[Python] 카카오톡 챗봇 오픈빌더를 활용한 사칙연산 계산기 구현
읽기 전 공지
- 본 글은 2022년 11월 28일까지만 유효합니다. 무료 버전이 사라지기 때문에, 앞으로 어떻게 될지는 현재 글 쓰는 시점에서는 모릅니다. 이 부분에 주의해서 참고 하시기를 바랍니다.
개요
- 카카오톡 챗봇 만들기를 Python + FLASK를 통해 간단한 튜토리얼을 만들어본다.
사전준비
- OBT 참여승인을 받아야 한다.
기본설정
- 카카오톡 챗봇 버튼 클릭 후, 봇 이름 생성
- [봇 만들기] - [카카오톡 챗봇]
카카오톡 채널 연결을 진행한다.
virtualenv를 활용하여 가상환경을 설정한다.
$ virtualenv venv
created virtual environment CPython3.9.7.final.0-64 in 6029ms
creator CPython3Windows(dest=C:\Users\human\Desktop\heroku-kakao-chatbot\venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=C:\Users\human\AppData\Local\pypa\virtualenv)
added seed packages: pip==22.0.4, setuptools==62.1.0, wheel==0.37.1
activators BashActivator,BatchActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
Heroku App 구축
- 간단하게 app 파일을 만들어 Heroku App URL을 확보해보자.
- app/main.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
- wsgi.py 생성
- app은 폴더를 말하고, main은 main.py를 말한다.
from app.main import app
if __name__ == "__main__":
app.run(threaded=True, port=5000)
- Procfile 파일 작성
- 카카오톡 챗봇에서는 포트번호를 입력을 해줘야 한다.
- localhost:5000 처럼 명시적으로 입력해주는 것으로 생각하면 된다.
- 카카오톡 챗봇에서는 포트번호를 입력을 해줘야 한다.
web: gunicorn --bind 0.0.0.0:$PORT wsgi:app
- runtime.txt
- Python 버전을 업로드 한다.
python-3.9.7
- Heroku login
- Heroku 배포 전에 반드시 로그인을 해야 한다.
$ heroku login
- Heroku Project 생성
- 프로젝트 생성 시, 같은 이름이 있을 경우 다시 작성할 수도 있다.
$ heroku create heroku-kakao-chatbot
- Heroku 배포
- Heroku에 배포하기 위해서는 크게 아래 코드만 기억한다.
$ git add .
$ git commit -am "your_message"
$ git push origin main ## Github Repository에 업데이트
$ git push heroku main ## Heroku 코드 배포
- 기존 Existing App과 연동하려면 배포 전 아래 코드를 선 실행 후, 배포를 진행한다.
$ heroku git:remote -a example-app
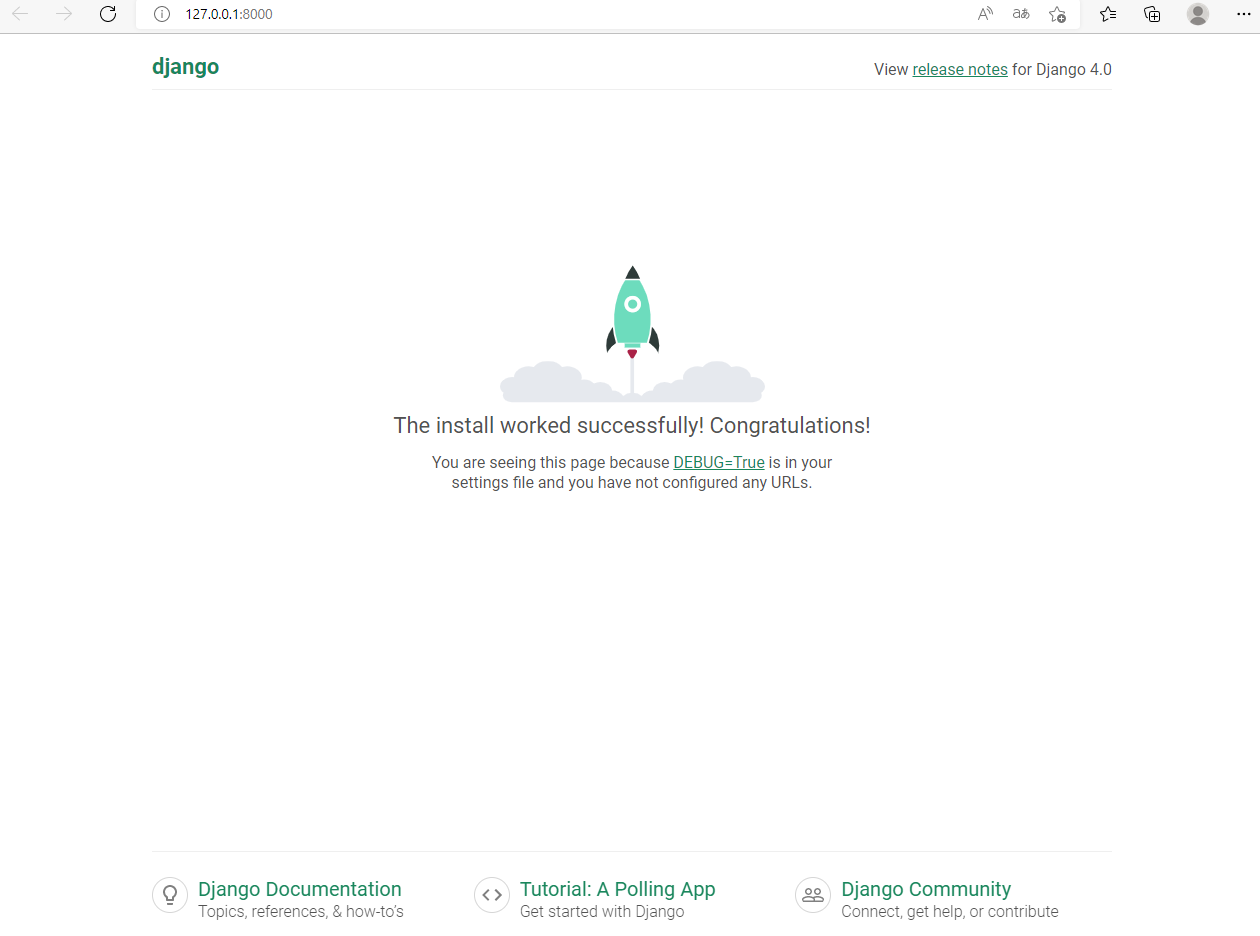
- 실행하면 아래와 같은 결과물이 나타난다.
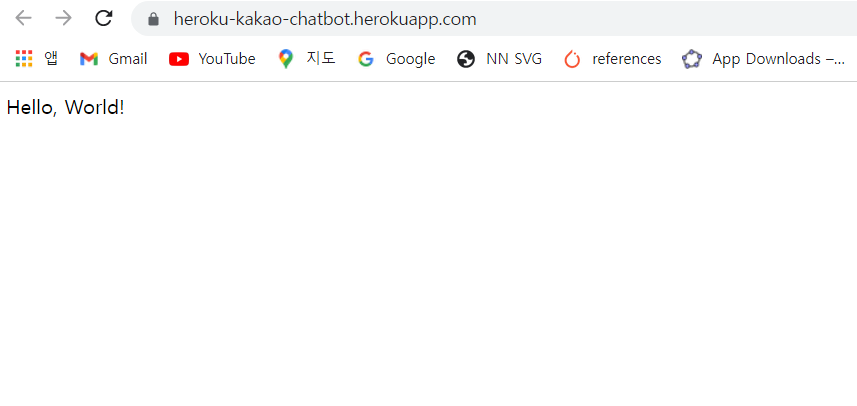
스킬 서버 구축 기본편
스킬 서버에서 제공하는 2가지 API URI는 다음과 닽다.