(AWS Project) BigData with Hadoop 03 - Amazon EMR Cluster 시작
Page content

I. Getting Started
- 처음 이 페이지를 방문했다면, 반드시 사전작업을 완료하기를 바란다.
II. What to do now
- 이번 포스트에서는 비교적 간단하게 빅데이터 클러스터를 시작하는 과정을 진행한다. 막상 해보면 어려운 것은 아니지만, 언제나 그렇듯이 처음 할 때는 늘 시행착오를 겪게 마련이다.
Amazon EMR console창에 있는Quick Options을 사용한다.Quick Options에 있는 다양한 절차들에 대해 확인이 필요하면 Summary of Quick Options에서 확인해본다.
III. Sample Cluster 시작
- 먼저
AWS에 있는AWS Management Console을 클릭하여 실행하도록 한다. (아래 그림 참조)

- 위 그림에서
클러스터 생성을 클릭한다.
-
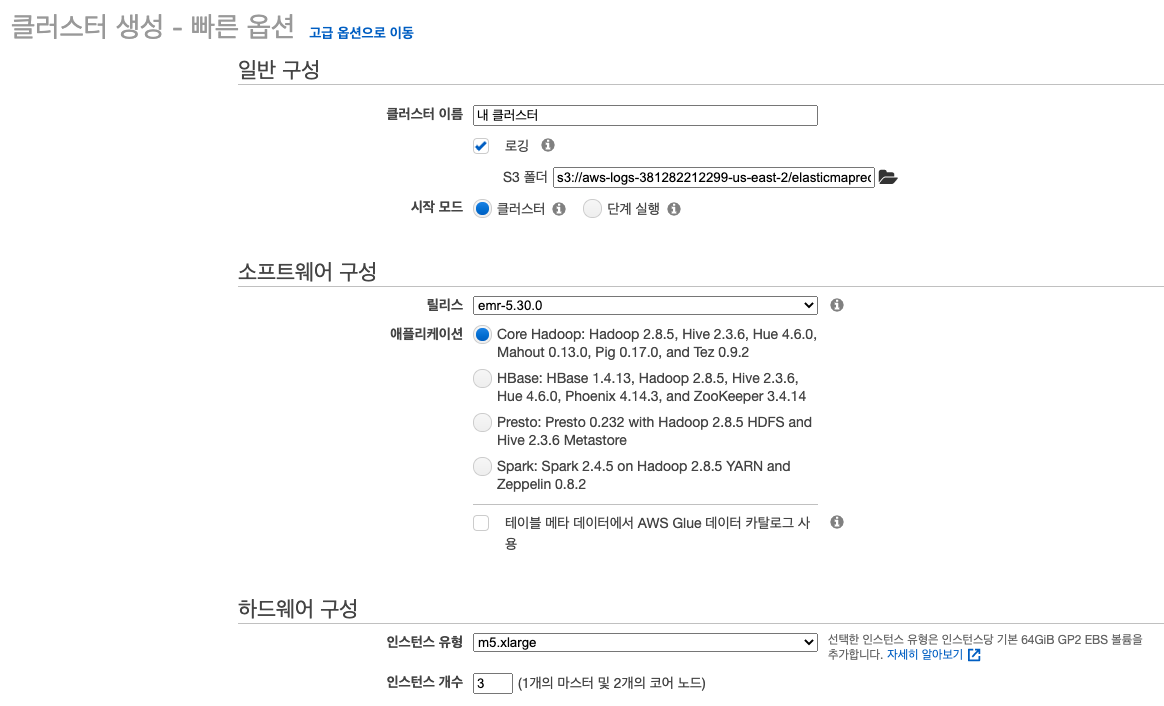
이 부분이 매우 중요하다.- 우선 현재 보는 화면은 빠른 옵션 창이다.
- 기본적으로
default옵션을 그대로 사용한다. - 단,
클러스터 이름은 본인만의 식별이름을 작성하면 된다. (필자는my1stEMRcluster) 라고 작성하였다.
-
현재 화면에서 스크롤바를 내리면
보안 및 엑세스 Tap이 존재한다.

- 이 때,
EC2 키 페어의 옵션 메뉴를 클릭하면 보시는 화면처럼 사전준비 작업시 만들었던EC2 key pair가 본 화면에서 확인할 수 있다. - 만약, 이 부분이 없다면 처음부터 다시 시작해야 함을 명심하자.
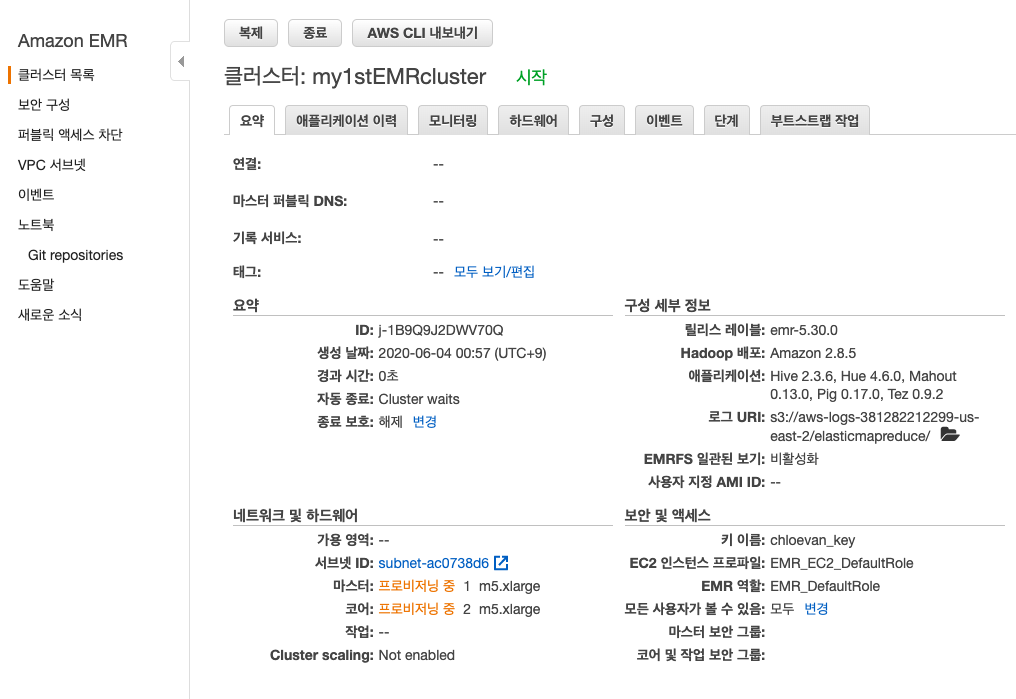
- 모든 준비가 완성되었다면, 클러스터를 생성하자. (아래 그림 참조)
IV. 추가 작업 및 확인 사항
-
매우 간단하게 클러스터가 완성되었다. 보통, 오픈소스에서 하둡을 구성하려면 환경설정을 다 잡아줘야 한다. 이 파트는 사실상
데이터분석의 영역이라기 보다는데이터엔지니어링의 영역이라고 보는 것이 맞다. -
그러나, 클라우드를 활용하면 이제
데이터분석가도데이터엔지니어링의 세계에 들어올 수 있게 되었다. -
현재 보는 화면에서 [하드웨어]를 클릭한뒤, 노드 유형 및 이름을 확인한다.
- 여기에서 이제,
Provisioning,Bootstrapping, 그리고waiting의 데이터의 자원인 순환하는 시스템을 보게 된다.
- 여기에서 이제,
-
Amazon의 EMR 시스템의 전반적인 이해를 위해 간단한 영상을 준비했다.
-
영어버전
-
한국어버전
-
-
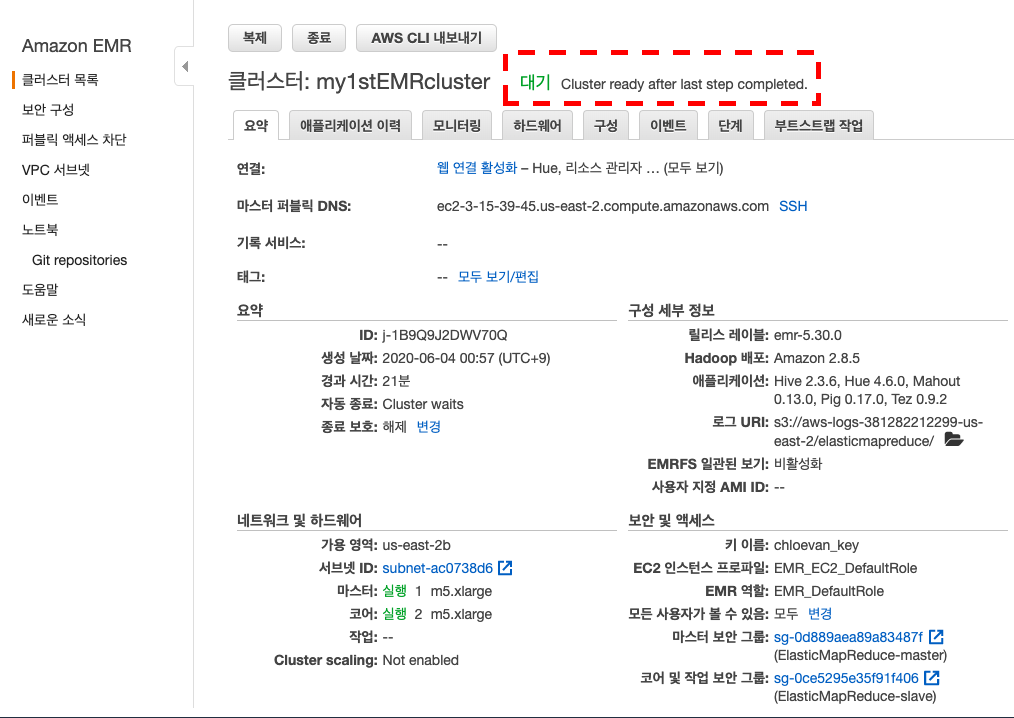
위 영상을 보고 나면
시작에서대기로 바뀌어 있을 것이다. 그러면 이제Step 3단계로 넘어가면 된다.
Note: 만약 여기에서 작업을 멈춘다면, 꼭 EMR은 삭제하도록 하자. (상단에
종료버튼을 누르기만 하면 된다.)
