강의 홍보
Numpy ndarray 개요
- 넘파이
array()는 ndarray로 변환 가능 - 생성된
ndarray배열의 shape변수는 ndarray의 크기, 행과 열의 수를 튜플 형태로 가지고 있으며, 이를 통해 ndarray 배열의 차원까지 알 수 있음
(1) 배열이란?
NumPy에서 배열은 동일한 타입의 값을 가짐shape는 각 차원의 크기를 튜플로 표시한다.- 차원이란 무엇일까?
- 1차원은 보통 하나의
선을 의미 - 2차원은 평면을 의미하고, 데이터 분석에서는 보통 데이터프레임을 의미한다.
- 3차원은 공간을 의미하고, 딥러닝에서는 보통 이미지를 의미한다. (RGB)
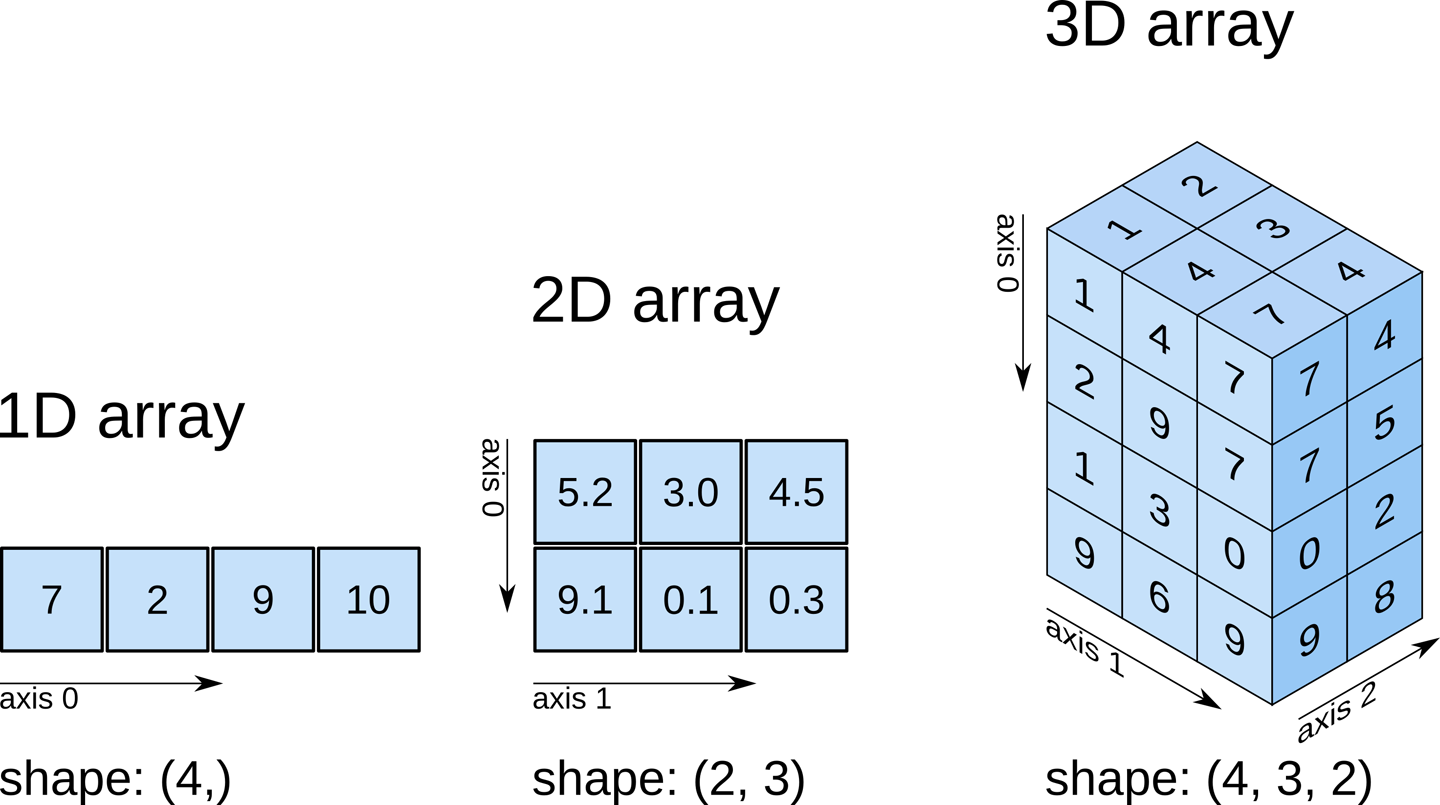
shape와 ndim
- 코드를 통해서
shape와 ndim 함수를 확인해본다.
(1) 함수 활용 예제
- 우선 소스코드를 통해 1차원, 2차원, 3차원 함수를 만들어 봅니다.
array1 = np.array([1,2,3,4,5])
print('array1 type:',type(array1))
print('array1 array 형태:',array1.shape)
array2 = np.array([[1,2,3,4,5],
[2,3,4,5,6]])
print('array2 type:',type(array2))
print('array2 array 형태:',array2.shape)
array3 = np.array([[[1,2,3,4,5,6]], [[3,4,5,6,7,8]]])
print('array3 type:',type(array3))
print('array3 array 형태:',array3.shape)
array1 type: <class 'numpy.ndarray'>
array1 array 형태: (5,)
array2 type: <class 'numpy.ndarray'>
array2 array 형태: (2, 5)
array3 type: <class 'numpy.ndarray'>
array3 array 형태: (2, 1, 6)
(2) shape
- 1차원의
shape는 (3, )인데, 이는 array로 5개의 데이터를 가지고 있다는 뜻임 - 2차원의
shape는 (2, 5)이며, 이는 array로 2차원 데이터로 2 x 5 = 10, 즉 총 10개의 데이터가 있음 - 3차원의
shape는 (2, 1, 6)이며, 이는 array로 3차원 데이터로 2 x 1 x 6 = 12, 즉 총 12개의 데이터가 있음 - 차원을 직관적으로 확인하려면
ndim 메서드를 사용하면 된다.
print('array1: {:0}차원, array2: {:1}차원, array3: {:2}차원'.format(array1.ndim, array2.ndim, array3.ndim))
array1: 1차원, array2: 2차원, array3: 3차원
데이터 타입
ndarray내 데이터값은 숫자 값, 문자열 값, 불 값 모두 가능- 숫자형의 경우 int형, float형 등이 제공됨
- int: 8, 16, 32
- float: 16, 32, 64, 128
- 간단한 예제로 확인한다.
num_list = [7, 8, 9, 10]
print(type(num_list))
num_array = np.array(num_list)
print(type(num_array))
print(num_array, num_array.dtype)
<class 'list'>
<class 'numpy.ndarray'>
[ 7 8 9 10] int64
reshape의 중요성
shape를 통해 데이터를 이해하는 것은 매우 중요하다.- 머신러닝 알고리즘 또는 선형대수를 잘 모른다 할지라도, 머신러닝 및 데이터 세트 간의 입출력과 변환 수행 시, 1차원 데이터 또는 다차원 데이터를 요구하는 경우가 있다.
- 이 때, 차원이 달라서 오류가 발생할 가능성이 크니, 주의를 해야 한다.
- 이 때, 차원을 맞추는 방법으로
reshape()를 활용한다.
(1) 소스 예제
- 다음 예제는 0~14까지의 1차원
ndarray를 2x5형태로, 그리고 5x2 2차원 ndarray로 변환한다.
array1 = np.arange(15)
print('array1:\n', array1)
array2 = array1.reshape(3,5)
print('array2:\n',array2)
array3 = array1.reshape(5,3)
print('array3:\n',array3)
array1:
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
array2:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
array3:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-8-a40469ec5825> in <module>()
----> 1 array1.reshape(4,3)
ValueError: cannot reshape array of size 15 into shape (4,3)
- 위 에러는 변경이 불가능한데, 당연한 얘기이지만, size가 맞지 않다.
(2) -1의 활용
- 실전에서는 주로
-1을 활용한다. -1을 인자로 사용하면 원래 ndarray와 호환되는 새로운 shape로 변환해준다.- 예제를 통해서 살펴보도록 한다.
array_1 = np.arange(15)
print(array_1)
array_2 = array_1.reshape(-1,5)
print('array2 shape:',array_2.shape)
array_3 = array_1.reshape(5,-1)
print('array3 shape:',array_3.shape)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
array2 shape: (3, 5)
array3 shape: (5, 3)
array_1은 1차원 ndarray로 0~14까지의 데이터를 가지고 있다.array_2는 array_1과 호환될 수 있는 2차원 ndarray로 변환되고, 고정된 5개의 칼럼에 맞는 로우를 자동으로 새롭게 생성해 변환하는 의미를 가진다.- 그런데, 호환될 수 없는 형태는 에러가 날 것이다.
(3) 차원변환
- 3차원을 2차원으로, 1차원을 2차원으로 변경하는 코드를 작성할 수 있다.
- 이 때,
reshape(a1, a2, a3)에서, b = a1 x a2 x a3의 값이 arrange(b)이 된다.
array_1 = np.arange(27)
array_3d = array_1.reshape((3,3,3))
print('array3d:\n',array_3d.tolist())
# 3차원 ndarray를 2차원 ndarray로 변환
array_5 = array_3d.reshape(-1,1)
print('array5:\n',array_5.tolist())
print('array5 shape:',array_5.shape)
# 1차원 ndarray를 2차원 ndarray로 변환
array_6 = array_1.reshape(-1,1)
print('array6:\n',array_6.tolist())
print('array6 shape:',array_6.shape)
array3d:
[[[0, 1, 2], [3, 4, 5], [6, 7, 8]], [[9, 10, 11], [12, 13, 14], [15, 16, 17]], [[18, 19, 20], [21, 22, 23], [24, 25, 26]]]
array5:
[[0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16], [17], [18], [19], [20], [21], [22], [23], [24], [25], [26]]
array5 shape: (27, 1)
array6:
[[0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16], [17], [18], [19], [20], [21], [22], [23], [24], [25], [26]]
array6 shape: (27, 1)
선형대수 연산
- 행렬 내적은 행렬 곱이며,
np.dot()을 활용한다.