강의 홍보
개요
새로운 제안
!apt update -q
!apt-get install -q openjdk-11-jdk-headless
%env JAVA_HOME "/usr/lib/jvm/java-11-openjdk-amd64"
Hit:1 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease
Get:2 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease [3,626 B]
Get:3 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]
Hit:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease
Hit:5 http://archive.ubuntu.com/ubuntu bionic InRelease
Get:6 http://archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB]
Ign:7 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease
Hit:8 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease
Hit:9 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release
Hit:10 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease
Get:11 http://archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB]
Hit:12 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease
Get:14 http://security.ubuntu.com/ubuntu bionic-security/main amd64 Packages [2,867 kB]
Get:15 http://archive.ubuntu.com/ubuntu bionic-updates/restricted amd64 Packages [1,075 kB]
Get:16 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 Packages [2,297 kB]
Get:17 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 Packages [3,302 kB]
Fetched 9,797 kB in 6s (1,534 kB/s)
Reading package lists...
Building dependency tree...
Reading state information...
49 packages can be upgraded. Run 'apt list --upgradable' to see them.
Reading package lists...
Building dependency tree...
Reading state information...
openjdk-11-jdk-headless is already the newest version (11.0.15+10-0ubuntu0.18.04.1).
The following package was automatically installed and is no longer required:
libnvidia-common-460
Use 'apt autoremove' to remove it.
0 upgraded, 0 newly installed, 0 to remove and 49 not upgraded.
env: JAVA_HOME="/usr/lib/jvm/java-11-openjdk-amd64"
- 설치가 끝난 후에는 sklearn2pmml을 설치한다.
!pip install sklearn2pmml
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting sklearn2pmml
Downloading sklearn2pmml-0.84.2.tar.gz (6.3 MB)
�[K |████████████████████████████████| 6.3 MB 5.1 MB/s
�[?25hRequirement already satisfied: joblib>=0.13.0 in /usr/local/lib/python3.7/dist-packages (from sklearn2pmml) (1.1.0)
Requirement already satisfied: scikit-learn>=0.18.0 in /usr/local/lib/python3.7/dist-packages (from sklearn2pmml) (1.0.2)
Requirement already satisfied: sklearn-pandas>=0.0.10 in /usr/local/lib/python3.7/dist-packages (from sklearn2pmml) (1.8.0)
Requirement already satisfied: numpy>=1.14.6 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.18.0->sklearn2pmml) (1.21.6)
Requirement already satisfied: scipy>=1.1.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.18.0->sklearn2pmml) (1.4.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.18.0->sklearn2pmml) (3.1.0)
Requirement already satisfied: pandas>=0.11.0 in /usr/local/lib/python3.7/dist-packages (from sklearn-pandas>=0.0.10->sklearn2pmml) (1.3.5)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.11.0->sklearn-pandas>=0.0.10->sklearn2pmml) (2022.1)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.11.0->sklearn-pandas>=0.0.10->sklearn2pmml) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas>=0.11.0->sklearn-pandas>=0.0.10->sklearn2pmml) (1.15.0)
Building wheels for collected packages: sklearn2pmml
Building wheel for sklearn2pmml (setup.py) ... �[?25l�[?25hdone
Created wheel for sklearn2pmml: filename=sklearn2pmml-0.84.2-py3-none-any.whl size=6298569 sha256=f6a564303dd11e9ce38b6c7b4ec4e8a4632499c61d3ee69f40070a1f1983ef80
Stored in directory: /root/.cache/pip/wheels/bb/e4/71/d3c8f75fae8d7f387f82099ec8cdd6b83cf1dccaeb3561c7b6
Successfully built sklearn2pmml
Installing collected packages: sklearn2pmml
Successfully installed sklearn2pmml-0.84.2
샘플 코드 작성
from sklearn.datasets import load_diabetes
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn2pmml import PMMLPipeline, sklearn2pmml
import pandas as pd
# 데이터 불러오기
df = load_diabetes()
X = pd.DataFrame(columns = df.feature_names, data = df.get('data'))
y = pd.DataFrame(columns = ['target'], data = df.get('target'))
# 데이터셋 분리하기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1, random_state=42)
# Pipeline 구축하기
pipeline = PMMLPipeline([ ('regressor', DecisionTreeRegressor()) ])
# 모형 학습 시키기
pipeline.fit(X_train, y_train)
PMMLPipeline(steps=[('regressor', DecisionTreeRegressor())])
from sklearn.metrics import mean_absolute_error
y_pred = pipeline.predict(X_test)
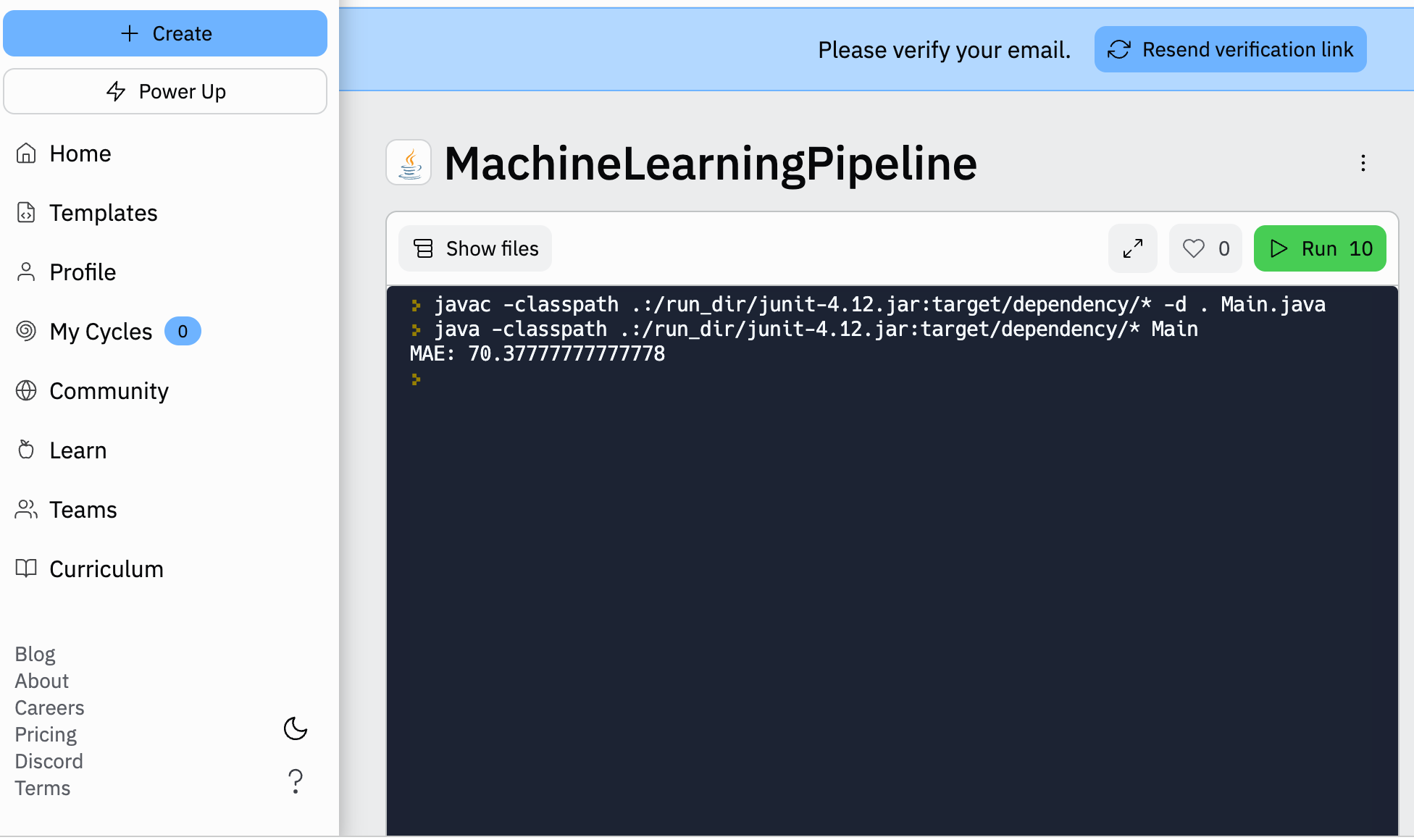
print('MAE: ', mean_absolute_error(y_pred, y_test))
MAE: 65.42222222222222
# 모델 내보내기
sklearn2pmml(pipeline, 'model.pmml', with_repr = True)
Scikit-Learn Model into JAVA
import org.pmml4s.model.Model;
import java.util.*;
public class Main {
private final Model model = Model.fromFile(Main.class.getClassLoader().getResource("model.pmml").getFile());
public Double getRegressionValue(Map<String, Double> values) {
Object[] valuesMap = Arrays.stream(model.inputNames())
.map(values::get)
.toArray();
Object[] result = model.predict(valuesMap);
return (Double) result[0];
}
public static void main(String[] args) {
Main main = new Main();
Map<String, Double> values = Map.of(
"age", 20d,
"sex", 1d,
"bmi", -100d,
"bp", -200d,
"s1", 1d,
"s2", 2d,
"s3", 3d,
"s4", 4d,
"s5", 5d,
"s6", 6d
);
double predicted = main.getRegressionValue(values);
System.out.println(predicted);
}
}