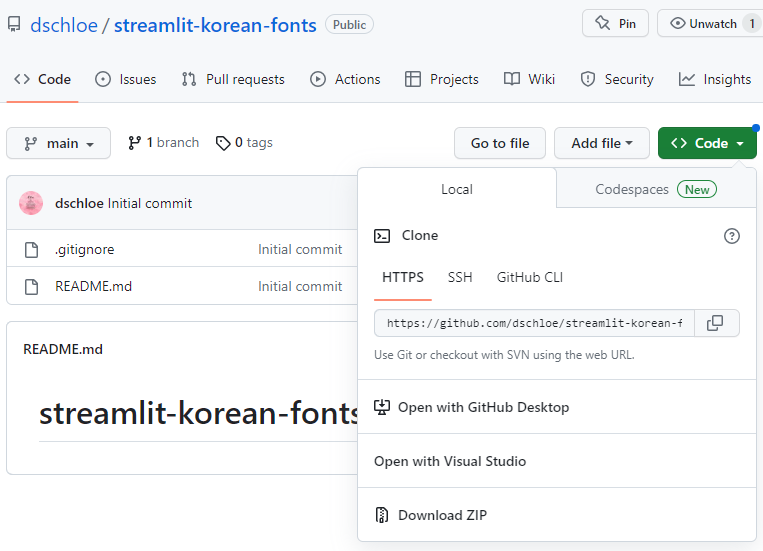
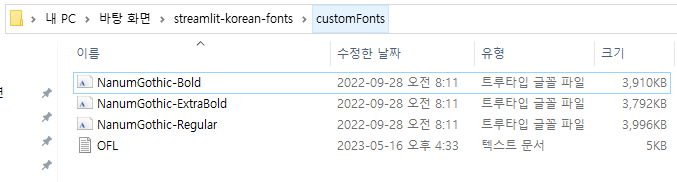
2023년 상반기 결산 - 좋은 인연, 박사학위, 자격증, 출판, 유럽여행
개요
- 블로그를 3년간 운영하면서 회고 또는 결산하는 글을 써본적은 없었다.
- 요즘에 역 시차적응 때문인지.. 최근 중요한 결정을 내린 후폭풍인지.. 새벽에 자주 잠이 깨는데, 일어난 김에 몇가지 회고의 글을 남겨보려고 한다. (글쓰는 현재 지금 시각 새벽 2시다..)
좋은 인연
상반기에도 좋은 인연이 생겼다.
- 수많은 학생들, 새로운 기회의 확장, 새로운 학교 및 새로운 과정에서의 여러 만남들
- 2개 기관은 작년에 이어서 진행한 건, 1개 기관은 신규로 진행한 건
- 강의 평가가 모두 좋게 나와서 감사할 뿐이다.
- 취업준비생 및 재직자 대상으로 약 100여명 넘는 사람들을 만난 듯 하다.
- 모두 원하는 일과 취업 잘되기를 기도 및 소망한다.
- 과거 3년전에 만났던 수강생도 최근에 결혼을 했다. 결혼하거든 연락 꼭 주세요 ㅎㅎ
- 수많은 학생들, 새로운 기회의 확장, 새로운 학교 및 새로운 과정에서의 여러 만남들
상반기 가장 좋은 인연은 공저자
Sara를 만난 것이다.