(AWS Project) BigData with Hadoop 05 - Hive Script 연습 예제
Page content

I. Getting Started
- 처음 이 페이지를 방문했다면, 반드시 사전작업을 완료하기를 바란다.
II. What to do now
Hive Script를 제출하는 방법에 대해 준비하였다.- 를러스터를 생성할 때 단계를 지정하거나 마스터 노드에 연결하고 로컬 파일 시스템에서 스크립트를 생성하고 명렁어를 사용하여 실행할 수 있다.
III. 데이터와 스크립트에 대한 이해
- 본 튜토리얼에서 사용하는 샘플 데이터와 스크립트는 Amazon S3에서 사용이 가능하다.
- 샘플 데이터는 일련의 Amazon CloudFront 액세스 로그 파일이다.
-
- CloudFront 및 로그 파일 형식에 대한 자세한 정보는 다음을 확인한다.
- Amazon CloudFront Developer Guide
- 데이터의 위치는 아래와 같이 저장된다.
s3://region.elasticmapreduce.samples/cloudfront/
- 여기에서
region은 사용자의region이다.
(1) 스크립트 제출 시
- script를 제출할 때 위치를 입력하면 스크립트가 클라우드 프런트/데이터 부분을 추가하기 때문에 생략한다.
CloudFront로그 파일의 각 항목은 다음과 같은 형식으로 단일 사용자 요청에 대한 세부 정보를 제공한다.
2014-07-05 20:00:00 LHR3 4260 10.0.0.15 GET eabcd12345678.cloudfront.net /test-image-1.jpeg 200 - Mozilla/5.0%20(MacOS;%20U;%20Windows%20NT%205.1;%20en-US;%20rv:1.9.0.9)%20Gecko/2009040821%20IE/3.0.9
- 샘플 스크립트는 지정된 기간 동안 운영 체제당 총 요청 수를 계산한다.
- 이 스크립트는 데이터 웨어하우징 및 분석에 SQL과 같은 스크립팅 언어인 HiveQL을 사용한다.
- 스크립트는 Amazon S3에
s3://region.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q에 저장되며, 여기서 지역은 사용자의 지역이다.
(2) 스크립트 작성 시
- 샘플 Hive 스크립트는 다음을 수행한다.
Cloudfront_logs라는Hive 테이블 스키마를 생성한다. 하이브 테이블에 대한 자세한 정보는 다음에서 확인한다. Hive Tutorial- 내장된 정규식 직렬화기/디세리알라이저(RegEx SerDe)를 사용하여 입력 데이터를 구문 분석하고 테이블 스키마를 적용한다.
- 자세한 내용은 Hive wiki의 SerDe를 참조하십시오.
Cloudfront_logs테이블에 대해HiveQL쿼리를 실행하고 지정한Amazon S3출력 위치에 쿼리 결과를 기록하십시오.
Hive_CloudFront.q스크립트의 내용은 다음과 같다.${INPUT}및${OUTPUT}변수는 스크립트를 단계별로 제출할 때 지정하는 Amazon S3 위치로 대체된다.- 이 스크립트와 같이
Amazon S3의 데이터를 참조하면,Amazon EMR은 입력 데이터를 읽고 출력 데이터를 쓰기 위해EMR파일 시스템(EMRFS)을 사용한다.
-- Summary: This sample shows you how to analyze CloudFront logs stored in S3 using Hive
-- Create table using sample data in S3. Note: you can replace this S3 path with your own.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
DateObject Date,
LocalTime STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
OS String,
Browser String,
BrowserVersion String
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
) LOCATION '${INPUT}/cloudfront/data';
-- Total requests per operating system for a given time frame
INSERT OVERWRITE DIRECTORY '${OUTPUT}/os_requests/' SELECT os, COUNT(*) count FROM cloudfront_logs WHERE dateobject BETWEEN '2014-07-05' AND '2014-08-05' GROUP BY os;
IV. Submit the Hive Script as a Step
- 콘솔을 사용하여 하이브 스크립트를 클러스터에 제출하려면 단계 추가 옵션을 사용한다.
- Hive 스크립트와 샘플 데이터는 이미 앞에서 생성한 Amazon S3에 업로드 되며, 출력 위치를 앞에서 지정한 폴더로 지정한다.
(1) Tutorial
- 지금까지 정상적으로
Tutorial을 학습했다면, Console 창을 연다. - 클러스터 목록에서 클러스터의 이름을 선택하십시오. 클러스터가
대기상태인지 확인한다. - 단계를 선택한 다음
[단계]-[단계추가]를 차례대로 선택한다.-
단계 클릭
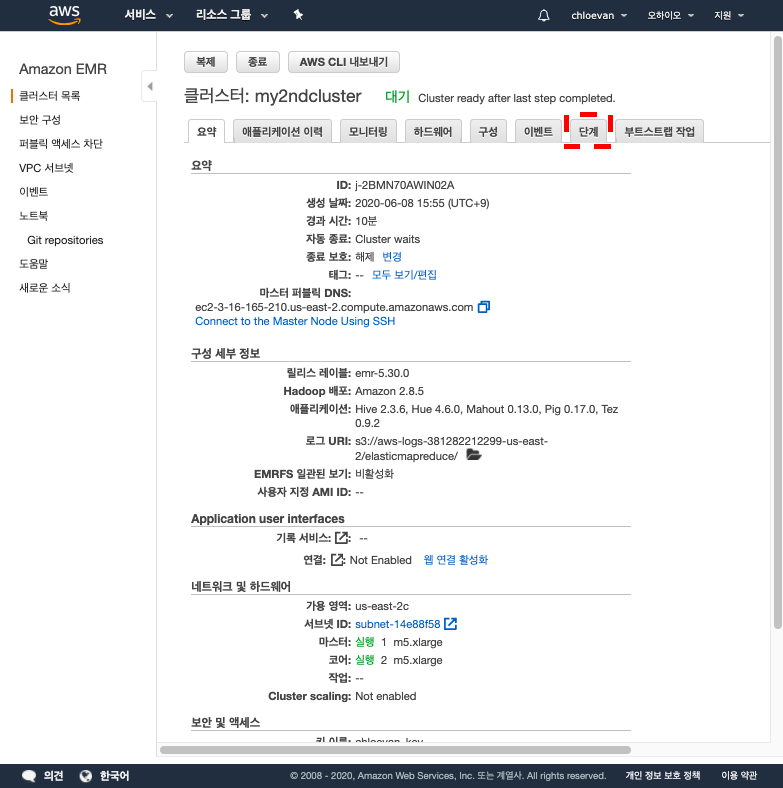
-
단계 추가 클릭
-

-
다음 지침에 따라 단계를 구성한다.
Step Type에서 하이브 프로그램을 선택한다.- 이름에 대해 기본값을 그대로 두거나 새 이름을 입력하십시오. 클러스터에 여러 단계가 있는 경우, 이름을 통해 해당 단계를 추적하는데 도움을 준다.
- 스크립트 S3 위치의 경우
s3://your_region.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q를 입력한다. 이 떄,region을 본인의region으로 바꾼다. 지역 및 해당 지역 식별자 목록에 관한 자세한 사항은 AWS Regions and Endpoints for Amazon EMR
-
입력 S3 위치의 경우s3://your_region.elasticmapreduce.samples를 입력한다. -
출력 S3 위치의 경우 Amazon S3 버킷 생성에서 생성한 출력 버킷을 입력하거나 찾아본다. -
실패 시 액션의 경우 기본 옵션인 계속을 사용한다.
- 이는 단계가 실패하면 클러스터가 계속 실행되고 후속 단계를 처리하도록 지정한다.
- Cancel and wait 옵션은 실패한 단계를 취소하고, 이후 단계를 실행하지 않고, 클러스터가 계속 실행되도록 지정한다.
- 클러스터 종료 옵션은 단계가 실패할 경우 클러스터를 종료해야 함을 명시한다.
- 필자가 작성한 포맷은 다음과 같다.
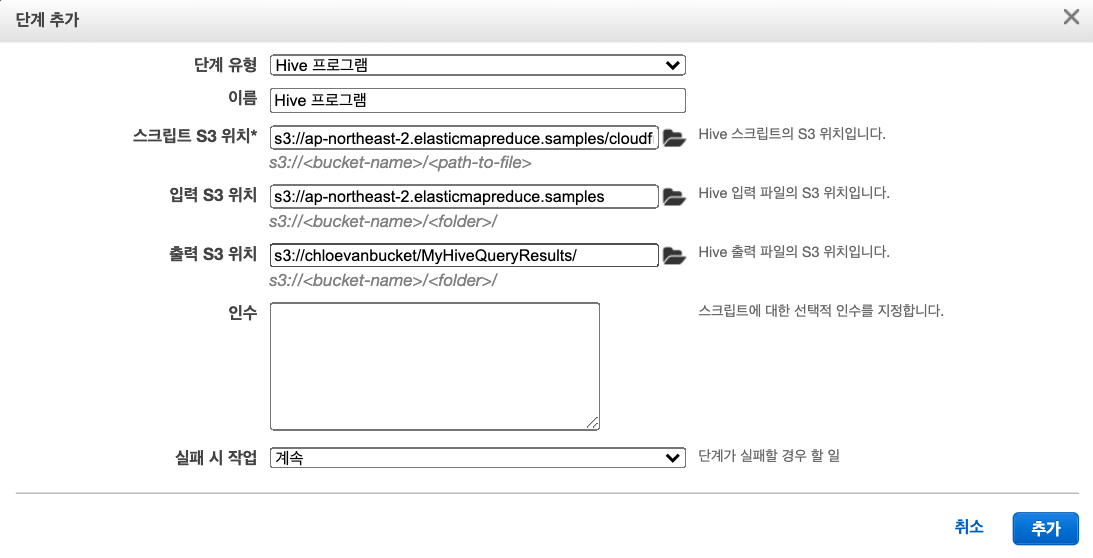
-
추가를 선택한다. 단계가 보류 중 상태로 콘솔에 나타난다.
-
단계가 실행됨에 따라 단계의 상태는 보류 중에서 실행 중에서 완료됨으로 변경된다.
- 상태를 업데이트하려면 필터 오른쪽에 있는 새로 고침 아이콘을 선택하십시오. 이 Script를 실행하는데 약 1분이 걸린다.
-
완성되면
단계 Tab에서 완료됨을 확인할 수 있다.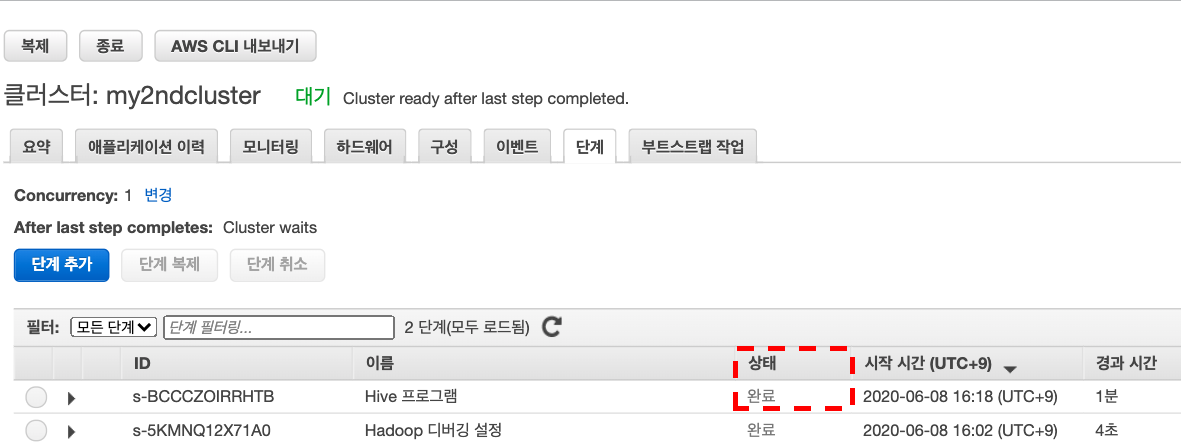
V. 결과 보기
- 단계가 성공적으로 완료되면 하이브 쿼리 출력은 단계를 제출할 때 지정한 Amazon S3 출력 폴더에 텍스트 파일로 저장된다.
- 우선 S3 console창으로 다시 들어간다.
- 버킷 이름을 선택한 다음 이전에 설정한 폴더를 선택한다.
- 쿼리는
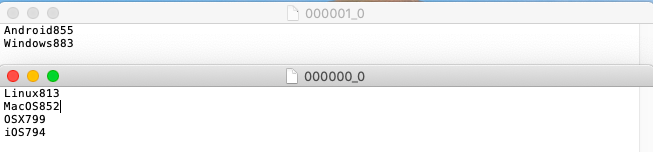
os_requests라는 출력 폴더의 폴더에 결과를 기록한다. 해당 폴더를 선택하십시오. 폴더에는000000_0이라는 하나의 파일이 있어야 한다. 하이브 쿼리 결과가 들어 있는 텍스트 파일이다.
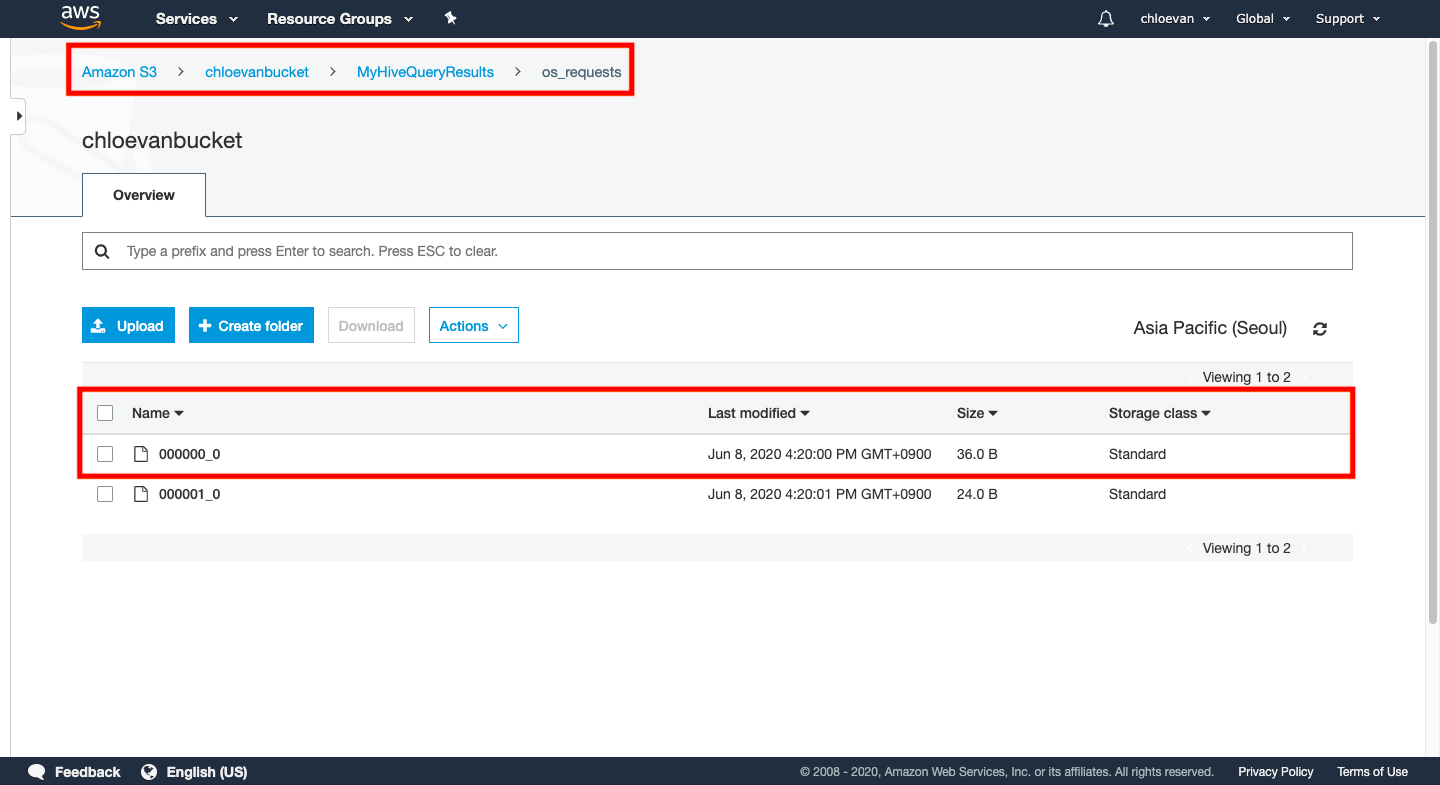
- 이 때 다운로드를 받아서 실제 데이터가 잘 출력되었는지 확인한다.
VI. 실행을 완료한 뒤에는 반드시 S3 등을 삭제해야 한다.
- 지금까지 진행한 것은
Cluster를 구성하고Hive Script를 실행하여S3에 데이터를 출력하여 저장하는 것까지 실행하였다.
