Amazon SageMaker ML on Local Machine via VS Code
Page content
개요
- AWS SageMaker 사용하여 ML 코드 생성
- VS Code에서 코드 생성
- S3 Bucket에서 모델 업로드 및 다운로드 응용하여 테스트 진행 코드
사전조건
- SageMaker가 정상적으로 실행되려면 Docker가 필요할 수 있기, Docker를 먼저 설치하기를 바란다.
AWS & SageMaker 연결 설정
-
I AM 에서 사용자에서 생성한다.
-
Access Key까지 같이 생성한다.
-
사용자에 대한 I AM Role 도 생성한다.
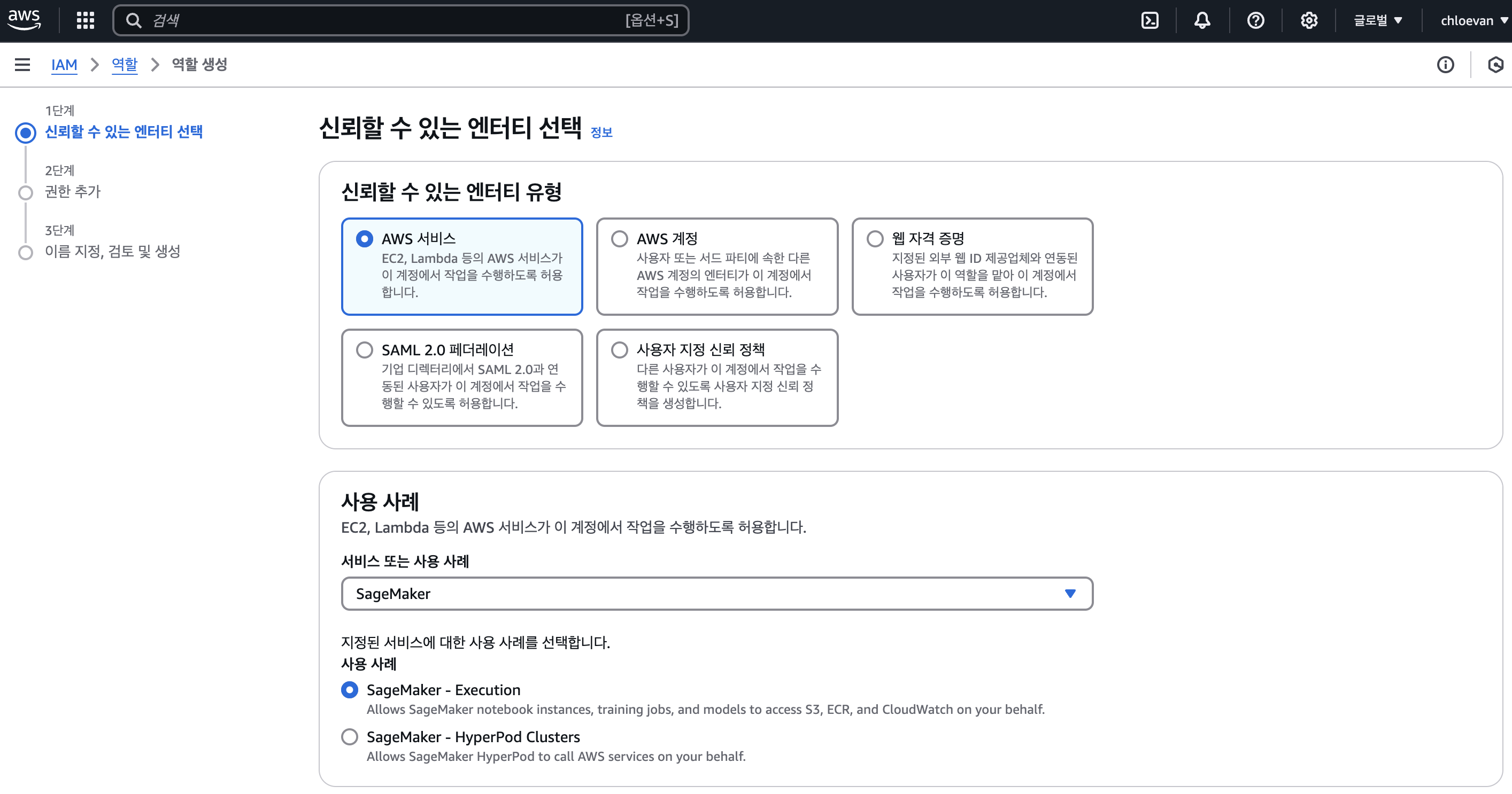
-
awsMLDLRole 역할 이름을 부여했다.
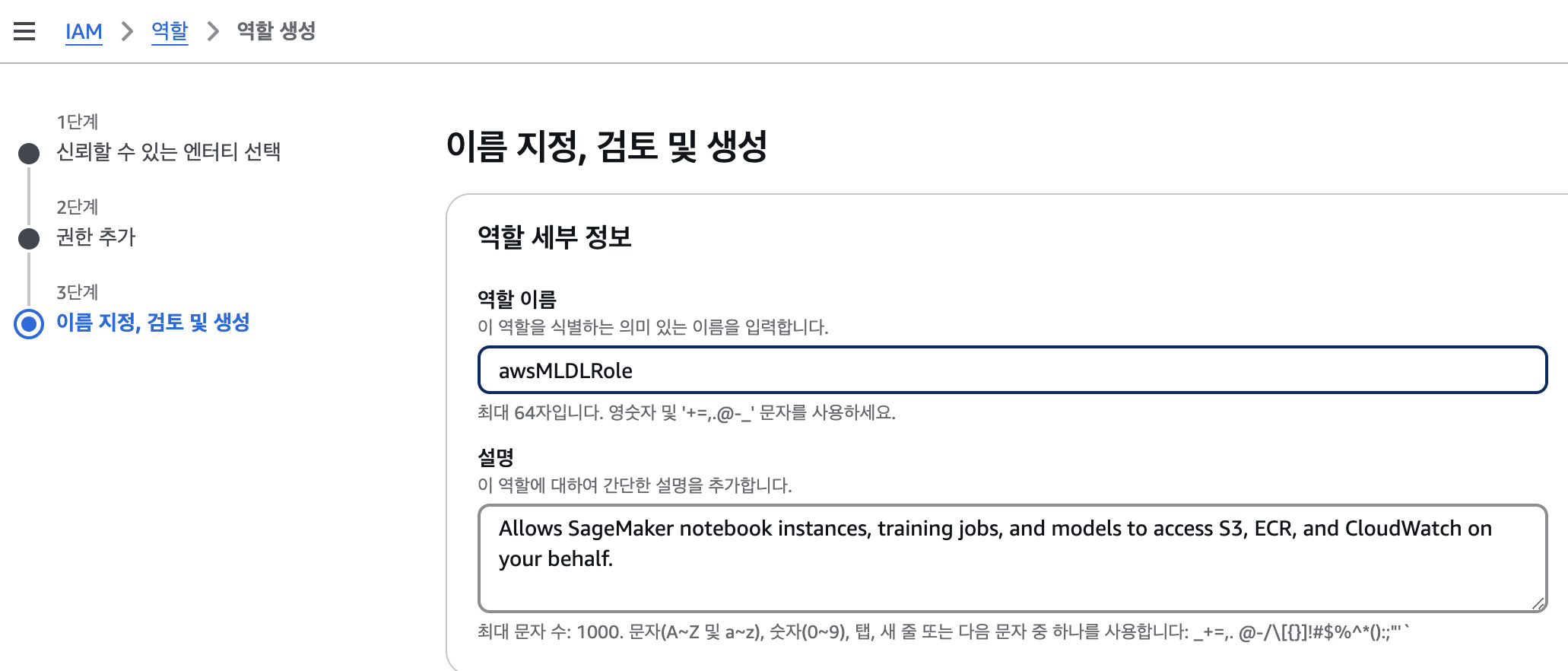
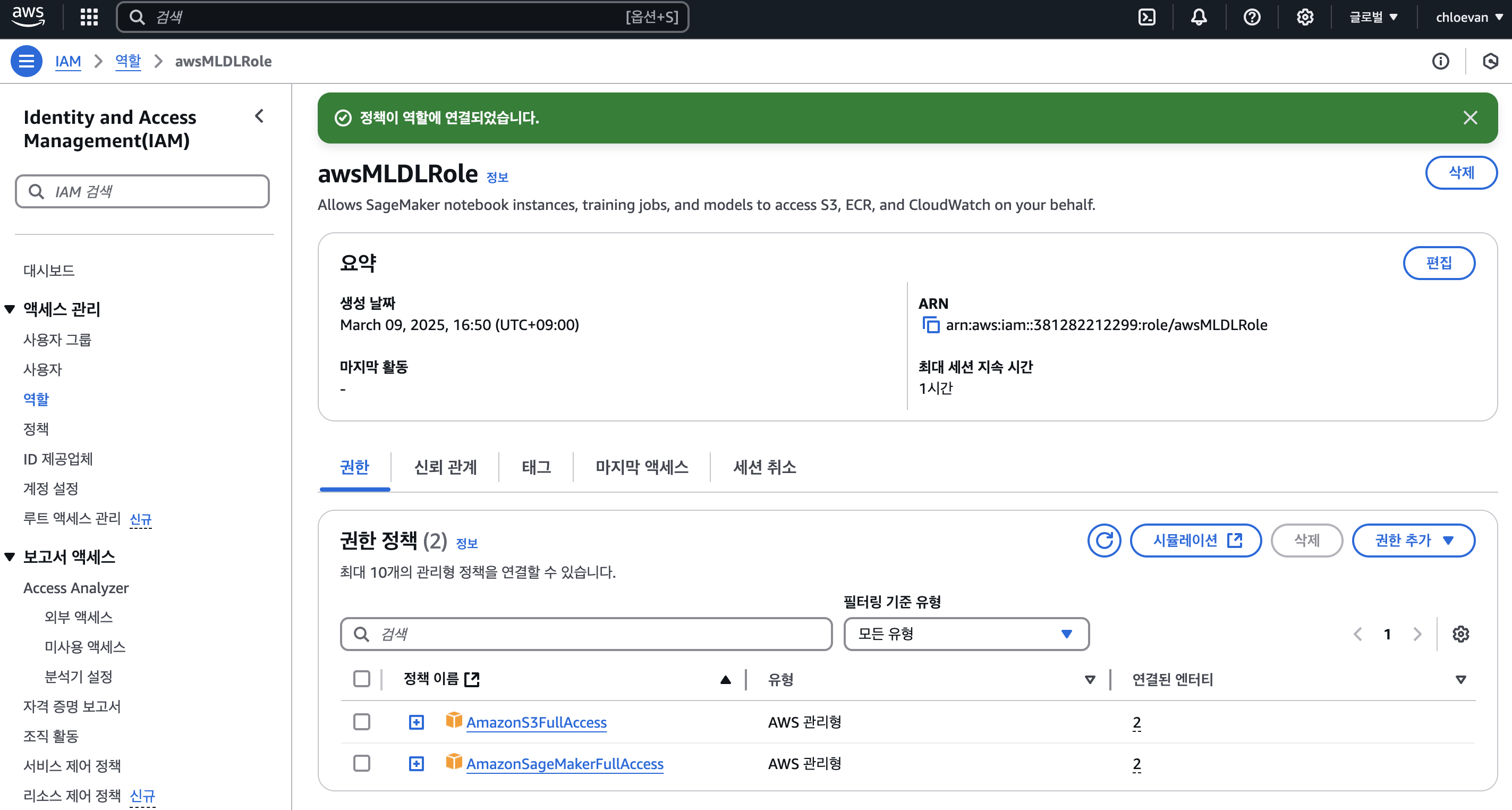
Local PC 설정
- Access Key와 Security Key 입력
$ aws configure
AWS Access Key ID [****************BIGP]:
AWS Secret Access Key [****************/5l8]:
Default region name [us-east-1]:
Default output format [json]:
- 만약 Default region name 변경을 원한다면 vi 편집기로 변경한다.
$ vi ~/.aws/config
- 편집기에서 파일을 열고 다음과 같이 나오면 us-east-1과 같은 형태로 변경한다.
[default]
region = ap-northeast-2
output = json
개발환경
- Python 개발환경을 설정한다. 여기에서는 virtualenv로 설정하였다.
$ virtualenv venv
$ source venv/bin/activate
(venv) $ pip install -r requirements.txt
- 주요라이브러리 설치를 위해 다음과 같이 설정하였다. (requirements.txt)
boto3
awscli
sagemaker
matplotlib
seaborn
scikit-learn
jupyterlab
소스코드
- 소스코드를 하나씩 살펴보도록 한다.
Import Necessary Libraries
- 버전 확인
- boto3: AWS 서비스를 Python에서 사용하기 위한 SDK
- sagemaker: AWS의 머신러닝 서비스인 SageMaker를 위한 라이브러리
- pandas: 데이터 분석 및 처리를 위한 라이브러리
- sklearn: 머신러닝 알고리즘과 도구를 제공하는 라이브러리
import boto3
import sagemaker
import pandas as pd
import sklearn
print(f"boto3 version: {boto3.__version__}")
print(f"sagemaker version: {sagemaker.__version__}")
print(f"pandas version: {pd.__version__}")
print(f"sklearn version: {sklearn.__version__}")
[결과]
boto3 version: 1.37.9
sagemaker version: 2.241.0
pandas version: 2.2.3
sklearn version: 1.6.1
- 주요 모듈 가져오기
- sagemaker.sklearn: SageMaker에서 scikit-learn을 사용하기 위한 모듈
- sagemaker.local: SageMaker의 로컬 학습 기능을 위한 모듈
- pandas: 데이터 분석 및 처리를 위한 라이브러리
- sklearn.datasets: 예제 데이터셋을 제공하는 scikit-learn 모듈
- sklearn.model_selection: 모델 학습을 위한 데이터 분할 도구 제공
# 시스템 관련 라이브러리
import os
# AWS 관련 라이브러리
import boto3
import sagemaker
from sagemaker.sklearn import SKLearn # SageMaker에서 scikit-learn 모델 학습을 위한 클래스
from sagemaker.local import LocalSession # 로컬 환경에서 SageMaker 실행을 위한 세션
# 데이터 처리 및 머신러닝 라이브러리
import pandas as pd
from sklearn.datasets import load_iris # 붓꽃 데이터셋 로드
from sklearn.model_selection import train_test_split # 학습/테스트 데이터 분리
SageMaker 세션 확인
- 각 사용자에 맞게 해당 세션 가져확인
- 코드 설명
- LocalSession: SageMaker의 로컬 학습 기능을 위한 세션 객체
- config: 로컬 코드 실행을 위한 설정
- account: AWS 계정 ID를 가져오기 위한 boto3 클라이언트 사용
- role: SageMaker가 사용할 IAM 역할 ARN 설정
# SageMaker 로컬 세션 생성
sagemaker_local_session = LocalSession()
# 로컬 코드 실행을 위한 설정
sagemaker_local_session.config = {'local': {'local_code': True}}
# AWS 계정 ID 가져오기
account = boto3.client('sts').get_caller_identity().get('Account')
# SageMaker 서비스 카탈로그 역할 (사용하지 않음)
# role = f"arn:aws:iam::{account}:role/service-role/AmazonSageMakerServiceCatalogProductsUseRole"
# ML/DL 실행을 위한 IAM 역할 설정
role = f'arn:aws:iam::{account}:role/awsMLDLRole'
print(f"role: {role}")
[결과]
role: arn:aws:iam::YOURID:role/service-role/AmazonSageMakerServiceCatalogProductsUseRole
데이터 생성
- Scikit-Learn에 있는 iris 데이터를 가져와서 Local Project 경로에 data 폴더 만들고 각각 train.csv, test.csv 파일 생성
- Iris 데이터셋을 로드하여 학습/테스트용 CSV 파일로 저장
- 학습/테스트 데이터 분리 (train_test_split)
- 데이터 디렉토리 생성 및 CSV 파일로 저장
- train.csv: 학습용 데이터 (80%)
- test.csv: 테스트용 데이터 (20%)
# 현재 프로젝트 디렉토리 가져오기
home_dir = os.getcwd()
# 데이터 디렉토리가 없으면 생성
data_dir = os.path.join(home_dir, 'data')
os.makedirs(data_dir, exist_ok=True)
# 붓꽃 데이터셋 로드
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.DataFrame(iris.target, columns=['target'])
data = pd.concat([X, y], axis=1)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 특성과 타겟 변수 결합하여 저장
train_data = pd.concat([X_train, y_train], axis=1)
test_data = pd.concat([X_test, y_test], axis=1)
# CSV 파일로 저장
train_path = os.path.join(data_dir, 'train.csv')
test_path = os.path.join(data_dir, 'test.csv')
train_data.to_csv(train_path, index=False)
test_data.to_csv(test_path, index=False)
print(f"학습 데이터 저장 위치: {train_path}")
print(f"테스트 데이터 저장 위치: {test_path}")
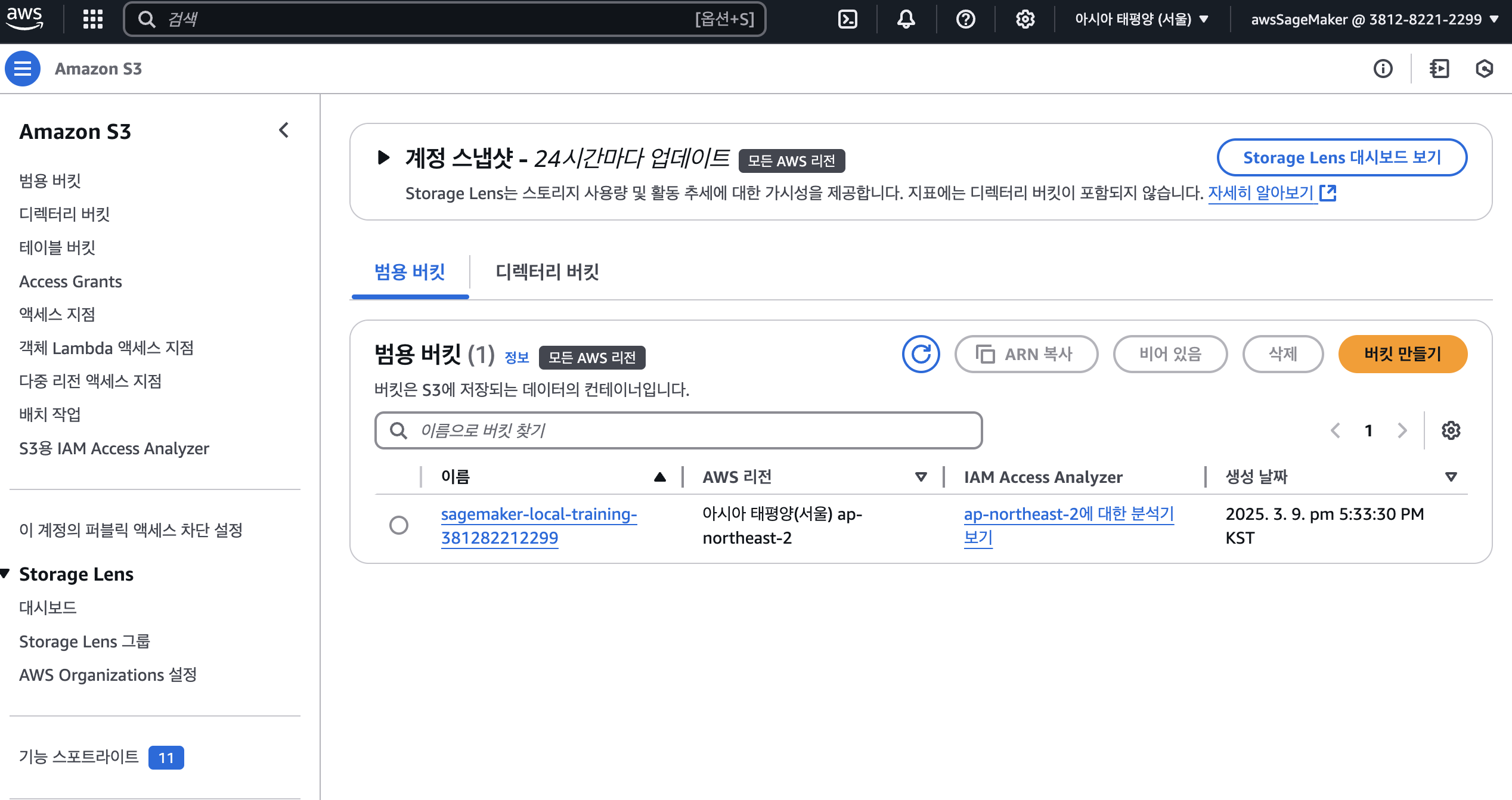
S3 Bucket 생성
- S3 버킷 생성 및 데이터 업로드
- 계정 ID를 포함한 유니크한 S3 버킷 이름 생성
- 버킷이 존재하지 않으면 새로 생성
- 학습/테스트 데이터를 S3에 업로드
- train.csv -> s3://{bucket_name}/data/train/train.csv
- test.csv -> s3://{bucket_name}/data/test/test.csv
- SageMaker 학습을 위한 입력 경로 설정
# S3 버킷 생성 및 데이터 업로드
bucket_name = f"sagemaker-local-training-{account}" # 계정 ID를 포함하여 유니크한 버킷 이름 생성
region = boto3.session.Session().region_name
s3_client = boto3.client('s3')
# 버킷이 존재하지 않으면 생성
try:
s3_client.head_bucket(Bucket=bucket_name)
print(f"버킷 {bucket_name}이(가) 이미 존재합니다")
except:
try:
if region == 'us-east-1':
s3_client.create_bucket(Bucket=bucket_name)
else:
s3_client.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={'LocationConstraint': region}
)
print(f"새로운 버킷 생성: {bucket_name}")
except Exception as e:
print(f"버킷 생성 중 오류 발생: {str(e)}")
# S3에 데이터 업로드
try:
# 학습 데이터(train.csv) 업로드
s3_train_path = 'data/train/train.csv'
s3_client.upload_file(train_path, bucket_name, s3_train_path)
print(f"학습 데이터를 s3://{bucket_name}/{s3_train_path}에 업로드했습니다")
# 테스트 데이터(test.csv) 업로드
s3_test_path = 'data/test/test.csv'
s3_client.upload_file(test_path, bucket_name, s3_test_path)
print(f"테스트 데이터를 s3://{bucket_name}/{s3_test_path}에 업로드했습니다")
# SageMaker 학습을 위한 입력 경로 업데이트
training_input_path = f"s3://{bucket_name}/{s3_train_path}"
print(f"\n학습 입력 경로가 다음으로 업데이트되었습니다: {training_input_path}")
except Exception as e:
print(f"S3에 파일 업로드 중 오류 발생: {str(e)}")
- Root 계정이 아닌 사용자 계정으로 접속해서 S3 버킷 대시보드 확인
모델 만들어 S3 Bucket에 저장하기
Local에서 모델 만들기
- 먼저 Local에서 모델을 만들어 Local에 저장한다.
- 로컬 환경에서 Scikit-learn 모델 학습
-
- 모델 아티팩트 디렉토리 생성
-
- 학습 데이터 로드 및 전처리
-
- RandomForestClassifier 모델 학습
-
- 학습된 모델을 joblib 파일로 저장
-
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import joblib
import os
# 모델 아티팩트 디렉토리가 없으면 생성
model_artifacts_dir = 'model_artifacts'
if not os.path.exists(model_artifacts_dir):
os.makedirs(model_artifacts_dir)
# 학습 데이터 로드
train_data = pd.read_csv(train_path, skiprows=1)
# 특성과 타겟 분리
X = train_data.iloc[:, :-1] # 마지막 열을 제외한 모든 열
y = train_data.iloc[:, -1] # 마지막 열이 타겟
X_cols = X.columns
# 모델 생성 및 학습
model = RandomForestClassifier(n_estimators=20, random_state=42)
model.fit(X, y)
# 모델 저장
model_path = os.path.join(model_artifacts_dir, 'sk_rf_model.joblib')
joblib.dump(model, model_path)
print(f"Model saved to {model_path}")
S3 모델 업로드
- 학습된 모델을 S3에 업로드하여 SageMaker에서 사용할 수 있도록 준비
- 모델 파일을 S3 버킷의 model_artifacts 폴더에 업로드
- 업로드된 모델은 SageMaker 엔드포인트 생성 시 사용됨
try:
# 학습된 모델을 S3에 업로드
s3_model_path = 'model_artifacts/sk_rf_model.joblib'
s3_client.upload_file(model_path, bucket_name, s3_model_path)
print(f"Uploaded model to s3://{bucket_name}/{s3_model_path}")
except Exception as e:
print(f"Error uploading model to S3: {str(e)}")
[결과]
Uploaded model to s3://sagemaker-local-training-381282212299/model_artifacts/sk_rf_model.joblib
Local에 저장된 모델 테스트
- 로컬에 저장된 모델의 성능을 테스트하는 과정
- 테스트 데이터를 로드하여 모델의 예측 정확도를 평가
- 학습 시 사용한 것과 동일한 특성(컬럼) 구조 유지
- 예측값과 실제값을 비교하여 모델의 성능 확인
# 테스트 데이터 불러오기
test_path = 'data/test.csv'
test_data = pd.read_csv(test_path, skiprows=1)
# 테스트 데이터의 특성과 타겟 분리
X_test = test_data.iloc[:, :-1] # 마지막 열을 제외한 모든 열
y_test = test_data.iloc[:, -1] # 마지막 열이 타겟
# 학습된 모델 불러오기
model_path = 'model_artifacts/sk_rf_model.joblib'
loaded_model = joblib.load(model_path)
# 테스트 데이터의 컬럼명을 학습 데이터와 동일하게 설정
X_test.columns = X_cols # 학습 데이터의 컬럼명 사용
# 예측 수행
predictions = loaded_model.predict(X_test)
# 정확도 계산 및 출력
accuracy = (predictions == y_test).mean()
print(f"테스트 정확도: {accuracy:.4f}")
# 처음 몇 개의 예측값과 실제값 출력
print("\n처음 5개의 예측값과 실제값 비교:")
for pred, actual in zip(predictions[:5], y_test[:5]):
print(f"예측값: {pred}, 실제값: {actual}")
S3에 저장된 모델 테스트
- S3에 저장된 모델의 성능을 테스트하는 과정
- S3에서 테스트 데이터와 모델을 다운로드
- 테스트 데이터를 모델에 적용하여 예측 수행
- 예측 정확도 계산 및 결과 확인
# S3에서 테스트 데이터 가져오기
try:
import tempfile
# 버킷 이름을 사용하여 S3 경로 구성
s3_test_path = f"s3://{bucket_name}/data/test/test.csv"
# S3 데이터를 다운로드할 임시 파일 생성
with tempfile.NamedTemporaryFile(delete=False, suffix='.csv') as tmp_file:
s3_client.download_file(bucket_name, 'data/test/test.csv', tmp_file.name)
# 다운로드한 CSV를 판다스 DataFrame으로 읽기
test_data_s3 = pd.read_csv(tmp_file.name, skiprows=1)
print(f"{s3_test_path}에서 테스트 데이터를 성공적으로 불러왔습니다")
print(f"테스트 데이터 크기: {test_data_s3.shape}")
except Exception as e:
print(f"S3에서 테스트 데이터를 불러오는 중 오류 발생: {str(e)}")
# 모델 가져오기
try:
# S3에서 모델 다운로드
local_model_path = os.path.join('model_artifacts', 'sk_rf_model.joblib')
s3_model_path = 'model_artifacts/sk_rf_model.joblib'
s3_client.download_file(bucket_name, s3_model_path, local_model_path)
print(f"S3에서 모델을 성공적으로 다운로드했습니다")
# 모델 불러오기
model = joblib.load(local_model_path)
# 테스트 데이터 준비 (타겟 컬럼 제외)
X_test_s3 = test_data_s3.iloc[:, :-1]
y_test_s3 = test_data_s3.iloc[:, -1]
# 테스트 데이터의 컬럼명을 학습 데이터와 동일하게 설정
X_test_s3.columns = X_cols
# 예측 수행
predictions = model.predict(X_test_s3)
# 정확도 계산 및 출력
accuracy = (predictions == y_test_s3).mean()
print(f"\n테스트 정확도: {accuracy:.4f}")
# 처음 몇 개의 예측값과 실제값 출력
print("\n처음 5개의 예측값과 실제값 비교:")
for pred, actual in zip(predictions[:5], y_test_s3[:5]):
print(f"예측값: {pred}, 실제값: {actual}")
except Exception as e:
print(f"S3 모델 테스트 중 오류 발생: {str(e)}")
SageMaker 클라우드 활용하여 모델 테스트
SageMaker 주요 설명 요약
- SageMaker 클라우드 환경에서 모델 학습
- SageMaker 세션 생성 및 S3 데이터 경로 설정
- SKLearn 추정기 구성 (ml.c5.xlarge 인스턴스 사용)
- 모델 학습 실행 및 S3에 모델 아티팩트 저장
- 학습된 모델을 엔드포인트로 배포하여 추론 서비스 구축
- 공식문서 참조 : https://sagemaker.readthedocs.io/en/stable/frameworks/sklearn/sagemaker.sklearn.html
- SageMaker에서
sagemaker.sklearn을 사용하면 Scikit-Learn을 기반으로 한 머신러닝 모델을 쉽게 학습시키고 배포할 수 있다. 공식 문서에 따르면, SageMaker는 Scikit-Learn을 컨테이너 환경에서 실행하며, 이를 위해 특정 구조를 따라야 한다. - SageMaker에서 Scikit-Learn 모델을 학습하고 배포할 때는 entry_point Python 파일을 필수적으로 지정해야 한다.
- 이 파일은 SageMaker가 모델 학습을 수행할 때 실행하는 코드이며, 다음 역할을 수행한다.
train.py 파일 생성
- 명령줄 인자 처리 (
argparse)n_estimators: 랜덤 포레스트 트리 개수 (기본값1, 기본 설정은 20)train: SageMaker의 학습 데이터 경로 (환경 변수SM_CHANNEL_TRAIN에서 가져옴)model_dir: 모델 저장 경로 (환경 변수SM_MODEL_DIR에서 가져옴)
- 데이터 로드 및 병합
train경로에서 모든 CSV 파일을 가져와 하나의pandas.DataFrame으로 병합- 데이터가 없을 경우 예외 처리
- 데이터 분할
train_x: 마지막 열을 제외한 나머지 데이터 (특성)train_y: 4번째 열을 레이블로 사용
- 모델 학습 및 저장
RandomForestClassifier를 사용하여 모델 학습 (n_estimators값 적용)- 학습된 모델을
joblib을 이용해model_dir에 저장
- 모델 로드 (
model_fn)- SageMaker가 배포할 때 모델을 불러오는 함수
joblib.load()를 사용해 저장된 모델을 복원하여 반환
import argparse # 명령줄 인자(argument) 처리를 위한 라이브러리
import pandas as pd # 데이터 처리를 위한 라이브러리
from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트 분류기
import joblib # 모델 저장 및 불러오기를 위한 라이브러리
import os # 파일 경로 및 환경 변수 처리를 위한 라이브러리
if __name__ == "__main__":
# 명령줄 인자 파서 설정
parser = argparse.ArgumentParser()
# 하이퍼파라미터 (트리 개수) 인자를 받음, 기본값 -1 (예외 처리용)
parser.add_argument('--n_estimators', type=int, default=-1)
# 학습 데이터 경로 (SageMaker 환경변수 SM_CHANNEL_TRAIN을 통해 자동 지정됨)
parser.add_argument("--train", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# 모델이 저장될 경로 (SageMaker 환경변수 SM_MODEL_DIR을 통해 자동 지정됨)
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# 인자 파싱
args = parser.parse_args()
# 학습 데이터 경로 및 설정된 하이퍼파라미터, 모델 저장 경로를 출력
print(f"Training data directory: {args.train}")
print(f"Number of estimators: {args.n_estimators}")
print(f"Model save directory: {args.model_dir}")
# 학습 데이터가 포함된 디렉토리 내 모든 파일 경로를 리스트로 가져오기
input_files = [os.path.join(args.train, file) for file in os.listdir(args.train)]
# 학습 데이터가 없을 경우 예외 발생 (학습 경로 지정 오류 또는 권한 문제 가능)
if len(input_files) == 0:
raise ValueError(
('There are no files in {}.\n'
'This usually indicates that the channel ({}) was incorrectly specified,\n'
'the data specification in S3 was incorrectly specified or the role specified\n'
'does not have permission to access the data.').format(args.train, "train")
)
# 모든 CSV 파일을 하나의 Pandas 데이터프레임으로 병합 (첫 번째 행을 스킵하여 헤더 제거)
raw_data = [pd.read_csv(file, header=None, engine="python", skiprows=1) for file in input_files]
train_data = pd.concat(raw_data)
# 데이터셋 분할: 레이블 (y)은 4번째 열, 특성 (X)은 마지막 열을 제외한 모든 열
train_y = train_data.iloc[:, 4] # 타겟 변수
train_x = train_data.iloc[:, :-1] # 피처 데이터
# 학습 데이터 출력 (디버깅용)
print(train_x)
print(train_y)
# 하이퍼파라미터 설정 (명령줄에서 제공된 값 사용)
n_estimators = args.n_estimators if args.n_estimators > 0 else 20 # 기본값 20
# 랜덤 포레스트 모델 초기화 및 학습 수행
model = RandomForestClassifier(n_estimators=n_estimators)
model.fit(train_x, train_y)
# 학습된 모델을 지정된 디렉토리에 저장
joblib.dump(model, os.path.join(args.model_dir, "model.joblib"))
# SageMaker가 모델을 로드할 때 사용하는 함수
def model_fn(model_dir):
"""SageMaker가 학습된 모델을 로드하는 함수
SageMaker가 모델을 배포할 때 `model_fn`을 호출하여 모델을 불러온다.
"""
# 저장된 모델 파일을 불러와 역직렬화 (Joblib을 이용하여 복원)
model = joblib.load(os.path.join(model_dir, "model.joblib"))
return model
모델 훈련 및 S3 Bucket에 저장
- SageMaker 클라우드 환경에서 모델 학습
- SageMaker 세션 생성 및 S3 데이터 경로 설정
- SKLearn 추정기 구성 (ml.c5.xlarge 인스턴스 사용)
- 모델 학습 실행 및 S3에 모델 아티팩트 저장
- 학습된 모델을 엔드포인트로 배포하여 추론 서비스 구축
# 모델 아티팩트(학습된 모델 파일) 저장 디렉토리 및 SageMaker 세션 생성
sagemaker_session = sagemaker.Session()
# 학습 데이터가 저장된 S3 경로 (train.csv 파일 위치)
training_input_path = f"s3://{bucket_name}/data/train/train.csv"
# 학습된 모델 아티팩트가 저장될 S3 경로
output_path = f"s3://{bucket_name}/model_artifacts"
# SageMaker Scikit-Learn Estimator 객체 생성
sk_estimator = SKLearn(
entry_point="train.py", # 학습 코드가 포함된 Python 파일 (SageMaker가 실행)
role=role, # SageMaker 실행 권한을 가진 IAM Role
instance_count=1, # EC2 인스턴스 개수 (단일 인스턴스에서 학습)
instance_type="ml.c5.xlarge", # 학습을 실행할 AWS EC2 인스턴스 유형 (CPU 기반)
py_version="py3", # Python 3 버전 사용
framework_version="1.2-1", # Scikit-Learn 프레임워크 버전 (로컬 scikit-learn 버전과 맞춰야 함)
sagemaker_session=sagemaker_session, # SageMaker 세션 연결
hyperparameters={"n_estimators": 4}, # 학습 하이퍼파라미터 (랜덤 포레스트 트리 개수)
output_path=output_path # 학습된 모델이 저장될 S3 경로 지정
)
# 학습 시작 (S3에 저장된 학습 데이터를 사용하여 `train.py` 실행)
sk_estimator.fit({"train": training_input_path})
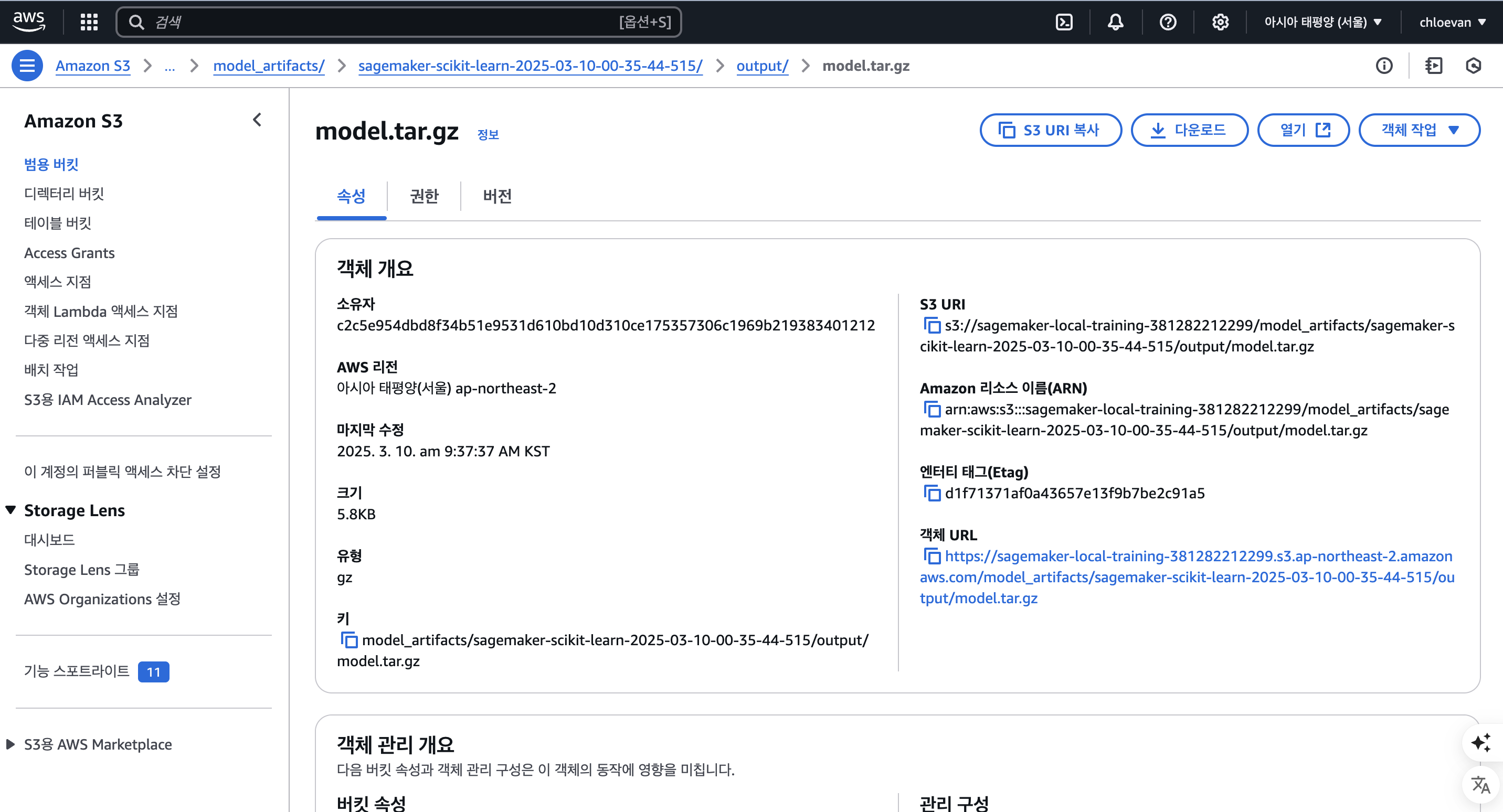
S3 Bucket에서 모델 가져오기
- SageMaker 클라우드 모델 테스트 과정
- 학습된 모델을 SageMaker 엔드포인트로 배포하여 실시간 추론 서비스 구축
- 테스트 데이터를 사용하여 배포된 모델의 성능 평가
- 테스트 완료 후 비용 절감을 위해 엔드포인트 삭제
# SageMaker SKLearn 모델 클래스 임포트
from sagemaker.sklearn.model import SKLearnModel
# S3에 저장된 학습된 모델 아티팩트 경로 지정
model_data = f"s3://{bucket_name}/model_artifacts/sagemaker-scikit-learn-2025-03-10-00-35-44-515/output/model.tar.gz"
# SageMaker 세션 생성
sagemaker_session = sagemaker.Session()
# SKLearn 모델 객체 생성
sk_model = SKLearnModel(
model_data=model_data, # 모델 데이터 경로
role=role, # IAM 역할
framework_version='1.2-1', # SKLearn 프레임워크 버전
entry_point='train.py', # 모델 추론 코드가 있는 스크립트
sagemaker_session=sagemaker_session # SageMaker 세션
)
# 모델을 엔드포인트로 배포 (실시간 추론용)
predictor = sk_model.deploy(initial_instance_count=1, instance_type="ml.m5.xlarge") # 인스턴스 1개로 ml.m5.xlarge 타입 사용

모델 테스트
- 배포된 엔드포인트에 테스트 데이터를 적용하여 예측 수행
- 테스트 데이터를 로드하여 배포된 엔드포인트에 전달
- 예측 결과의 정확도를 계산하여 모델 성능 평가
- 테스트 완료 후 엔드포인트 삭제하여 비용 절감
# 배포된 엔드포인트 테스트
from sklearn.metrics import accuracy_score
# 테스트 데이터 로드
test_data = pd.read_csv(os.path.join(data_dir, 'test.csv'))
X_test = test_data.drop('target', axis=1)
# 배포된 엔드포인트를 사용하여 예측 수행
predictions = predictor.predict(X_test.values)
print(predictions)
# 정확도 계산 및 출력
test_accuracy = accuracy_score(test_data['target'], predictions)
print(f"배포된 모델의 테스트 정확도: {test_accuracy:.4f}")
# 지속적인 비용 발생을 방지하기 위해 엔드포인트 삭제
predictor.delete_endpoint()
최종 프로젝트 파일
- 최종 파일 경로는 다음과 같다.
.
├── data
├── local_training.ipynb
├── model_artifacts
│ └── sk_rf_model.joblib
├── requirements.txt
└── train.py
