강의 홍보
1. 개요
- 기존 웹크롤링은 주로 코드에 기반한 소개가 주를 이루었음
- 본 장에서는 가급적 사용자 기준에 맞춰서 뉴스 URL만 입력하면 댓글 수집할 수 있는 기능 소개함
2. 라이브러리
- 크롤링 및 대시보드 작업을 위한 필수 라이브러리는 다음과 같음 (requirements.txt)
colorama==0.4.4
dash==1.21.0
gunicorn==20.1.0
numpy==1.19.4
pandas==1.2.0
beautifulsoup4==4.9.3
openpyxl==3.0.7
requests==2.26.0
- 위 파일을 프로젝트의 가장 최상단에 위치시켜 놓는다.
- 설치 진행 시에는
pip install -r requirements.txt 해도 좋고, 아니면 개별적으로 설치를 해도 좋다.
3. 코드 설명
- 본장에서는 디테일한 코드 설명은 넘어가도록 한다.
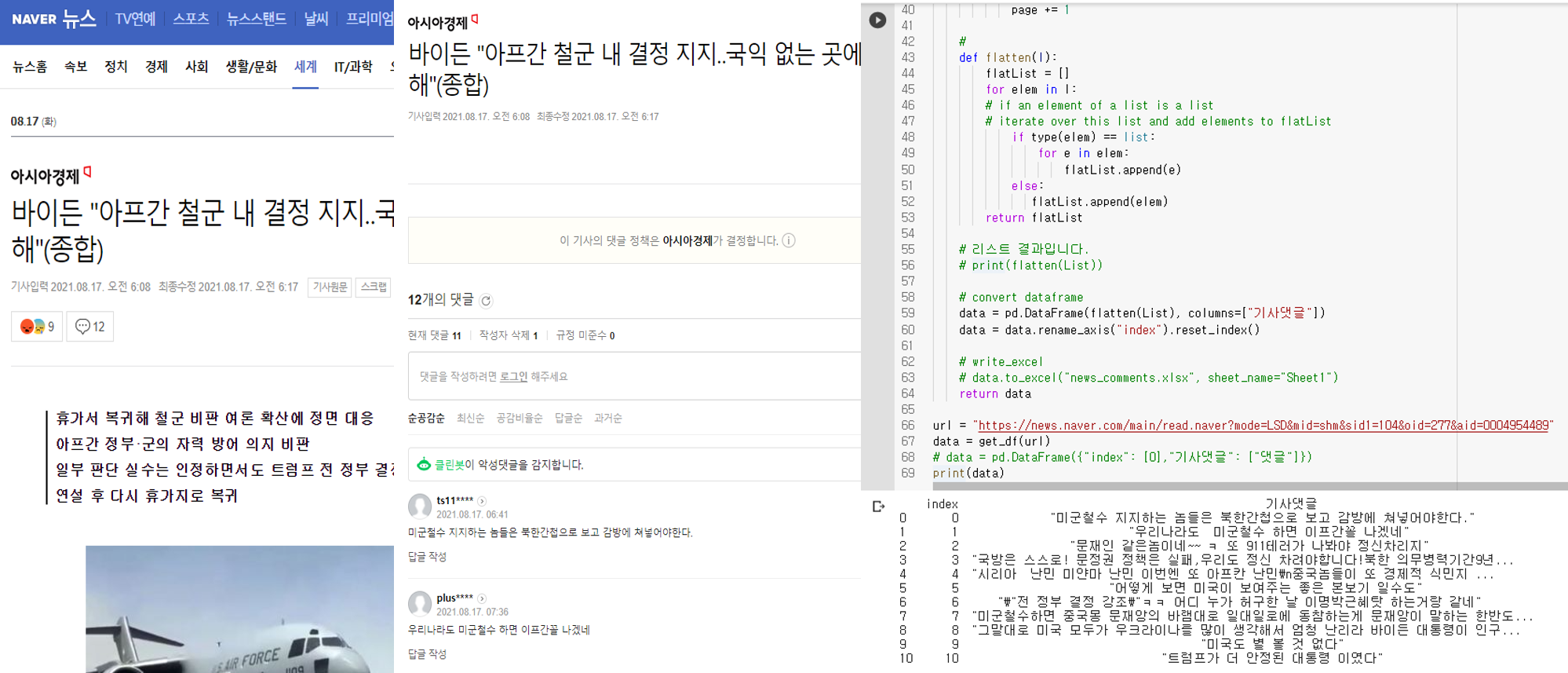
(1) 크롤링 코드
# 크롤링 라이브러리
from bs4 import BeautifulSoup
import requests
import re
# 데이터프레임
import pandas as pd
# 샘플 URL을 적용한다.
url = "https://news.naver.com/main/read.naver?mode=LSD&mid=shm&sid1=100&oid=022&aid=0003609357"
def get_df(url):
# 댓글을 달 빈 리스트를 생성합니다.
List = []
url = url
oid = url.split("oid=")[1].split("&")[0]
aid = url.split("aid=")[1]
page = 1
header = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"referer": url,
}
while True:
c_url = "https://apis.naver.com/commentBox/cbox/web_neo_list_jsonp.json?ticket=news&templateId=default_society&pool=cbox5&_callback=jQuery1707138182064460843_1523512042464&lang=ko&country=&objectId=news" + oid + "%2C" + aid + "&categoryId=&pageSize=20&indexSize=10&groupId=&listType=OBJECT&pageType=more&page=" + str(
page) + "&refresh=false&sort=FAVORITE"
# 파싱하는 단계입니다.
r = requests.get(c_url, headers=header)
cont = BeautifulSoup(r.content, "html.parser")
total_comm = str(cont).split('comment":')[1].split(",")[0]
match = re.findall('"contents":([^\*]*),"userIdNo"', str(cont))
# 댓글을 리스트에 중첩합니다.
List.append(match)
# 한번에 댓글이 20개씩 보이기 때문에 한 페이지씩 몽땅 댓글을 긁어 옵니다.
if int(total_comm) <= ((page) * 20):
break
else:
page += 1
#
def flatten(l):
flatList = []
for elem in l:
# if an element of a list is a list
# iterate over this list and add elements to flatList
if type(elem) == list:
for e in elem:
flatList.append(e)
else:
flatList.append(elem)
return flatList
# 리스트 결과입니다.
# print(flatten(List))
# convert dataframe
data = pd.DataFrame(flatten(List), columns=["기사댓글"])
data = data.rename_axis("index").reset_index()
# write_excel
# data.to_excel("news_comments.xlsx", sheet_name="Sheet1")
return data
# data = get_df(url) # URL 테스트 시, 실행
data = pd.DataFrame({"index": [0], "기사댓글": ["댓글"]}) # 앱 배포시 실행
# print(data.head())
- 중간에 주석처리 한 것을 풀면 된다.
- 해당 코드는 app.py 또는 일반적인 주피터 노트북, 구글 코랩에서 실행해도 된다.
- 수집된 댓글을 확인해보니, 중간에 삭제된 글은 댓글 수집 시, 제외되는 것을 확인할 수 있다.