강의 홍보
I. 개요
- 여러 형태의 반복문을 배우고 실습한다.
- 한줄로 작성하는 반복문을 배우고 실습한다.
II. For Loop Basic Syntax
for <변수> in <iterable>:
<코드>
- 여기에서
iterable의 개념은 list와 tuple을 의미한다. - 간단하게
for_loop 코드를 작성해보자.- 우선, A라는 리스트 객체를 작성한다.
for_loop를 활용해서 리스트 안에 있는 것을 하나씩 출력한다.
A = ["철수", "영희", "길동"]
for i in A:
print(i)
철수
영희
길동
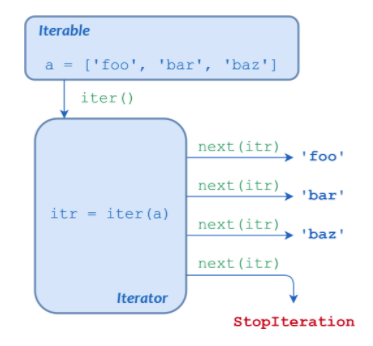
(1) Iterables
Iteration을 한국어로 번역하면 되풀이다.- 그런데, 어떤 데이터 유형이
되풀이를 할 수 있을가?List와 Tuple이 되풀이가 될 수 있는 소재인 것은 확실하다.
- 어떤
객체(=Object)가 있을 때, 이 객체가 iterable 한것인지, 또는 아닌지 확인하는 함수(iter())도 있다.
<str_iterator object at 0x7f2464faeb00>
print(iter(["A", "B", "C"]))
<list_iterator object at 0x7f2464faedd8>
print(iter(("A", "B", "C")))
<tuple_iterator object at 0x7f2464faedd8>
print(iter({"A": 1, "B": 3, "C": 3}))
<dict_keyiterator object at 0x7f2464fdd458>
- 그런데, 수치형의 경우에는 iteration이 적용되지 않는다.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-48-f3bbc5ecfc9b> in <module>()
----> 1 print(iter(100))
TypeError: 'int' object is not iterable
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-eb85da4c3f57> in <module>()
----> 1 iter(3.14)
TypeError: 'float' object is not iterable
- 단일 수치형 데이터를 제외하고는 사실상 모든 데이터가
iterable의 성질을 가지고 있다.
(2) next()
next()는 iterator에서의 next value를 의미한다.- 다음 코드를 확인해보자.
A = ["철수", "영희", "길동"]
iterable = iter(A)
iterable
<list_iterator at 0x7f2464fb7dd8>