AirFlow 설치 및 실행 with M1
인프런 강의
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

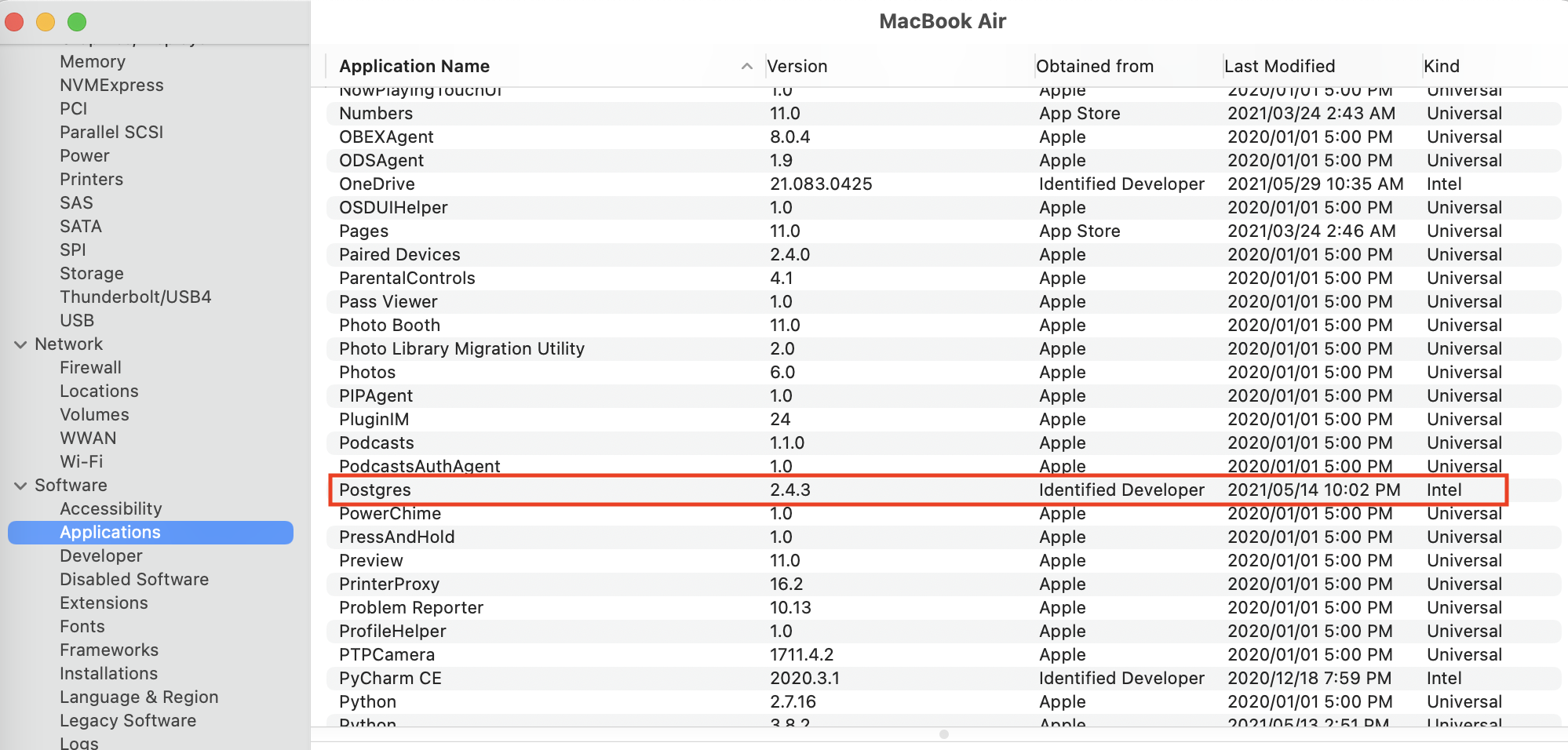
미니 프로젝트 개요
- 목적: Airflow와 빅쿼리를 활용하여 ETL 및 대시보드를 만들어보는 과정을 설계
- 환경: MacOS M1
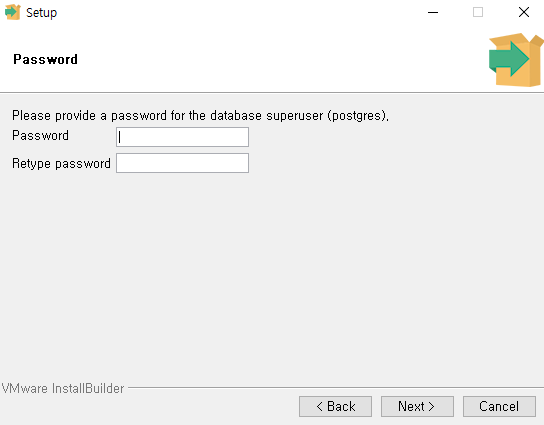
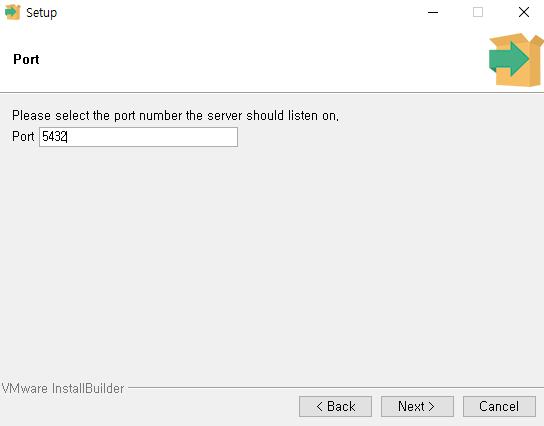
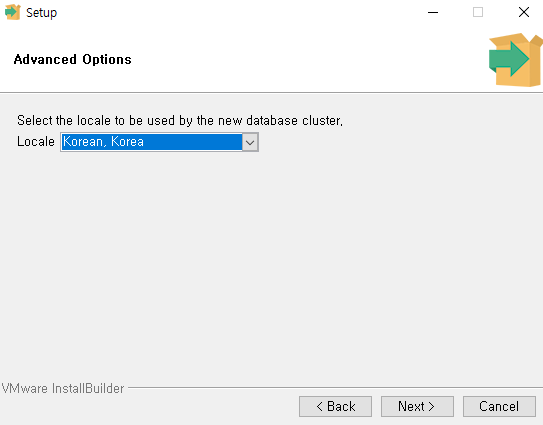
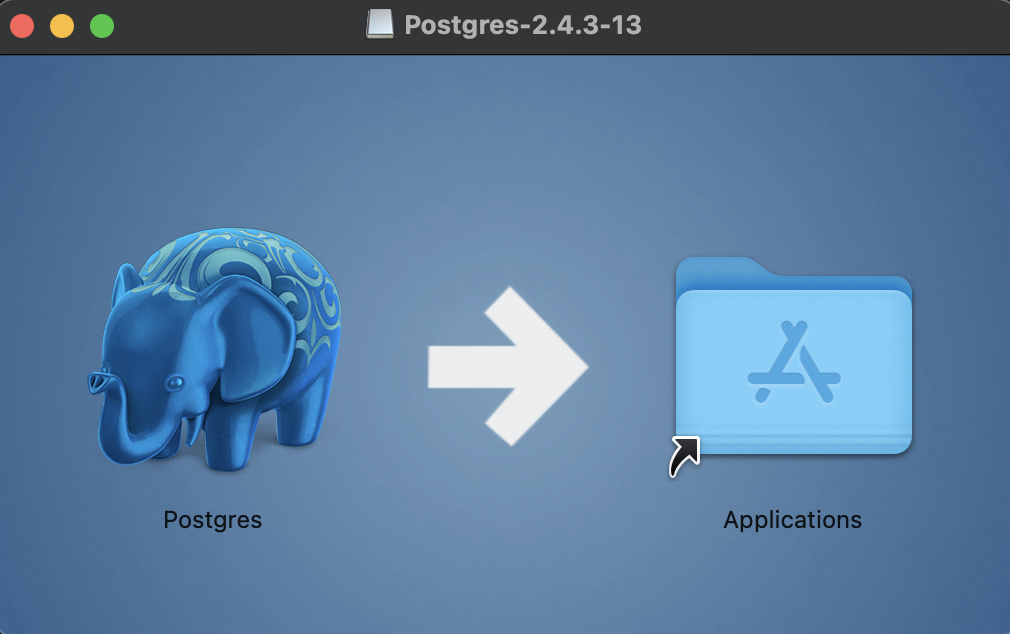
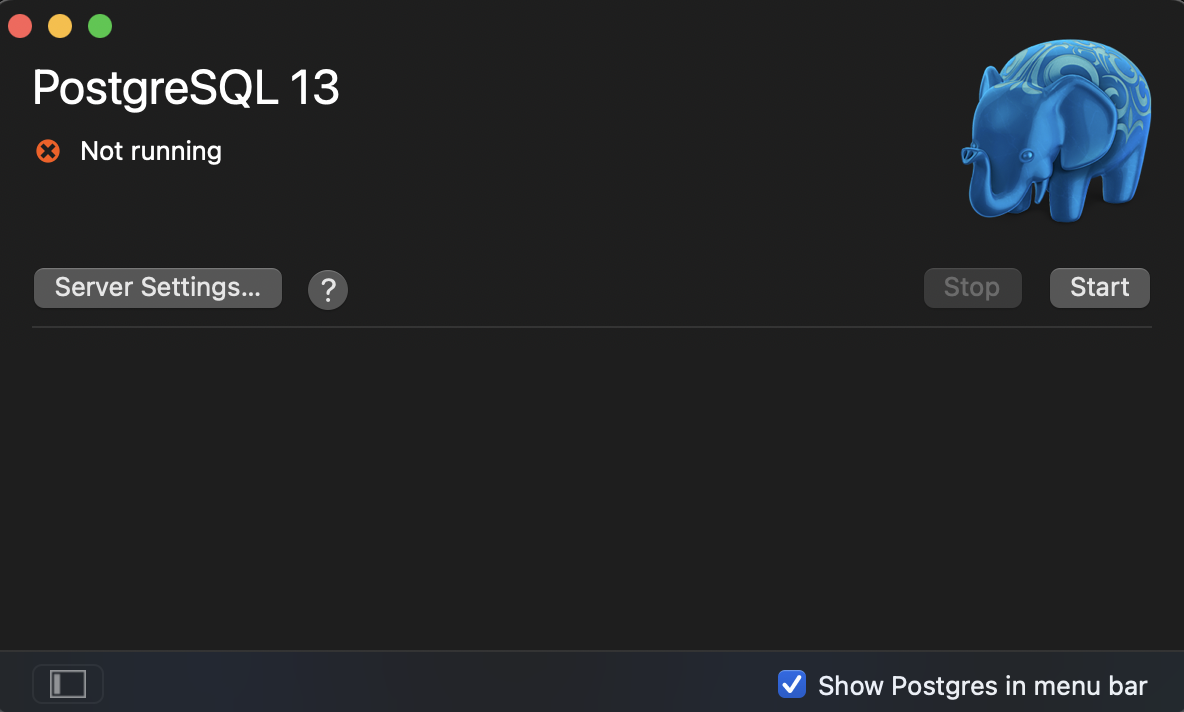
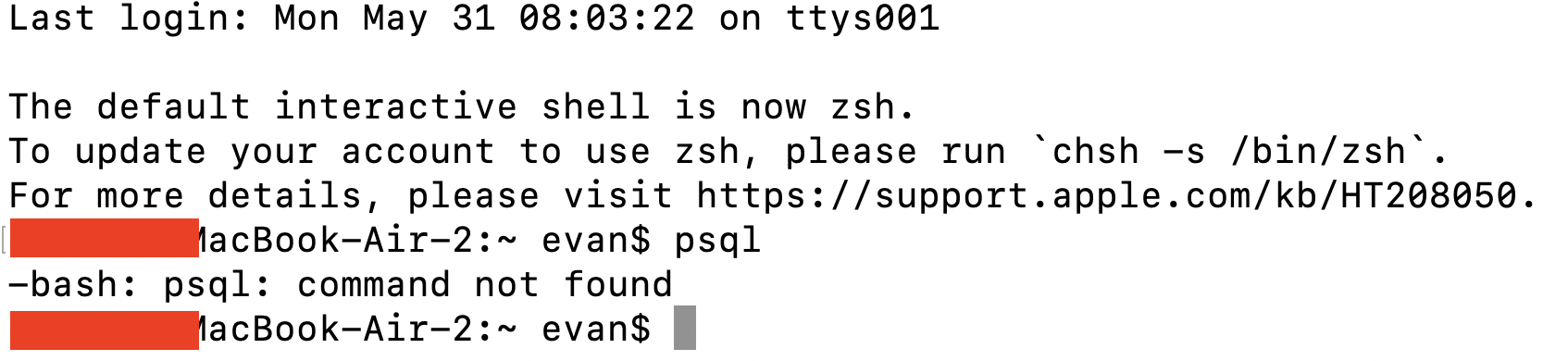
Part I. Docker and Airflow
Docker와 Airflow를 설치 및 실행한다.
필자는 가상환경을 선정하고, 그 위에 도커를 추가로 설치하였다.