CNN with Computer Vision
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

공지
-
본 Tutorial은 교재
핸즈온 머신러닝 2판를 활용하여 본 강사로부터 국비교육 강의를 듣는 사람들에게 자료 제공을 목적으로 제작하였습니다.. -
강사의 주관적인 판단으로 압축해서 자료를 정리하였기 때문에, 자세하게 공부를 하고 싶은 분은 반드시 교재를 구매하실 것을 권해드립니다.
책 정말 좋습니다! 꼭 구매하세요!
![]()
개요
- 인경 신경망은(
Artificial Neural Network)을 촉발시킨 근원임- 뇌에 있는 생물학적 뉴런의 네트워크에서 영감을 받은 머신러닝 모델
- 활용예제
- 수백만개의 이미지 분류
- 수백만개의 비디어 추천
- 매우 복잡한 문제를 풀 때 유용한 머신러닝 모델
- Keras API
- 케라스는 신경망 구축, 훈련, 평가, 실행을 목적으로 설계된 API이자, 프레임워크
(1) 주요 환경 설정
- 주요 환경 설정은 아래와 같이 정의합니다.
# Python ≥3.5 is required
import sys
assert sys.version_info >= (3, 5)
# Scikit-Learn ≥0.20 is required
import sklearn
assert sklearn.__version__ >= "0.20"
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
IS_COLAB = True
except Exception:
IS_COLAB = False
# TensorFlow ≥2.0 is required
import tensorflow as tf
from tensorflow import keras
assert tf.__version__ >= "2.0"
if not tf.config.list_physical_devices('GPU'):
print("No GPU was detected. CNNs can be very slow without a GPU.")
if IS_COLAB:
print("Go to Runtime > Change runtime and select a GPU hardware accelerator.")
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
tf.random.set_seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "cnn"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
I. CNN 구조
- CNN의 가장 중요한 구성 요소는
합성곱 층이다.- 첫번째 합성공 층의 뉴런은 모든 픽셀에 연결하는 것이 아니라 합성곱 층 뉴런의 수용장 안에 있는 픽셀에만 연결됨
- 두번째 합성공 층에 있는 각 뉴런은 첫번째 층의 작은 사각 영역 안에 위치한 뉴런에 연결
- 저수준 특성에서 고수준 특성으로 조합한다.
- 제로 패딩: 높이와 너비를 이전 층과 같게 하기 위해 입력의 주위에 0을 추가
- 스트라이드: 수용장 사이에 간격을 두어 큰 입력층을 훨씬 작은 층에 연결하는 것도 가능한데, 이렇게 하여 모델의 계산 복잡도를 크게 낮춤
- 훈련하는 동안 합성곱 층이 자동으로 해당 문제에 가장 유용한 필터를 찾을 수 있도록 도와주는
특성 맵(feature map)을 만듬 - CNN의 가장 큰 목적은 특성을 찾는 과정이다.
II. 텐서플로 구현
- 각각의 입력 이미지는 보통 [높이, 너비, 채널] 형태의 3D 형태의 텐서로 표현됨.
- 하나의 미니배치는 [미니배치 크기, 높이, 너비, 채널] 형태의 4D 텐서로 표현됨.
(1) 텐서플로를 활용한 간단한 이미지 처리
- 간단한 이미지를 불러와서 확인하는 예제를 구현한다.
- 먼저 함수를 정의하자.
def plot_image(image):
plt.imshow(image, cmap="gray", interpolation="nearest")
plt.axis("off")
def plot_color_image(image):
plt.imshow(image, interpolation="nearest")
plt.axis("off")
- 이제
load_sample_images()를 사용하려면pip로pillow패키지를 설치한다.
import numpy as np
from sklearn.datasets import load_sample_image
# Load sample images
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
# 2개의 필터를 만든다.
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # 수직선
filters[3, :, :, 1] = 1 # 수평선
outputs = tf.nn.conv2d(images, filters, strides=1, padding="SAME")
plt.imshow(outputs[0, :, :, 1], cmap="gray") # 첫번째 이미지의 두번째 특성 맵을 그린다.
plt.show()

for image_index in (0, 1):
for feature_map_index in (0, 1):
plt.subplot(2, 2, image_index * 2 + feature_map_index + 1)
plot_image(outputs[image_index, :, :, feature_map_index])
plt.show()

- 이번에는 데이터를 자르는 함수를 정의 후 사용해본다.
def crop(images):
return images[150:220, 130:250]
plot_image(crop(images[0, :, :, 0]))
save_fig("china_original", tight_layout=False)
plt.show()
for feature_map_index, filename in enumerate(["china_vertical", "china_horizontal"]):
plot_image(crop(outputs[0, :, :, feature_map_index]))
save_fig(filename, tight_layout=False)
plt.show()
Saving figure china_original

Saving figure china_vertical

Saving figure china_horizontal

- 위 코드에 관한 개별적인 설명은
교재 550p를 확인한다. - tf.nn.conv2d의 설명도 같은 페이지에 있기는 하지만 가급적 메뉴얼을 확인해보자.
(2) CNN을 활용한 예제
- 첫번째 예에서는 필터를 직접 설정했다. 그러나,
CNN에서는 보통 훈련 가능한 변수로 필터를 정의하는데,keras.layers.Conv2D층을 사용한다.
conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1,
padding="SAME", activation="relu")
plot_image(crop(outputs[0, :, :, 0]))
plt.show()

- 이 코드는 3x3 크기의 32개의 필터와 수평 수직 방향으로 스트라이드 1,
same패딩을 사용하는 Conv2D 층을 만들고, 출력을 위해ReLU활성화 함수를 적용한다.
(3) 메모리 요구 사항
- 합성곱 층이 많은 양의 RAM을 필요로 한다
- 예시: 특성 맵 200개를 만드는 합성곱 층
- 200 x 150 x 100 x 32 = 9천 6백만 비트(약 12MB)
- 100개의 샘플인 경우 1.2GB RAM 사용
- 예시: 특성 맵 200개를 만드는 합성곱 층
III. 풀링층
- 입력 이미지에 대한 일종의 축소본을 만드는 것
- 풀링층 생성의 몇가지 조건
- 이전과 동일하게 크기, 스트라이드, 패딩 유형 지정
- 풀링 뉴런은 가중치가 없음
- 최대 또는 평균과 같은 합산 함수를 사용해 입력값을 더한다.
- 이렇게 해서 얻을 것 있는 장점은
- 계산량, 메모리 사용량, 파라미터 수를 감소 시킨다.
- 최대 풀링은 작은 변화에도 일정 수준의 불변성을 만들어 준다. (회전과 확대, 축소에 대해 약간의 불변성 제공)
- 이제 텐서플로로 구현을 한다.
(1) 최대 풀링층 구현
- 텐서플로에서 최대 풀링 층을 구현하는 것은 매우 쉽다.
max_pool = keras.layers.MaxPool2D(pool_size=2)
cropped_images = np.array([crop(image) for image in images], dtype=np.float32)
output = max_pool(cropped_images)
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_title("Input", fontsize=14)
ax1.imshow(cropped_images[0]) # plot the 1st image
ax1.axis("off")
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title("Output", fontsize=14)
ax2.imshow(output[0]) # plot the output for the 1st image
ax2.axis("off")
save_fig("china_max_pooling")
plt.show()
Saving figure china_max_pooling

- 사진이 흐려지기는 했지만, 크기 및 전체적인 색상은 유지되는 것을 확인할 수 있다.
depth-wise pooling을 활용하면 색상에 변화를 줄 수 있음
class DepthMaxPool(keras.layers.Layer):
def __init__(self, pool_size, strides=None, padding="VALID", **kwargs):
super().__init__(**kwargs)
if strides is None:
strides = pool_size
self.pool_size = pool_size
self.strides = strides
self.padding = padding
def call(self, inputs):
return tf.nn.max_pool(inputs,
ksize=(1, 1, 1, self.pool_size),
strides=(1, 1, 1, self.pool_size),
padding=self.padding)
depth_pool = DepthMaxPool(3)
with tf.device("/cpu:0"): # there is no GPU-kernel yet
depth_output = depth_pool(cropped_images)
depth_output.shape
TensorShape([2, 70, 120, 1])
plt.figure(figsize=(12, 8))
plt.subplot(1, 2, 1)
plt.title("Input", fontsize=14)
plot_color_image(cropped_images[0]) # plot the 1st image
plt.subplot(1, 2, 2)
plt.title("Output", fontsize=14)
plot_image(depth_output[0, ..., 0]) # plot the output for the 1st image
plt.axis("off")
plt.show()

(2) 평균 풀링 층 구현
- 최대값이 아닌 평균을 계산하며 원리는 최대 풀링층과 똑같음
avg_pool = keras.layers.AvgPool2D(pool_size=2)
output_avg = avg_pool(cropped_images)
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_title("Input", fontsize=14)
ax1.imshow(cropped_images[0]) # plot the 1st image
ax1.axis("off")
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title("Output", fontsize=14)
ax2.imshow(output_avg[0]) # plot the output for the 1st image
ax2.axis("off")
plt.show()

IV. CNN 구조
- 전형적인 CNN 구조는 아래와 같습니다.
- 합성곱 층
- Pooling 층
- Repeat
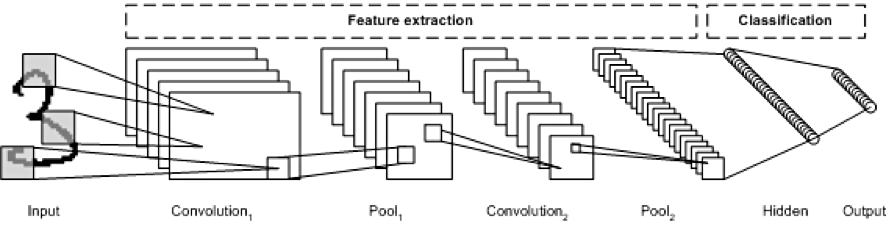
- 위 과정을 진행하면서 이미지는 점점 작아지지만, 합성곱 층 때문에 일반적으로 점점 더 깊어진다.
- 클래스 확률을 추정하기 위해 소프트맥스 층에서 예측을 출력함
(1) Fashion MNIST 예제 구현
- 이제 CNN으로 다시한번 구현해본다.
(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
X_train, X_valid = X_train_full[:-5000], X_train_full[-5000:]
y_train, y_valid = y_train_full[:-5000], y_train_full[-5000:]
X_mean = X_train.mean(axis=0, keepdims=True)
X_std = X_train.std(axis=0, keepdims=True) + 1e-7
X_train = (X_train - X_mean) / X_std
X_valid = (X_valid - X_mean) / X_std
X_test = (X_test - X_mean) / X_std
X_train = X_train[..., np.newaxis]
X_valid = X_valid[..., np.newaxis]
X_test = X_test[..., np.newaxis]
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
from functools import partial
DefaultConv2D = partial(keras.layers.Conv2D,
kernel_size=3, activation='relu', padding="SAME")
model = keras.models.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(pool_size=2),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
keras.layers.MaxPooling2D(pool_size=2),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
keras.layers.MaxPooling2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dense(units=128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=10, activation='softmax'),
])
- 이미지가 아주 크지 않아서 64개의 큰 필터 (7 x 7)와 스트라이드 1을 사용한다.
- 풀링 크기가 2인 최대 풀링 층을 추가하여 공간 방향 차원을 절반으로 줄인다.
- 이와 동일한 구조를 두번 반복한다.
- 이미지가 클 때는 이러한 구조를 더 많이 반복이 가능함
- CNN이 출력층에 다다를수록 필터 개수가 늘어남
- 작은 동심원, 수평선 순
- 그 다음이 두 개의 은닉층과 하나의 출력층으로 구성된 완전 연결 네트워크
- 밀집 네트워크는 샘플의 특성으로
1D배열을 기대하므로 입력을 일렬로 펼쳐야 함. - 밀집 층 사이에 과대적합을 줄이기 위해
50%의 드롭아웃 비율을 가진 드롭아웃 층을 추가함.
- 밀집 네트워크는 샘플의 특성으로
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
score = model.evaluate(X_test, y_test)
X_new = X_test[:10] # pretend we have new images
y_pred = model.predict(X_new)
Epoch 1/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.7195 - accuracy: 0.7504 - val_loss: 0.3787 - val_accuracy: 0.8600
Epoch 2/10
1719/1719 [==============================] - 35s 20ms/step - loss: 0.4219 - accuracy: 0.8589 - val_loss: 0.3188 - val_accuracy: 0.8812
Epoch 3/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.3694 - accuracy: 0.8760 - val_loss: 0.3300 - val_accuracy: 0.8848
Epoch 4/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.3366 - accuracy: 0.8856 - val_loss: 0.2928 - val_accuracy: 0.8916
Epoch 5/10
1719/1719 [==============================] - 36s 21ms/step - loss: 0.3100 - accuracy: 0.8951 - val_loss: 0.3052 - val_accuracy: 0.8934
Epoch 6/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.2943 - accuracy: 0.8988 - val_loss: 0.2637 - val_accuracy: 0.9052
Epoch 7/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.2852 - accuracy: 0.9016 - val_loss: 0.2722 - val_accuracy: 0.9054
Epoch 8/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.2761 - accuracy: 0.9062 - val_loss: 0.2617 - val_accuracy: 0.9078
Epoch 9/10
1719/1719 [==============================] - 35s 20ms/step - loss: 0.2656 - accuracy: 0.9097 - val_loss: 0.2675 - val_accuracy: 0.9082
Epoch 10/10
1719/1719 [==============================] - 35s 21ms/step - loss: 0.2541 - accuracy: 0.9135 - val_loss: 0.2777 - val_accuracy: 0.8990
313/313 [==============================] - 2s 6ms/step - loss: 0.3127 - accuracy: 0.8977
V. CNN의 변화와 역사
- 최근 몇년간 이 기본 구조에서 다양한 변종이 개발되었음
- 자세한 내용은 교재 참조 (page 560)
- LeNet (1998) by 얀 르쿤
- AlexNet (2012) by 알랙스 크리체프스키, 일리아 서스케버, 제프리 힌턴
- 드롭아웃, 데이터 증식 수행, LRN (경쟁적 정규화)
- GoogLeNet (2014) by 크리스찬 세게디
- 인셉션(=영화) 모듈이라는 서브 네트워크를 가짐
- AlexNet보다 10배 적은 파라미터를 가지나 성능 좋음
- VGGNet (2014) by 캐런 시몬얀, 앤드루 지서만
- 매우 단순한 구조 (합성곱, 풀링 층)
- ResNet (2015) by 카이밍 허
- 더 적은 파라미터를 사용해 점점 더 깊은 네트워크 구현
- Xception (2016) by 케라스 창시자 프랑수아 숄레
- GoogLeNet과 RestNet 아이디어 합침
- 기존 공간상의 패턴과 채널 사이의 패턴을 동시에 잡는 필터 사용
- SENet (2017) by Jie Hu et al.,
SE 블록이라는 작은 신경망을 추가하여 성능 향상
(1) 케라스 사용한 ResNet-34 CNN 구현
- 케라스를 사용하여 직접
ResNet-34모델 구현한다.
DefaultConv2D = partial(keras.layers.Conv2D, kernel_size=3, strides=1,
padding="SAME", use_bias=False)
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
DefaultConv2D(filters, strides=strides),
keras.layers.BatchNormalization(),
self.activation,
DefaultConv2D(filters),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
DefaultConv2D(filters, kernel_size=1, strides=strides),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
- 이 코드는 [그림 14-18]을 구현한 것 (p. 571)
model = keras.models.Sequential()
model.add(DefaultConv2D(64, kernel_size=7, strides=2,
input_shape=[28, 28, 1]))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="SAME"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
- 위 코드는 네트워크를 구현한 것이다.
- 이 코드에서 조금 복잡한 부분은
ResidualUnit층을 더하는 반복 루프. - 이 코드를 통해
ILSVRC 2015년 대회 우승 모델이 되었음.
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_77 (Conv2D) (None, 14, 14, 64) 3136
_________________________________________________________________
batch_normalization_72 (Batc (None, 14, 14, 64) 256
_________________________________________________________________
activation_2 (Activation) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
residual_unit_32 (ResidualUn (None, 7, 7, 64) 74240
_________________________________________________________________
residual_unit_33 (ResidualUn (None, 7, 7, 64) 74240
_________________________________________________________________
residual_unit_34 (ResidualUn (None, 7, 7, 64) 74240
_________________________________________________________________
residual_unit_35 (ResidualUn (None, 4, 4, 128) 230912
_________________________________________________________________
residual_unit_36 (ResidualUn (None, 4, 4, 128) 295936
_________________________________________________________________
residual_unit_37 (ResidualUn (None, 4, 4, 128) 295936
_________________________________________________________________
residual_unit_38 (ResidualUn (None, 4, 4, 128) 295936
_________________________________________________________________
residual_unit_39 (ResidualUn (None, 2, 2, 256) 920576
_________________________________________________________________
residual_unit_40 (ResidualUn (None, 2, 2, 256) 1181696
_________________________________________________________________
residual_unit_41 (ResidualUn (None, 2, 2, 256) 1181696
_________________________________________________________________
residual_unit_42 (ResidualUn (None, 2, 2, 256) 1181696
_________________________________________________________________
residual_unit_43 (ResidualUn (None, 2, 2, 256) 1181696
_________________________________________________________________
residual_unit_44 (ResidualUn (None, 2, 2, 256) 1181696
_________________________________________________________________
residual_unit_45 (ResidualUn (None, 1, 1, 512) 3676160
_________________________________________________________________
residual_unit_46 (ResidualUn (None, 1, 1, 512) 4722688
_________________________________________________________________
residual_unit_47 (ResidualUn (None, 1, 1, 512) 4722688
_________________________________________________________________
global_average_pooling2d_2 ( (None, 512) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 512) 0
_________________________________________________________________
dense_5 (Dense) (None, 10) 5130
=================================================================
Total params: 21,300,554
Trainable params: 21,283,530
Non-trainable params: 17,024
_________________________________________________________________
- 모형 학습시간은 조금 오래 걸리는데, 구글 코랩에서 학습 진행 시, 런타임 끊김 현상이 발생할 수 있다.
- 이 때에는 아래 코드를 복사해서 [구글 크롬 개발자 도구]-[Console]에 붙여 넣고 실행시킨다.
function ClickConnect(){
console.log("Working");
document.querySelector("colab-toolbar-button#connect").click()
}
setInterval(ClickConnect,60000)
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
score = model.evaluate(X_test, y_test)
Epoch 1/10
1719/1719 [==============================] - 221s 128ms/step - loss: 0.5183 - accuracy: 0.8229 - val_loss: 0.3422 - val_accuracy: 0.8730
Epoch 2/10
1719/1719 [==============================] - 220s 128ms/step - loss: 0.3357 - accuracy: 0.8799 - val_loss: 0.3442 - val_accuracy: 0.8746
Epoch 3/10
1719/1719 [==============================] - 219s 127ms/step - loss: 0.3368 - accuracy: 0.8808 - val_loss: 0.3140 - val_accuracy: 0.8826
Epoch 4/10
1719/1719 [==============================] - 220s 128ms/step - loss: 0.2871 - accuracy: 0.8982 - val_loss: 0.3032 - val_accuracy: 0.8872
Epoch 5/10
1719/1719 [==============================] - 219s 128ms/step - loss: 0.2608 - accuracy: 0.9058 - val_loss: 0.2808 - val_accuracy: 0.8954
Epoch 6/10
1719/1719 [==============================] - 220s 128ms/step - loss: 0.2350 - accuracy: 0.9149 - val_loss: 0.2736 - val_accuracy: 0.9042
Epoch 7/10
1719/1719 [==============================] - 218s 127ms/step - loss: 0.2177 - accuracy: 0.9200 - val_loss: 0.2572 - val_accuracy: 0.9064
Epoch 8/10
1719/1719 [==============================] - 220s 128ms/step - loss: 0.1929 - accuracy: 0.9298 - val_loss: 0.2783 - val_accuracy: 0.9052
Epoch 9/10
1719/1719 [==============================] - 218s 127ms/step - loss: 0.1762 - accuracy: 0.9339 - val_loss: 0.2595 - val_accuracy: 0.9092
Epoch 10/10
1719/1719 [==============================] - 217s 126ms/step - loss: 0.1615 - accuracy: 0.9405 - val_loss: 0.2367 - val_accuracy: 0.9146
313/313 [==============================] - 7s 22ms/step - loss: 0.2556 - accuracy: 0.9129
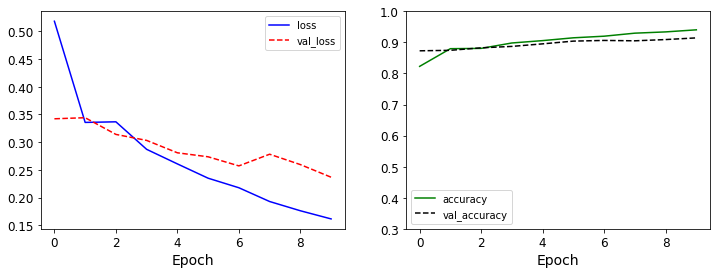
- 모형 학습의 결과에 대해 시각화를 진행한다.
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy')
plt.xlabel('Epoch')
plt.ylim(0.3, 1)
plt.legend()
plt.show()
VI. What’s Next
- 그런데, RestNet-34와 같이 로직을 구현해서 실현시키는 것은 조금 어렵다.
- 그 때, 사전 훈련된 모형을 불러와서 사용하는 것을 구현해보자.
