개요
- 본 수업을 듣는 수강생들을 위해 간단한 튜토리얼을 만들었다.
- 대회는 다음과 같다.
/img/programming/2020/10/blog_kdx_guideline/img


1단계 패키지 불러오기
- 데이터 가공 및 시각화 위주의 패키지를 불러온다.
library(tidyverse) # 데이터 가공 및 시각화
library(readxl) # 엑셀파일 불러오기 패키지
2단계 데이터 불러오기
- 데이터가 많아서 순차적으로 진행하도록 한다.
- 각 데이터에 대한 설명은
활용데이터설명(PDF)을 참조한다.
- 먼저 제 개발환경은 아래와 같다.
- Note: 윈도우와 Mac은 다를 수 있음을 명심하자.
## R version 4.0.2 (2020-06-22)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Catalina 10.15.6
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] readxl_1.3.1 forcats_0.5.0 stringr_1.4.0 dplyr_1.0.0
## [5] purrr_0.3.4 readr_1.3.1 tidyr_1.1.0 tibble_3.0.3
## [9] ggplot2_3.3.2 tidyverse_1.3.0
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.5 cellranger_1.1.0 pillar_1.4.6 compiler_4.0.2
## [5] dbplyr_1.4.4 tools_4.0.2 digest_0.6.25 lubridate_1.7.9
## [9] jsonlite_1.7.0 evaluate_0.14 lifecycle_0.2.0 gtable_0.3.0
## [13] pkgconfig_2.0.3 rlang_0.4.7 reprex_0.3.0 cli_2.0.2
## [17] rstudioapi_0.11 DBI_1.1.0 yaml_2.2.1 haven_2.3.1
## [21] xfun_0.16 withr_2.3.0 xml2_1.3.2 httr_1.4.2
## [25] knitr_1.29 fs_1.5.0 hms_0.5.3 generics_0.0.2
## [29] vctrs_0.3.2 grid_4.0.2 tidyselect_1.1.0 glue_1.4.1
## [33] R6_2.4.1 fansi_0.4.1 rmarkdown_2.3 modelr_0.1.8
## [37] blob_1.2.1 magrittr_1.5 backports_1.1.8 scales_1.1.1
## [41] ellipsis_0.3.1 htmltools_0.5.0 rvest_0.3.6 assertthat_0.2.1
## [45] colorspace_1.4-1 stringi_1.4.6 munsell_0.5.0 broom_0.7.0
## [49] crayon_1.3.4
(1) 삼성카드 데이터
- 우선 삼성카드 데이터를 불러와서 확인한다.
- 한글 파일은 인코딩이 늘 항상 문제다.
- 파일을 불러오기 전 항상 파일 인코딩을 확인하도록 한다.
readr::guess_encoding("data/Samsungcard.csv", n_max = 100)
## # A tibble: 2 x 2
## encoding confidence
## <chr> <dbl>
## 1 EUC-KR 1
## 2 GB18030 0.62
- Encoding 확인 결과
EUC-KR로 확인하였다.
samsung_card <- read_xlsx("data/Samsungcard.xlsx")
samsung_card2 <- read.csv("data/Samsungcard.csv", fileEncoding = "EUC-KR")
## # A tibble: 6 x 5
## 소비일자 소비업종 성별 연령대 소비건수
## <dbl> <chr> <chr> <chr> <dbl>
## 1 20190101 가전/가구 남성 20대 5529
## 2 20190101 가전/가구 남성 30대 17536
## 3 20190101 가전/가구 남성 40대 22838
## 4 20190101 가전/가구 남성 50대 15801
## 5 20190101 가전/가구 남성 60대 6772
## 6 20190101 가전/가구 여성 20대 5937
## 소비일자 소비업종 성별 연령대 소비건수
## 1 20190101 가전/가구 남성 20대 5529
## 2 20190101 가전/가구 남성 30대 17536
## 3 20190101 가전/가구 남성 40대 22838
## 4 20190101 가전/가구 남성 50대 15801
## 5 20190101 가전/가구 남성 60대 6772
## 6 20190101 가전/가구 여성 20대 5937
- 두 파일이 동일한 것을 확인하였다면 이제
samsung_card2는 삭제를 한다.
rm(samsung_card2) # 객체 지우는 함수
ls() # 현재 저장된 객체 확인하는 함수
## [1] "samsung_card"
(2) 신한카드 데이터
- 이번에는
ShinhanCard.xslx 데이터를 불러온다.
shinhancard <- read_xlsx("data/Shinhancard.xlsx")
head(shinhancard)
## # A tibble: 6 x 8
## 일별 성별 연령대별 업종 `카드이용건수(천건)`… ...6 ...7 ...8
## <chr> <chr> <chr> <chr> <dbl> <lgl> <lgl> <dbl>
## 1 201901… F 20대 M001_한식 299. NA NA 10
## 2 201901… F 20대 M002_일식/중식/양식… 88.3 NA NA NA
## 3 201901… F 20대 M003_제과/커피/패스트푸드… 291. NA NA NA
## 4 201901… F 20대 M004_기타요식 446. NA NA NA
## 5 201901… F 20대 M005_유흥 24.2 NA NA NA
## 6 201901… F 20대 M006_백화점 35.3 NA NA NA
- 위 데이터를 불러오니 불필요한
6:8 변수가 불러온 것을 확인할 수 있다.- 실제 엑셀 데이터를 열어도 빈값임을 확인할 수 있다.
- 따라서,
6:8 변수는 삭제한다.
shinhancard <- shinhancard %>%
select(-c(6:8))
head(shinhancard)
## # A tibble: 6 x 5
## 일별 성별 연령대별 업종 `카드이용건수(천건)`
## <chr> <chr> <chr> <chr> <dbl>
## 1 20190101 F 20대 M001_한식 299.
## 2 20190101 F 20대 M002_일식/중식/양식 88.3
## 3 20190101 F 20대 M003_제과/커피/패스트푸드 291.
## 4 20190101 F 20대 M004_기타요식 446.
## 5 20190101 F 20대 M005_유흥 24.2
## 6 20190101 F 20대 M006_백화점 35.3
(3) 지인플러스
- 지인플러스는 아파트시세(
GIN00009A)와 아파트 거래량(GIN00008B)을 담은 코드이다.
gin_8a <- read_csv("data/GIN00008A.csv")
gin_9a <- read_csv("data/GIN00009A.csv")
## Rows: 937,904
## Columns: 9
## $ ym <dbl> 200601, 200602, 200603, 200604, 200605, 200606, 200607…
## $ area_lvl_scor <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ lgdng_cd <chr> "0000000000", "0000000000", "0000000000", "0000000000"…
## $ trd_cont <dbl> 23357, 38617, 52241, 44253, 41916, 30257, 28613, 37362…
## $ avg_trd_cont <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ trd_deal_rat <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ mtrnt_cont <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ avg_mtrnt_cont <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ mtrnt_deal_rat <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## Rows: 785,805
## Columns: 4
## $ lgdng_cd <dbl> 1.1e+09, 1.1e+09, 1.1e+09, 1.1e+09, 1.1e+09, 1.1e+09, 1.1e+0…
## $ std_date <date> 2006-01-21, 2006-02-21, 2006-03-21, 2006-04-21, 2006-05-21,…
## $ trd_prc <dbl> 1289, 1271, 1291, 1307, 1321, 1335, 1357, 1381, 1411, 1444, …
## $ ldpb_prc <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
(4) JSON 파일 불러오기
JSON 파일 불러올 때에는 jsonlite 패키지를 활용한다.
library(jsonlite)
GIN_10m <- fromJSON("data/center_GIN00010M.json")
glimpse(GIN_10m)
## Rows: 20,572
## Columns: 8
## $ AREA_LVL_SCOR <int> 1, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
## $ LGDNG_CD <chr> "1100000000", "1111000000", "1111010100", "1111010200",…
## $ CTPV_NM <chr> "서울특별시", "서울특별시", "서울특별시", "서울특별시", "서울특별시", "서울특별시", "…
## $ CTGG_NM <chr> NA, "종로구", "종로구", "종로구", "종로구", "종로구", "종로구", "종로구", "종…
## $ EMD_NM <chr> NA, NA, "청운동", "신교동", "궁정동", "효자동", "창성동", "통의동", "적선동"…
## $ LA <dbl> 37.52934, 37.58586, 37.58920, 37.58449, 37.58468, 37.58…
## $ LNGT <dbl> 126.9515, 126.9775, 126.9693, 126.9679, 126.9731, 126.9…
## $ PYN_CN <chr> "{\"type\": \"Polygon\", \"coordinates\": [[[126.979658…
PYN_CN의 값이 조금 다른 것을 확인할 수 있다.- 이 부분은 추후 전처리할 때 정리하는 것으로 확인한다.
(5) SSC_Data
- 이번에는
Mcorporation내 폴더 데이터를 올리도록 한다. - 이번에 파일을 불러올 때는
readr::read_csv()를 활용하여 불러온다.
readr::guess_encoding("data/Mcorporation/KDX시각화경진대회_SSC_DATA.csv")
## # A tibble: 2 x 2
## encoding confidence
## <chr> <dbl>
## 1 EUC-KR 1
## 2 GB18030 0.76
ssc_data <- read_csv("data/Mcorporation/KDX시각화경진대회_SSC_DATA.csv", locale = locale("ko", encoding = "EUC-KR"))
glimpse(ssc_data)
## Rows: 76,580
## Columns: 5
## $ 소비일자 <dbl> 20190101, 20190101, 20190101, 20190101, 20190101, 20190101, 2019…
## $ 소비업종 <chr> "가전/가구", "가전/가구", "가전/가구", "가전/가구", "가전/가구", "가전/가구", "가전/가구", "…
## $ 성별 <chr> "남성", "남성", "남성", "남성", "남성", "여성", "여성", "여성", "여성", "여성", "남…
## $ 연령대 <chr> "20대", "30대", "40대", "50대", "60대", "20대", "30대", "40대", "50대", …
## $ 소비건수 <dbl> 5529, 17536, 22838, 15801, 6772, 5937, 12895, 16896, 14025, 5909…
(6) 다중 엑셀파일 불러오기 예제
상품 카데고리 데이터_KDX 시각화 폴더 내 엑셀 데이터를 확인해본다.
list.files(path = "data/Mcorporation/상품 카테고리 데이터_KDX 시각화 경진대회 Only/")
## [1] "PC사무기기.xlsx" "TV홈시어터.xlsx"
## [3] "가공식품.xlsx" "가방지갑잡화.xlsx"
## [5] "건강관련용품.xlsx" "건강식품.xlsx"
## [7] "계절가전.xlsx" "골프용품.xlsx"
## [9] "공구류.xlsx" "구기.xlsx"
## [11] "국내외여행.xlsx" "기타 스포츠.xlsx"
## [13] "낚시.xlsx" "남성의류.xlsx"
## [15] "노트북.xlsx" "농축수산물.xlsx"
## [17] "도서음반DVD.xlsx" "등산용품.xlsx"
## [19] "메이크업.xlsx" "문구사무용품.xlsx"
## [21] "미용가전.xlsx" "반려동물.xlsx"
## [23] "생활가구.xlsx" "생활가전.xlsx"
## [25] "생활용품.xlsx" "서비스티켓.xlsx"
## [27] "성인용품.xlsx" "세탁청소세면.xlsx"
## [29] "수납가구.xlsx" "수납용품.xlsx"
## [31] "수영.xlsx" "스키보드.xlsx"
## [33] "스킨케어.xlsx" "스포츠의류.xlsx"
## [35] "신발.xlsx" "악세서리시계주얼리.xlsx"
## [37] "안전용품.xlsx" "언더웨어.xlsx"
## [39] "업소위생용품.xlsx" "여성의류.xlsx"
## [41] "완구키덜트게임.xlsx" "욕실가전.xlsx"
## [43] "욕실용품.xlsx" "유아용품.xlsx"
## [45] "유아패션.xlsx" "음료.xlsx"
## [47] "음향가전.xlsx" "인테리어용품.xlsx"
## [49] "자동차용품.xlsx" "자전거사이클보드인라인.xlsx"
## [51] "주방가전.xlsx" "주방수납잡화.xlsx"
## [53] "주방식기용기.xlsx" "주방조리기구.xlsx"
## [55] "출산임부용품.xlsx" "취미악기.xlsx"
## [57] "침실가구.xlsx" "침실인테리어.xlsx"
## [59] "카메라캠코더.xlsx" "캠핑용품.xlsx"
## [61] "테마의류.xlsx" "헤어바디용품.xlsx"
## [63] "헬스기구용품.xlsx" "휴대폰악세서리.xlsx"
- 몇가지 파일을 열어본다.
- 엑셀 데이터의 변수 등이 동일한 것을 확인할 수 있다.
- 이제 위 데이터를 한꺼번에 불러와서 하나의 데이터셋으로 합친다.
- 검색키워드
Multiple Excel Files import in R
files <- list.files(path = "data/Mcorporation/상품 카테고리 데이터_KDX 시각화 경진대회 Only/", pattern = "*.xlsx", full.names = T)
products <- sapply(files, read_excel, simplify=FALSE) %>%
bind_rows(.id = "id") %>%
select(-id)
glimpse(products)
## Rows: 1,837,833
## Columns: 7
## $ 구매날짜 <dbl> 20190101, 20190101, 20190101, 20190101, 20190101, 20190101, 20…
## $ 카테고리명 <chr> "PC/사무기기", "PC/사무기기", "PC/사무기기", "PC/사무기기", "PC/사무기기", "PC/사무기기…
## $ 고객성별 <chr> "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F", "F…
## $ 고객나이 <dbl> 10, 10, 10, 10, 20, 20, 20, 20, 30, 30, 30, 30, 40, 40, 40, 40…
## $ OS유형 <chr> "IOS", "WINDOWS", "안드로이드", "없음", "IOS", "WINDOWS", "안드로이드", …
## $ 구매금액 <dbl> 352443, 84000, 80870, 3700, 27714776, 11414514, 21223319, 4832…
## $ 구매수 <dbl> 13, 1, 8, 1, 381, 60, 252, 41, 240, 75, 423, 19, 58, 110, 436…
3단계 데이터 시각화
- 먼저, 데이터 저장 용량을 고려하여
products 데이터셋을 제외하고 나머지는 모두 삭제한다. - 데이터 시각화는 변수의 종류에 따른 시각화를 구현한 것이다.
- 시각화 참조자료는 다음에서 작성이 가능하다.
- 아래 샘플은 필자가 공부하는 형태를 구현한 것이다. 참조하기를 바란다.
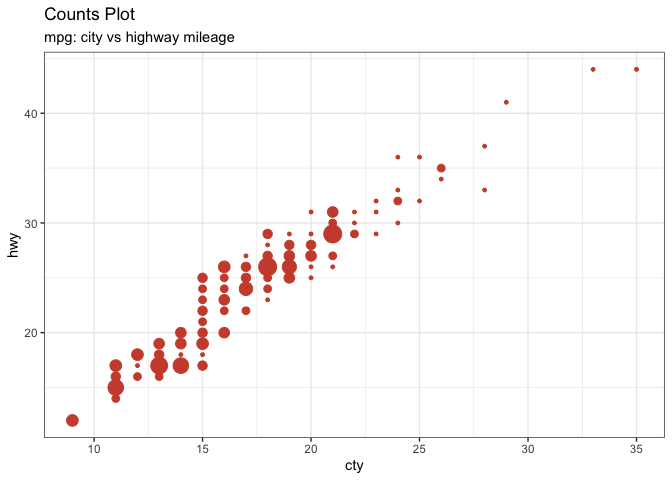
(1) 수치형 변수 ~ 수치형 변수
- 수치형 변수 ~ 수치형 변수 시각화의 대표적인 기법은 산점도(
scatter) 또는 correlation이라 부른다.
# load package and data
library(ggplot2)
data(mpg, package="ggplot2")
# mpg <- read.csv("http://goo.gl/uEeRGu")
# Scatterplot
theme_set(theme_bw()) # pre-set the bw theme.
g <- ggplot(mpg, aes(cty, hwy))
g + geom_count(col="tomato3", show.legend=F) +
labs(subtitle="mpg: city vs highway mileage",
y="hwy",
x="cty",
title="Counts Plot")