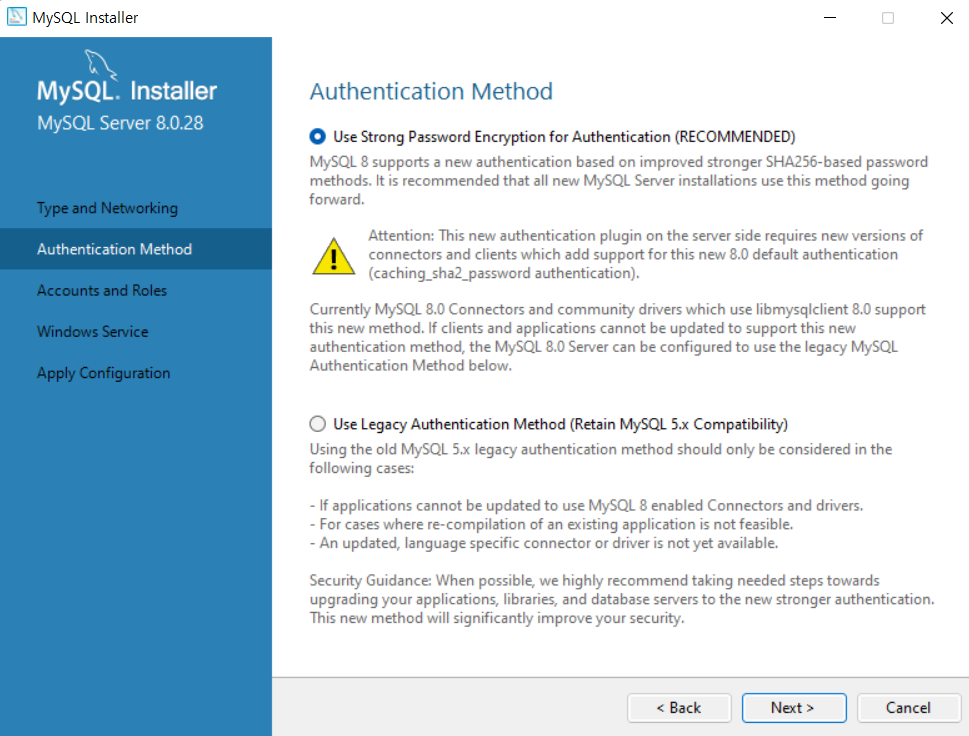
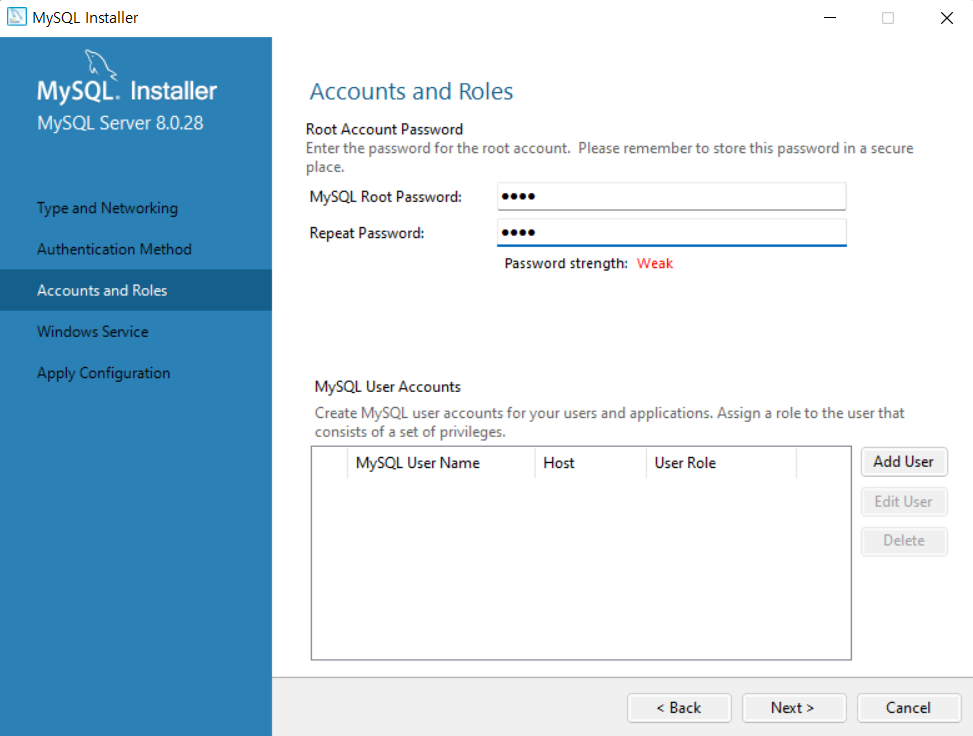
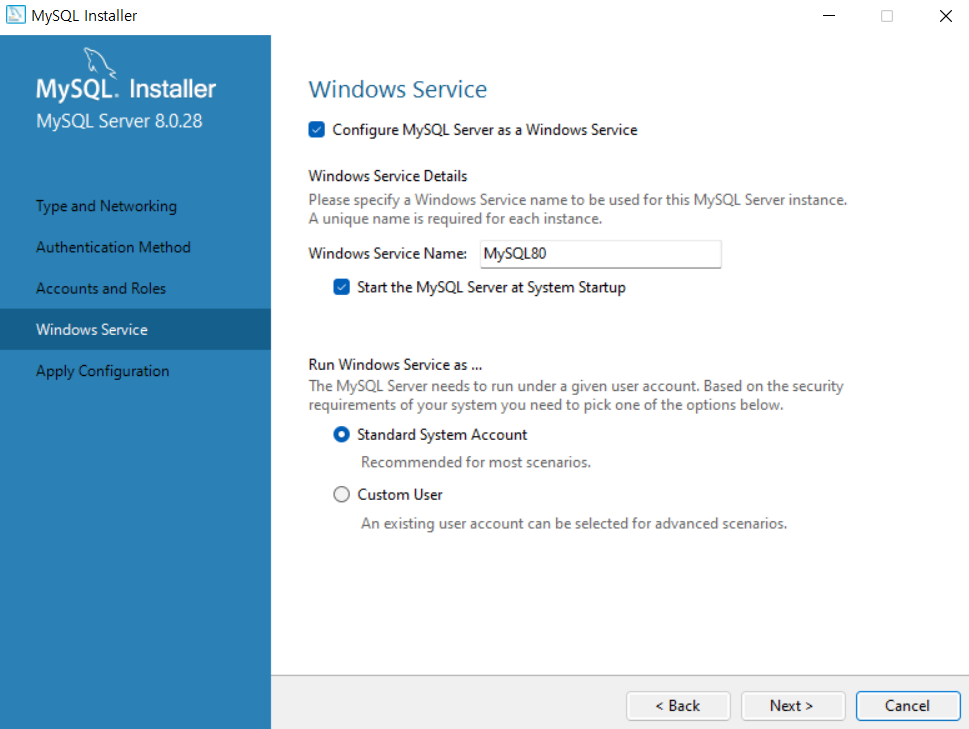
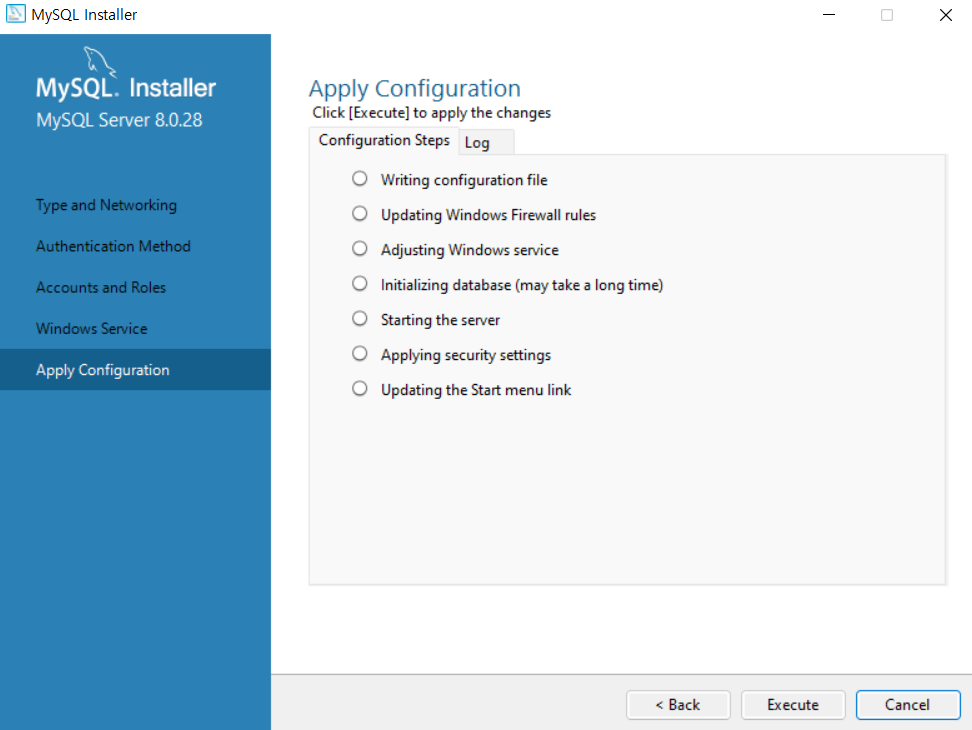
라이브러리 불러오기
import boto3
print(boto3.__version__)
1.23.5
IAM User 관련 주요 코드
def create_user(username):
iam = boto3.client('iam')
response = iam.create_user(UserName=username)
print(response)
create_user('testuser2fromwsl2')
{'User': {'Path': '/', 'UserName': 'testuser2fromwsl2', 'UserId': 'AIDAVRRRQ3HFXFQPOOY7Q', 'Arn': 'arn:aws:iam::381282212299:user/testuser2fromwsl2', 'CreateDate': datetime.datetime(2022, 5, 24, 5, 30, 6, tzinfo=tzutc())}, 'ResponseMetadata': {'RequestId': 'd5fa242b-9aa9-4ad9-a75a-ed23e041d4ba', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'd5fa242b-9aa9-4ad9-a75a-ed23e041d4ba', 'content-type': 'text/xml', 'content-length': '495', 'date': 'Tue, 24 May 2022 05:30:05 GMT'}, 'RetryAttempts': 0}}
- 이번에는 모든 사용자를 가져오는 코드를 작성한다.
def all_users():
iam = boto3.client('iam')
paginator = iam.get_paginator('list_users')
for response in paginator.paginate():
for user in response['Users']:
username = user['UserName']
Arn = user['Arn']
print('Username : {} Arn : {}'.format(username, Arn))
all_users()
Username : aws-wsl2 Arn : arn:aws:iam::381282212299:user/aws-wsl2
Username : human Arn : arn:aws:iam::381282212299:user/human
Username : human-m1 Arn : arn:aws:iam::381282212299:user/human-m1
Username : testuser Arn : arn:aws:iam::381282212299:user/testuser
Username : testuser2 Arn : arn:aws:iam::381282212299:user/testuser2
Username : testuser2fromwsl2 Arn : arn:aws:iam::381282212299:user/testuser2fromwsl2
Username : testuser3 Arn : arn:aws:iam::381282212299:user/testuser3
- 이번에는 사용자 이름을 변경한다.
- testuser2fromwsl2 이름을 updatetest로 변경하는 코드다.
def update_user(old_username, new_username):
iam = boto3.client('iam')
response = iam.update_user(
UserName=old_username,
NewUserName=new_username
)
print(response)
update_user('testuser2fromwsl2', 'updatetest')
all_users()
{'ResponseMetadata': {'RequestId': '4a567c96-d5ce-4e76-9344-6ab762fc9e01', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '4a567c96-d5ce-4e76-9344-6ab762fc9e01', 'content-type': 'text/xml', 'content-length': '200', 'date': 'Tue, 24 May 2022 05:30:16 GMT'}, 'RetryAttempts': 0}}
Username : aws-wsl2 Arn : arn:aws:iam::381282212299:user/aws-wsl2
Username : human Arn : arn:aws:iam::381282212299:user/human
Username : human-m1 Arn : arn:aws:iam::381282212299:user/human-m1
Username : testuser Arn : arn:aws:iam::381282212299:user/testuser
Username : testuser2 Arn : arn:aws:iam::381282212299:user/testuser2
Username : testuser3 Arn : arn:aws:iam::381282212299:user/testuser3
Username : updatetest Arn : arn:aws:iam::381282212299:user/updatetest
Python AWS 연동 예제
- 보통 정책을 추가할 때는 Web UI Console창에서 지정하지만, 코드를 통해서 구현할 수도 있다.
import boto3
import json
def create_policy():
iam = boto3.client('iam')
user_policy = {
"Version":"2012-10-17",
"Statement":[
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
response = iam.create_policy(
PolicyName = 'pyFullAccess',
PolicyDocument=json.dumps(user_policy)
)
print(response)
create_policy()
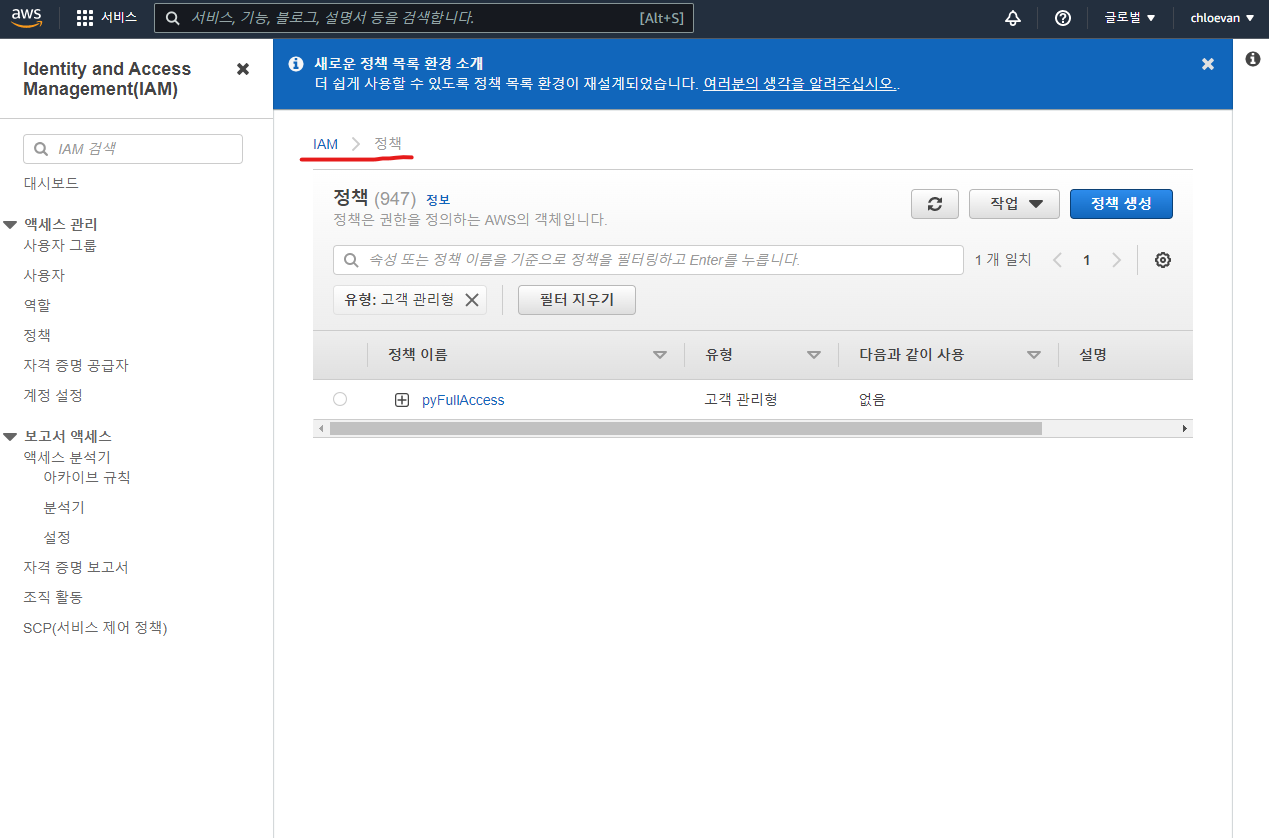
{'Policy': {'PolicyName': 'pyFullAccess', 'PolicyId': 'ANPAVRRRQ3HFQIRVWB2MX', 'Arn': 'arn:aws:iam::381282212299:policy/pyFullAccess', 'Path': '/', 'DefaultVersionId': 'v1', 'AttachmentCount': 0, 'PermissionsBoundaryUsageCount': 0, 'IsAttachable': True, 'CreateDate': datetime.datetime(2022, 5, 23, 5, 40, 21, tzinfo=tzutc()), 'UpdateDate': datetime.datetime(2022, 5, 23, 5, 40, 21, tzinfo=tzutc())}, 'ResponseMetadata': {'RequestId': '8da83bae-6c24-4104-9da4-22795e46652a', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '8da83bae-6c24-4104-9da4-22795e46652a', 'content-type': 'text/xml', 'content-length': '759', 'date': 'Mon, 23 May 2022 05:40:21 GMT'}, 'RetryAttempts': 0}}
- AWS 콘솔창에서 IAM 대시보드에서 정책을 클릭하면 PolicyName인 pyFullAccess가 등록되어 있는 것을 확인할 수 있다.