개요 작업 2유형(머신러닝)을 보다 쉽게 대비할 수 있도록 튜토리얼을 준비했습니다. 핵심 키워드 : Python 머신러닝은 pipeline 코드로 기억하자 본 코드는 구글 코랩에서 작성하였습니다. 유투브 유투브에서 강의 영상을 시청할 수 있습니다. (구독과 좋아요)VIDEO
데이터 출처 구글 드라이브 연동 데이터를 가져오기 위해 구글 드라이브와 연동합니다. from google.colab import drive
drive. mount("/content/drive" )
Mounted at /content/drive
라이브러리 불러오기 아래 라이브러리들을 모두 암기하시기를 바랍니다. import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
## from sklearn.metrics import make_scorer, mean_squared_error
## from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier
데이터 가져오기 구글 드라이브에서 데이터를 가져옵니다. 시험장에서는 데이터 가져오기는 자동으로 설정이 되어 있습니다. DATA_PATH = '/content/drive/MyDrive/Colab Notebooks/2024/빅분기/[Dataset] 작업형 제2유형/'
X_test = pd. read_csv(DATA_PATH + "X_test.csv" , encoding= 'cp949' )
X_train = pd. read_csv(DATA_PATH + "X_train.csv" , encoding= 'cp949' )
y_train = pd. read_csv(DATA_PATH + "y_train.csv" , encoding= 'cp949' )
print(X_test. shape, X_train. shape, y_train. shape)
(2482, 10) (3500, 10) (3500, 2)
데이터 정보 확인하기 cust_id gender
0 0 0
1 1 0
2 2 1
문자열과 숫자 데이터가 적절하게 섞인 것을 확인할 수 있다. cust_id 총구매액 최대구매액 환불금액 주구매상품 주구매지점 내점일수 내점당구매건수 \
0 0 68282840 11264000 6860000.0 기타 강남점 19 3.894737
1 1 2136000 2136000 300000.0 스포츠 잠실점 2 1.500000
2 2 3197000 1639000 NaN 남성 캐주얼 관악점 2 2.000000
주말방문비율 구매주기
0 0.527027 17
1 0.000000 1
2 0.000000 1
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3500 entries, 0 to 3499
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cust_id 3500 non-null int64
1 총구매액 3500 non-null int64
2 최대구매액 3500 non-null int64
3 환불금액 1205 non-null float64
4 주구매상품 3500 non-null object
5 주구매지점 3500 non-null object
6 내점일수 3500 non-null int64
7 내점당구매건수 3500 non-null float64
8 주말방문비율 3500 non-null float64
9 구매주기 3500 non-null int64
dtypes: float64(3), int64(5), object(2)
memory usage: 273.6+ KB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3500 entries, 0 to 3499
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cust_id 3500 non-null int64
1 gender 3500 non-null int64
dtypes: int64(2)
memory usage: 54.8 KB
None
데이터 전처리 2회-6회 시험까지 결측치는 존재하지 않았지만, 언제든지 결측치 처리 문제는 나올 수 있음. 결측치를 처리할 때는 fillna() 메서드를 사용한다.숫자는 각 컬럼의 평균대치, 문자는 최빈도값 대치를 한다. cust_id 0
총구매액 0
최대구매액 0
환불금액 2295
주구매상품 0
주구매지점 0
내점일수 0
내점당구매건수 0
주말방문비율 0
구매주기 0
dtype: int64
여기에서는 특정 컬럼의 결측치가 많아서 삭제 한다. X_train = X_train. drop("환불금액" , axis= 1 )
X_train. isnull(). sum()
cust_id 0
총구매액 0
최대구매액 0
주구매상품 0
주구매지점 0
내점일수 0
내점당구매건수 0
주말방문비율 0
구매주기 0
dtype: int64
X_train['주구매상품' ]. value_counts()
기타 595
가공식품 546
농산물 339
화장품 264
시티웨어 213
디자이너 193
수산품 153
캐주얼 101
명품 100
섬유잡화 98
골프 82
스포츠 69
일용잡화 64
모피/피혁 57
육류 57
남성 캐주얼 55
구두 54
건강식품 47
차/커피 44
피혁잡화 40
아동 40
축산가공 35
주방용품 32
셔츠 30
젓갈/반찬 29
주방가전 26
트래디셔널 23
남성정장 22
생활잡화 15
주류 14
가구 10
커리어 9
대형가전 8
란제리/내의 8
식기 7
액세서리 5
침구/수예 4
통신/컴퓨터 3
보석 3
남성 트랜디 2
소형가전 2
악기 2
Name: 주구매상품, dtype: int64
X_train['주구매지점' ]. value_counts()
본 점 1077
잠실점 474
분당점 436
부산본점 245
영등포점 241
일산점 198
강남점 145
광주점 114
노원점 90
청량리점 86
대전점 70
미아점 69
부평점 57
동래점 49
관악점 46
인천점 34
안양점 29
포항점 11
대구점 7
센텀시티점 6
울산점 6
전주점 5
창원점 4
상인점 1
Name: 주구매지점, dtype: int64
컬럼 분리 X_train_id = X_train. pop("cust_id" )
print(X_train. info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3500 entries, 0 to 3499
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 총구매액 3500 non-null int64
1 최대구매액 3500 non-null int64
2 주구매상품 3500 non-null object
3 주구매지점 3500 non-null object
4 내점일수 3500 non-null int64
5 내점당구매건수 3500 non-null float64
6 주말방문비율 3500 non-null float64
7 구매주기 3500 non-null int64
dtypes: float64(2), int64(4), object(2)
memory usage: 218.9+ KB
None
X_test_id = X_test. pop("cust_id" )
print(X_test. info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2482 entries, 0 to 2481
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 총구매액 2482 non-null int64
1 최대구매액 2482 non-null int64
2 환불금액 871 non-null float64
3 주구매상품 2482 non-null object
4 주구매지점 2482 non-null object
5 내점일수 2482 non-null int64
6 내점당구매건수 2482 non-null float64
7 주말방문비율 2482 non-null float64
8 구매주기 2482 non-null int64
dtypes: float64(3), int64(4), object(2)
memory usage: 174.6+ KB
None
cat_cols = X_train. select_dtypes(exclude = np. number). columns. tolist()
num_cols = X_train. select_dtypes(include = np. number). columns. tolist()
print(cat_cols)
print(num_cols)
['주구매상품', '주구매지점']
['총구매액', '최대구매액', '내점일수', '내점당구매건수', '주말방문비율', '구매주기']
데이터셋 분리 데이터셋 분리의 기본 원칙은 최대한 데이터의 분포가 일정해야 한다는 것이다. 평소 분석을 할 때는 하나씩 다 확인을 해야하지만, 시험장에서는 분류모델이 문제일 경우에는 y_train 데이터를 기준으로 층화추출을 한다. X_tr, X_val, y_tr, y_val = train_test_split(
X_train, y_train['gender' ],
stratify = y_train['gender' ],
test_size= 0.3 ,
random_state= 42
)
X_tr. shape, X_val. shape, y_tr. shape, y_val. shape
((2450, 8), (1050, 8), (2450,), (1050,))
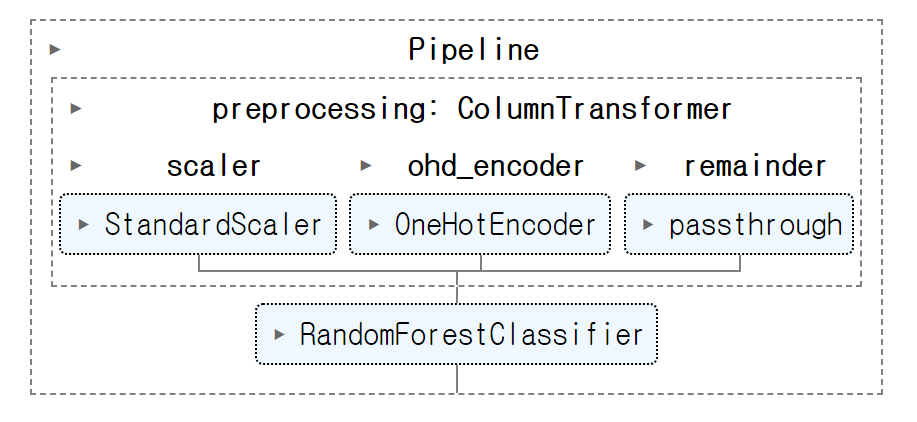
모델 만들기 모델 만들기 1 - 입문자 기본 모델만 만들고 싶다면 아래 코드만 기억한다. column_transformer = ColumnTransformer([
("scaler" , StandardScaler(), num_cols),
("ohd_encoder" , OneHotEncoder(handle_unknown= 'ignore' ), cat_cols)
], remainder= "passthrough" )
pipeline = Pipeline([
("preprocessing" , column_transformer),
("clf" , RandomForestClassifier(random_state= 42 ))
])
pipeline. fit(X_tr, y_tr)