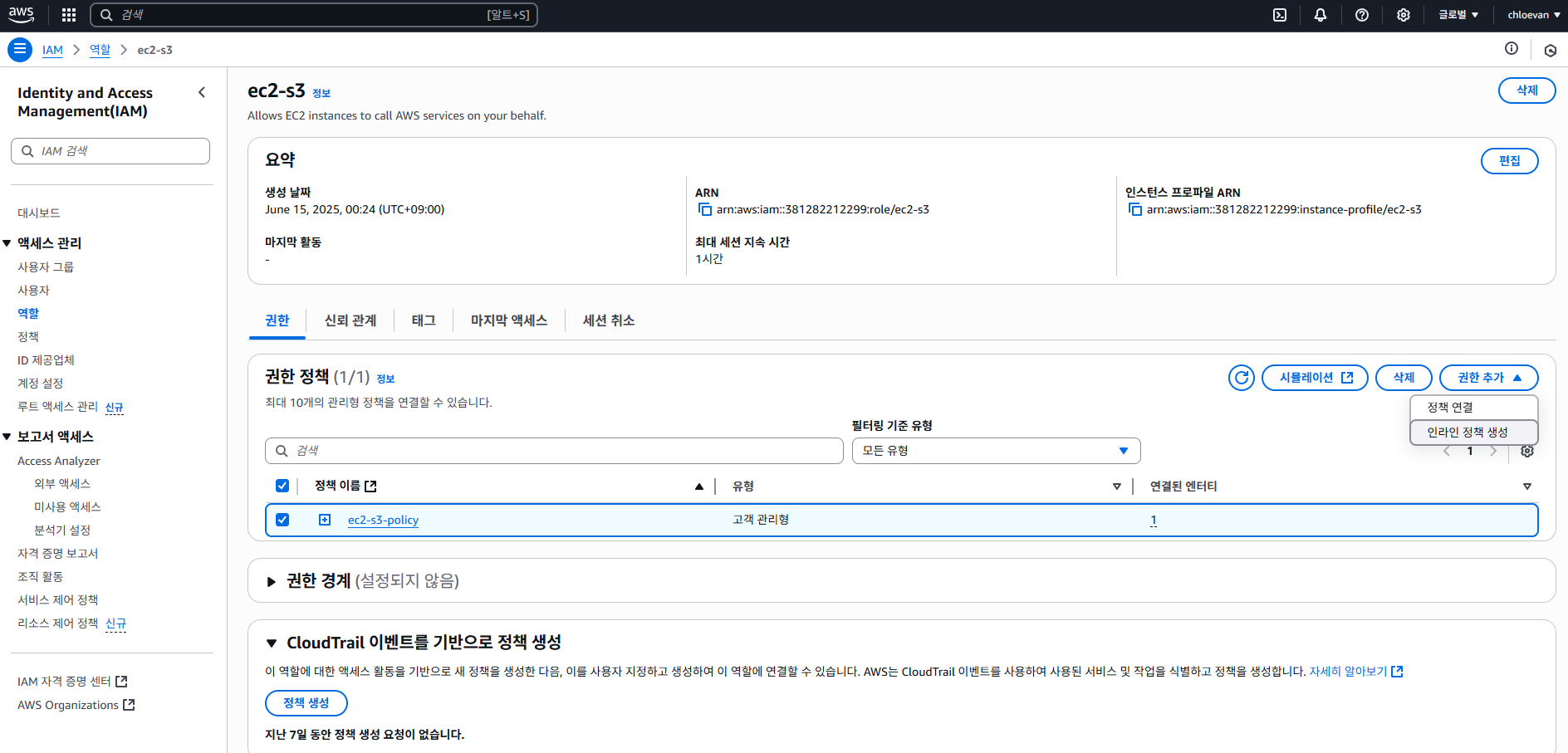
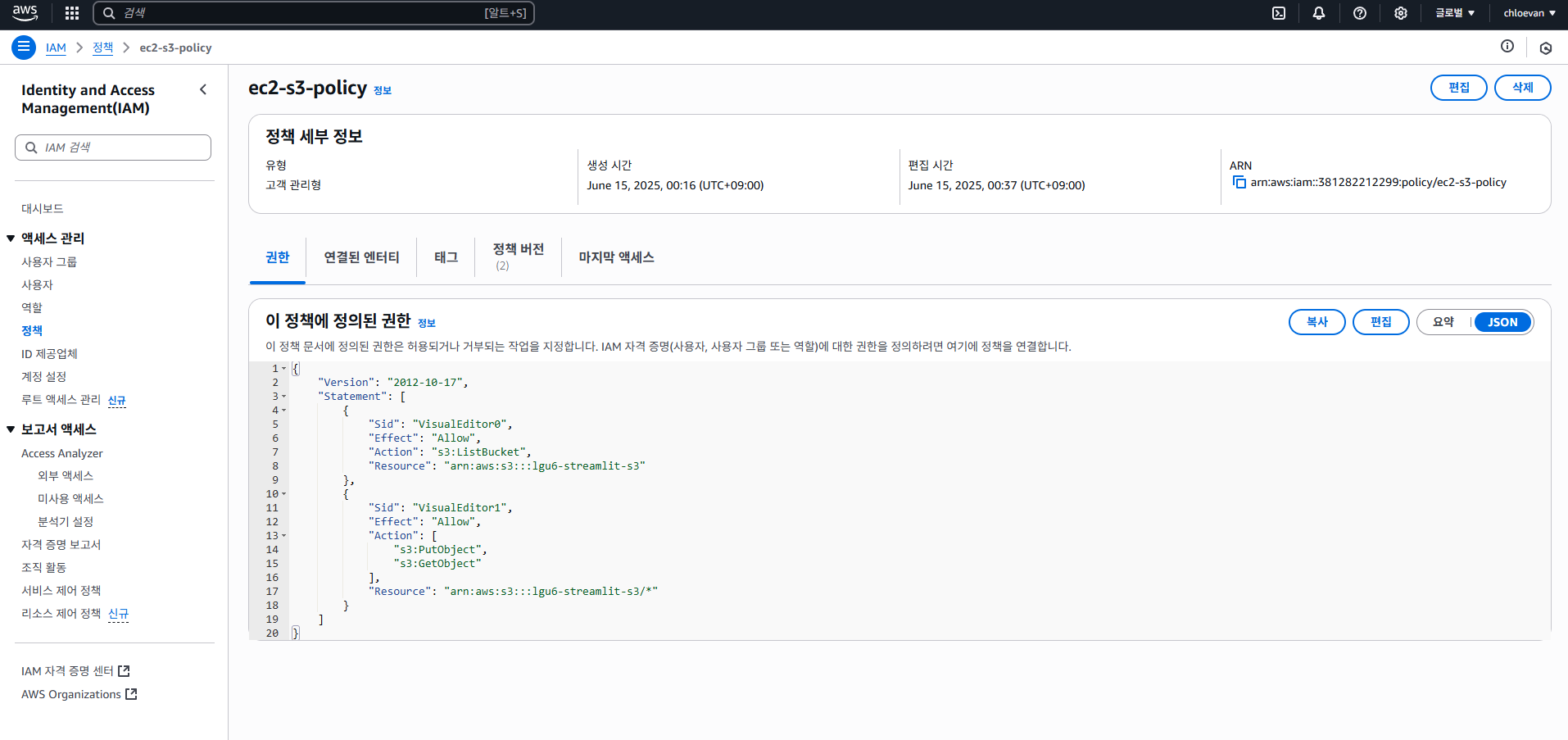
최종 ec2-s3-policy 형태
- 정의된 권한은 다음과 같다. 이 때,
Resource에 있는 주소에 유의한다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::lgu6-streamlit-s3"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::lgu6-streamlit-s3/*"
}
]
}
VS Code에서 라이브러리 추가
- 다음과 같이 라이브러리를 추가 후, 설치 한다. (가상환경 접속해서 설치)
streamlit
jupyterlab
pandas
boto3
awscli
(temp) ubuntu@ip-172-31-33-134:~/temp$ uv pip install -r requirements.txt
Resolved 120 packages in 504ms
Prepared 9 packages in 2.73s
Installed 9 packages in 271ms
+ awscli==1.40.35
+ boto3==1.38.36
+ botocore==1.38.36
+ colorama==0.4.6
+ docutils==0.19
+ jmespath==1.0.1
+ pyasn1==0.6.1
+ rsa==4.7.2
+ s3transfer==0.13.0
S3 버킷 테스트
- 설치 완료 후 다음 명령어 통해서 리스트가 잘 나오는지 확인
$ aws s3 ls s3://lgu6-streamlit-s3
PRE dataset/
- S3 버킷에서 폴더 추가 (폴더명 dataset2)
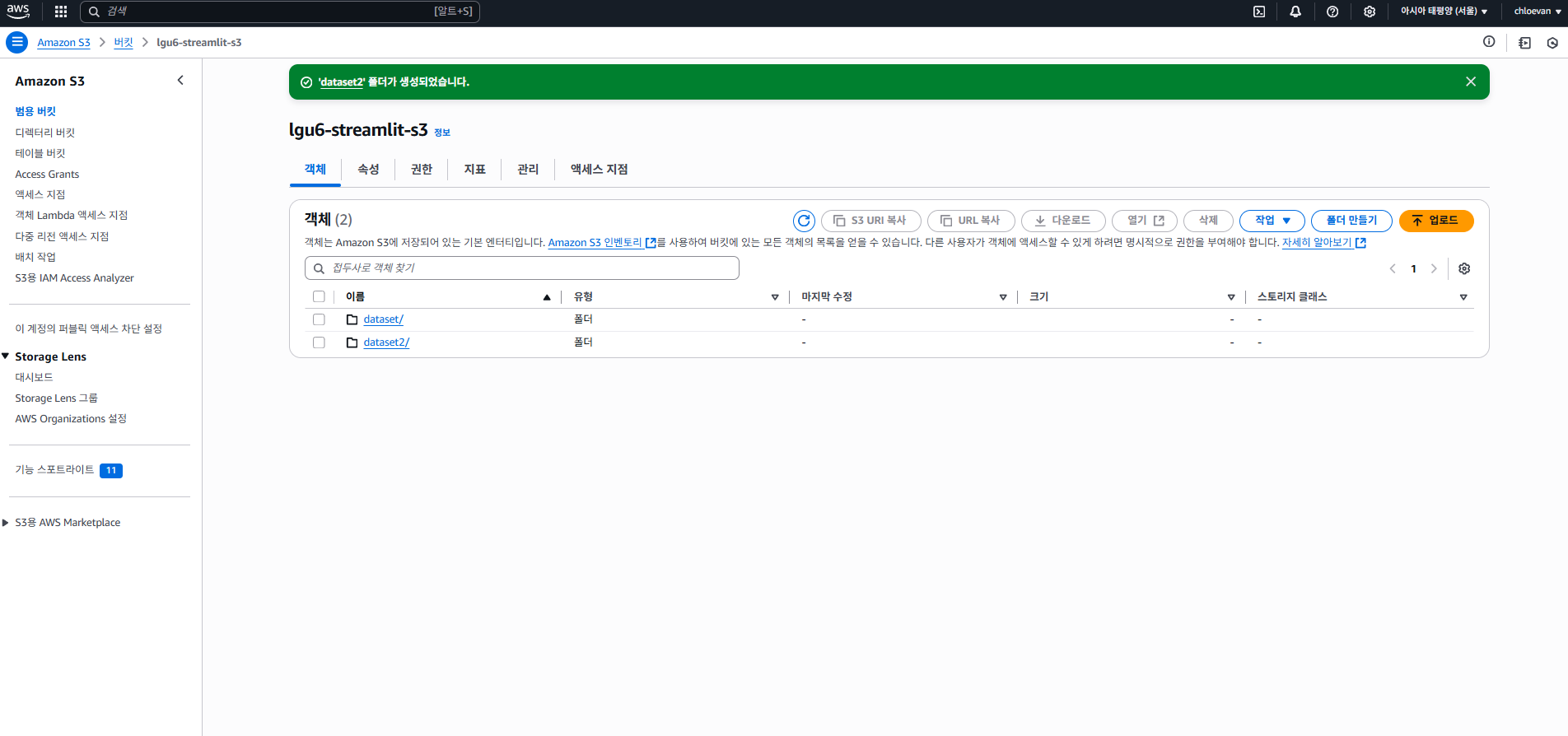
- 다시 아래 명령어 실행
$ aws s3 ls s3://lgu6-streamlit-s3
PRE dataset/
PRE dataset2/
시나리오
- 사용자가 “새 데이터 추가” 버튼을 클릭하면, 랜덤 점수가 생성되어 S3에 저장된다.
- 사용자가 “데이터 가져오기” 버튼을 누르면, S3에서 최신 데이터를 불러와 Streamlit에서 시각화된다.
- 두 버튼은 독립적으로 동작하여, 비동기적인 데이터 흐름을 단순하게 구현할 수 있다.
- 코드는 다음과 같다.
import streamlit as st
import boto3
import pandas as pd
import io
import random
from datetime import datetime
st.title("Hello AWS-Streamlit")
# S3 설정
bucket = 'lgu6-streamlit-s3'
key = 'dataset/random_scores.csv'
s3 = boto3.client('s3')
def load_data():
try:
obj = s3.get_object(Bucket=bucket, Key=key)
return pd.read_csv(io.BytesIO(obj['Body'].read()))
except s3.exceptions.NoSuchKey:
return pd.DataFrame(columns=['timestamp', 'name', 'score'])
def save_data(df):
buffer = io.StringIO()
df.to_csv(buffer, index=False)
s3.put_object(Bucket=bucket, Key=key, Body=buffer.getvalue())
def generate_row():
return {
'timestamp': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'name': random.choice(['Alice', 'Bob', 'Charlie', 'David']),
'score': random.randint(60, 100)
}
# 앱 UI
st.title("📦 EC2 ↔ S3 데이터 관리 앱")
# 1️⃣ 데이터 추가 버튼
if st.button("➕ 새 데이터 추가"):
df = load_data()
new_row = generate_row()
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
save_data(df)
st.success(f"S3에 {new_row['name']} 점수 {new_row['score']} 저장됨")
# 2️⃣ 데이터 가져오기 버튼
if st.button("📥 데이터 가져오기"):
df = load_data()
if df.empty:
st.warning("S3에 저장된 데이터가 없습니다.")
else:
st.subheader("📋 저장된 데이터")
st.dataframe(df)
st.subheader("📊 평균 점수 그래프")
st.bar_chart(df.groupby("name")["score"].mean())
구현된 화면
- 비 동기적으로 처리


- S3 버킷에서도 다음과 같은 데이터 확인

